{"title":"缩小语言模型的巨大差异:多语言教育内容的技能标记","authors":"Yerin Kwak, Zachary A. Pardos","doi":"10.1111/bjet.13465","DOIUrl":null,"url":null,"abstract":"<div>\n \n \n <section>\n \n <p>The adoption of large language models (LLMs) in education holds much promise. However, like many technological innovations before them, adoption and access can often be inequitable from the outset, creating more divides than they bridge. In this paper, we explore the magnitude of the country and language divide in the leading open-source and proprietary LLMs with respect to knowledge of K-12 taxonomies in a variety of countries and their performance on tagging problem content with the appropriate skill from a taxonomy, an important task for aligning open educational resources and tutoring content with state curricula. We also experiment with approaches to narrowing the performance divide by enhancing LLM skill tagging performance across four countries (the USA, Ireland, South Korea and India–Maharashtra) for more equitable outcomes. We observe considerable performance disparities not only with non-English languages but with English and non-US taxonomies. Our findings demonstrate that fine-tuning GPT-3.5 with a few labelled examples can improve its proficiency in tagging problems with relevant skills or standards, even for countries and languages that are underrepresented during training. Furthermore, the fine-tuning results show the potential viability of GPT as a multilingual skill classifier. Using both an open-source model, Llama2-13B, and a closed-source model, GPT-3.5, we also observe large disparities in tagging performance between the two and find that fine-tuning and skill information in the prompt improve both, but the closed-source model improves to a much greater extent. Our study contributes to the first empirical results on mitigating disparities across countries and languages with LLMs in an educational context.</p>\n </section>\n \n <section>\n \n <div>\n \n <div>\n \n <h3>Practitioner notes</h3>\n <p>What is already known about this topic\n\n </p><ul>\n \n <li>Recent advances in generative AI have led to increased applications of LLMs in education, offering diverse opportunities.</li>\n \n <li>LLMs excel predominantly in English and exhibit a bias towards the US context.</li>\n \n <li>Automated content tagging has been studied using English-language content and taxonomies.</li>\n </ul>\n <p>What this paper adds\n\n </p><ul>\n \n <li>Investigates the country and language disparities in LLMs concerning knowledge of educational taxonomies and their performance in tagging content.</li>\n \n <li>Presents the first empirical findings on addressing disparities in LLM performance across countries and languages within an educational context.</li>\n \n <li>Improves GPT-3.5's tagging accuracy through fine-tuning, even for non-US countries, starting from zero accuracy.</li>\n \n <li>Extends automated content tagging to non-English languages using both open-source and closed-source LLMs.</li>\n </ul>\n <p>Implications for practice and/or policy\n\n </p><ul>\n \n <li>Underscores the importance of considering the performance generalizability of LLMs to languages other than English.</li>\n \n <li>Highlights the potential viability of ChatGPT as a skill tagging classifier across countries.</li>\n </ul>\n </div>\n </div>\n </section>\n </div>","PeriodicalId":48315,"journal":{"name":"British Journal of Educational Technology","volume":"55 5","pages":"2039-2057"},"PeriodicalIF":6.7000,"publicationDate":"2024-05-08","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1111/bjet.13465","citationCount":"0","resultStr":"{\"title\":\"Bridging large language model disparities: Skill tagging of multilingual educational content\",\"authors\":\"Yerin Kwak, Zachary A. Pardos\",\"doi\":\"10.1111/bjet.13465\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div>\\n \\n \\n <section>\\n \\n <p>The adoption of large language models (LLMs) in education holds much promise. However, like many technological innovations before them, adoption and access can often be inequitable from the outset, creating more divides than they bridge. In this paper, we explore the magnitude of the country and language divide in the leading open-source and proprietary LLMs with respect to knowledge of K-12 taxonomies in a variety of countries and their performance on tagging problem content with the appropriate skill from a taxonomy, an important task for aligning open educational resources and tutoring content with state curricula. We also experiment with approaches to narrowing the performance divide by enhancing LLM skill tagging performance across four countries (the USA, Ireland, South Korea and India–Maharashtra) for more equitable outcomes. We observe considerable performance disparities not only with non-English languages but with English and non-US taxonomies. Our findings demonstrate that fine-tuning GPT-3.5 with a few labelled examples can improve its proficiency in tagging problems with relevant skills or standards, even for countries and languages that are underrepresented during training. Furthermore, the fine-tuning results show the potential viability of GPT as a multilingual skill classifier. Using both an open-source model, Llama2-13B, and a closed-source model, GPT-3.5, we also observe large disparities in tagging performance between the two and find that fine-tuning and skill information in the prompt improve both, but the closed-source model improves to a much greater extent. Our study contributes to the first empirical results on mitigating disparities across countries and languages with LLMs in an educational context.</p>\\n </section>\\n \\n <section>\\n \\n <div>\\n \\n <div>\\n \\n <h3>Practitioner notes</h3>\\n <p>What is already known about this topic\\n\\n </p><ul>\\n \\n <li>Recent advances in generative AI have led to increased applications of LLMs in education, offering diverse opportunities.</li>\\n \\n <li>LLMs excel predominantly in English and exhibit a bias towards the US context.</li>\\n \\n <li>Automated content tagging has been studied using English-language content and taxonomies.</li>\\n </ul>\\n <p>What this paper adds\\n\\n </p><ul>\\n \\n <li>Investigates the country and language disparities in LLMs concerning knowledge of educational taxonomies and their performance in tagging content.</li>\\n \\n <li>Presents the first empirical findings on addressing disparities in LLM performance across countries and languages within an educational context.</li>\\n \\n <li>Improves GPT-3.5's tagging accuracy through fine-tuning, even for non-US countries, starting from zero accuracy.</li>\\n \\n <li>Extends automated content tagging to non-English languages using both open-source and closed-source LLMs.</li>\\n </ul>\\n <p>Implications for practice and/or policy\\n\\n </p><ul>\\n \\n <li>Underscores the importance of considering the performance generalizability of LLMs to languages other than English.</li>\\n \\n <li>Highlights the potential viability of ChatGPT as a skill tagging classifier across countries.</li>\\n </ul>\\n </div>\\n </div>\\n </section>\\n </div>\",\"PeriodicalId\":48315,\"journal\":{\"name\":\"British Journal of Educational Technology\",\"volume\":\"55 5\",\"pages\":\"2039-2057\"},\"PeriodicalIF\":6.7000,\"publicationDate\":\"2024-05-08\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://onlinelibrary.wiley.com/doi/epdf/10.1111/bjet.13465\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"British Journal of Educational Technology\",\"FirstCategoryId\":\"95\",\"ListUrlMain\":\"https://onlinelibrary.wiley.com/doi/10.1111/bjet.13465\",\"RegionNum\":1,\"RegionCategory\":\"教育学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"EDUCATION & EDUCATIONAL RESEARCH\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"British Journal of Educational Technology","FirstCategoryId":"95","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1111/bjet.13465","RegionNum":1,"RegionCategory":"教育学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"EDUCATION & EDUCATIONAL RESEARCH","Score":null,"Total":0}
Bridging large language model disparities: Skill tagging of multilingual educational content
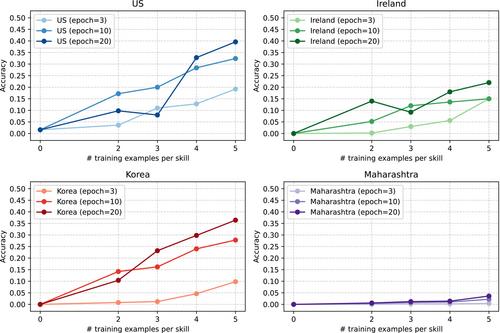
The adoption of large language models (LLMs) in education holds much promise. However, like many technological innovations before them, adoption and access can often be inequitable from the outset, creating more divides than they bridge. In this paper, we explore the magnitude of the country and language divide in the leading open-source and proprietary LLMs with respect to knowledge of K-12 taxonomies in a variety of countries and their performance on tagging problem content with the appropriate skill from a taxonomy, an important task for aligning open educational resources and tutoring content with state curricula. We also experiment with approaches to narrowing the performance divide by enhancing LLM skill tagging performance across four countries (the USA, Ireland, South Korea and India–Maharashtra) for more equitable outcomes. We observe considerable performance disparities not only with non-English languages but with English and non-US taxonomies. Our findings demonstrate that fine-tuning GPT-3.5 with a few labelled examples can improve its proficiency in tagging problems with relevant skills or standards, even for countries and languages that are underrepresented during training. Furthermore, the fine-tuning results show the potential viability of GPT as a multilingual skill classifier. Using both an open-source model, Llama2-13B, and a closed-source model, GPT-3.5, we also observe large disparities in tagging performance between the two and find that fine-tuning and skill information in the prompt improve both, but the closed-source model improves to a much greater extent. Our study contributes to the first empirical results on mitigating disparities across countries and languages with LLMs in an educational context.
Practitioner notes
What is already known about this topic
Recent advances in generative AI have led to increased applications of LLMs in education, offering diverse opportunities.
LLMs excel predominantly in English and exhibit a bias towards the US context.
Automated content tagging has been studied using English-language content and taxonomies.
What this paper adds
Investigates the country and language disparities in LLMs concerning knowledge of educational taxonomies and their performance in tagging content.
Presents the first empirical findings on addressing disparities in LLM performance across countries and languages within an educational context.
Improves GPT-3.5's tagging accuracy through fine-tuning, even for non-US countries, starting from zero accuracy.
Extends automated content tagging to non-English languages using both open-source and closed-source LLMs.
Implications for practice and/or policy
Underscores the importance of considering the performance generalizability of LLMs to languages other than English.
Highlights the potential viability of ChatGPT as a skill tagging classifier across countries.
期刊介绍:
BJET is a primary source for academics and professionals in the fields of digital educational and training technology throughout the world. The Journal is published by Wiley on behalf of The British Educational Research Association (BERA). It publishes theoretical perspectives, methodological developments and high quality empirical research that demonstrate whether and how applications of instructional/educational technology systems, networks, tools and resources lead to improvements in formal and non-formal education at all levels, from early years through to higher, technical and vocational education, professional development and corporate training.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


