Muhammad Salman, Armin Haller, Sergio J. Rodríguez Méndez, Usman Naseem
{"title":"Doc-KG:利用维基数据从非结构化文档到知识图谱的构建、识别和验证","authors":"Muhammad Salman, Armin Haller, Sergio J. Rodríguez Méndez, Usman Naseem","doi":"10.1111/exsy.13617","DOIUrl":null,"url":null,"abstract":"<p>The exponential growth of textual data in the digital era underlines the pivotal role of Knowledge Graphs (KGs) in effectively storing, managing, and utilizing this vast reservoir of information. Despite the copious amounts of text available on the web, a significant portion remains unstructured, presenting a substantial barrier to the automatic construction and enrichment of KGs. To address this issue, we introduce an enhanced Doc-KG model, a sophisticated approach designed to transform unstructured documents into structured knowledge by generating local KGs and mapping these to a target KG, such as Wikidata. Our model innovatively leverages syntactic information to extract entities and predicates efficiently, integrating them into triples with improved accuracy. Furthermore, the Doc-KG model's performance surpasses existing methodologies by utilizing advanced algorithms for both the extraction of triples and their subsequent identification within Wikidata, employing Wikidata's Unified Resource Identifiers for precise mapping. This dual capability not only facilitates the construction of KGs directly from unstructured texts but also enhances the process of identifying triple mentions within Wikidata, marking a significant advancement in the domain. Our comprehensive evaluation, conducted using the renowned WebNLG benchmark dataset, reveals the Doc-KG model's superior performance in triple extraction tasks, achieving an unprecedented accuracy rate of 86.64%. In the domain of triple identification, the model demonstrated exceptional efficacy by mapping 61.35% of the local KG to Wikidata, thereby contributing 38.65% of novel information for KG enrichment. A qualitative analysis based on a manually annotated dataset further confirms the model's excellence, outshining baseline methods in extracting high-fidelity triples. This research embodies a novel contribution to the field of knowledge extraction and management, offering a robust framework for the semantic structuring of unstructured data and paving the way for the next generation of KGs.</p>","PeriodicalId":51053,"journal":{"name":"Expert Systems","volume":"41 9","pages":""},"PeriodicalIF":3.0000,"publicationDate":"2024-05-08","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1111/exsy.13617","citationCount":"0","resultStr":"{\"title\":\"Doc-KG: Unstructured documents to knowledge graph construction, identification and validation with Wikidata\",\"authors\":\"Muhammad Salman, Armin Haller, Sergio J. Rodríguez Méndez, Usman Naseem\",\"doi\":\"10.1111/exsy.13617\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>The exponential growth of textual data in the digital era underlines the pivotal role of Knowledge Graphs (KGs) in effectively storing, managing, and utilizing this vast reservoir of information. Despite the copious amounts of text available on the web, a significant portion remains unstructured, presenting a substantial barrier to the automatic construction and enrichment of KGs. To address this issue, we introduce an enhanced Doc-KG model, a sophisticated approach designed to transform unstructured documents into structured knowledge by generating local KGs and mapping these to a target KG, such as Wikidata. Our model innovatively leverages syntactic information to extract entities and predicates efficiently, integrating them into triples with improved accuracy. Furthermore, the Doc-KG model's performance surpasses existing methodologies by utilizing advanced algorithms for both the extraction of triples and their subsequent identification within Wikidata, employing Wikidata's Unified Resource Identifiers for precise mapping. This dual capability not only facilitates the construction of KGs directly from unstructured texts but also enhances the process of identifying triple mentions within Wikidata, marking a significant advancement in the domain. Our comprehensive evaluation, conducted using the renowned WebNLG benchmark dataset, reveals the Doc-KG model's superior performance in triple extraction tasks, achieving an unprecedented accuracy rate of 86.64%. In the domain of triple identification, the model demonstrated exceptional efficacy by mapping 61.35% of the local KG to Wikidata, thereby contributing 38.65% of novel information for KG enrichment. A qualitative analysis based on a manually annotated dataset further confirms the model's excellence, outshining baseline methods in extracting high-fidelity triples. This research embodies a novel contribution to the field of knowledge extraction and management, offering a robust framework for the semantic structuring of unstructured data and paving the way for the next generation of KGs.</p>\",\"PeriodicalId\":51053,\"journal\":{\"name\":\"Expert Systems\",\"volume\":\"41 9\",\"pages\":\"\"},\"PeriodicalIF\":3.0000,\"publicationDate\":\"2024-05-08\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://onlinelibrary.wiley.com/doi/epdf/10.1111/exsy.13617\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Expert Systems\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://onlinelibrary.wiley.com/doi/10.1111/exsy.13617\",\"RegionNum\":4,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Expert Systems","FirstCategoryId":"94","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1111/exsy.13617","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 0
摘要
数字时代文本数据的指数级增长凸显了知识图谱(KG)在有效存储、管理和利用这一庞大信息库方面的关键作用。尽管网络上有大量的文本,但其中很大一部分仍然是非结构化的,这对自动构建和丰富知识图谱构成了巨大的障碍。为了解决这个问题,我们引入了一个增强的 Doc-KG 模型,这是一种复杂的方法,旨在通过生成本地 KG 并将其映射到目标 KG(如 Wikidata),将非结构化文档转化为结构化知识。我们的模型创新性地利用语法信息来高效提取实体和谓词,并将它们整合到三元组中,从而提高了准确性。此外,Doc-KG 模型的性能超越了现有方法,它利用先进的算法提取三元组,并随后在 Wikidata 中进行识别,采用 Wikidata 的统一资源标识符进行精确映射。这种双重能力不仅有助于直接从非结构化文本中构建KG,还增强了维基数据中三元提及的识别过程,标志着该领域的重大进步。我们使用著名的 WebNLG 基准数据集进行了全面评估,结果显示 Doc-KG 模型在三重提取任务中表现出色,准确率达到前所未有的 86.64%。在三重识别领域,该模型表现出了卓越的功效,将 61.35% 的本地 KG 映射到了 Wikidata,从而为丰富 KG 提供了 38.65% 的新信息。基于人工注释数据集的定性分析进一步证实了该模型的卓越性,在提取高保真三元组方面超越了基线方法。这项研究体现了对知识提取和管理领域的新贡献,为非结构化数据的语义结构化提供了一个强大的框架,并为下一代知识库铺平了道路。
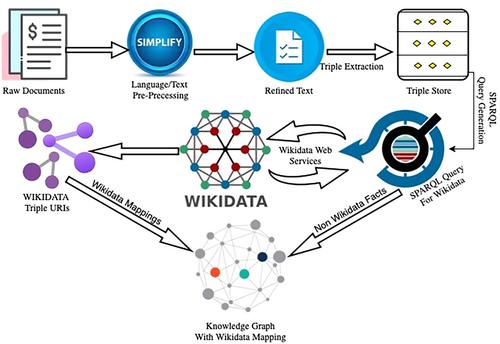
Doc-KG: Unstructured documents to knowledge graph construction, identification and validation with Wikidata
The exponential growth of textual data in the digital era underlines the pivotal role of Knowledge Graphs (KGs) in effectively storing, managing, and utilizing this vast reservoir of information. Despite the copious amounts of text available on the web, a significant portion remains unstructured, presenting a substantial barrier to the automatic construction and enrichment of KGs. To address this issue, we introduce an enhanced Doc-KG model, a sophisticated approach designed to transform unstructured documents into structured knowledge by generating local KGs and mapping these to a target KG, such as Wikidata. Our model innovatively leverages syntactic information to extract entities and predicates efficiently, integrating them into triples with improved accuracy. Furthermore, the Doc-KG model's performance surpasses existing methodologies by utilizing advanced algorithms for both the extraction of triples and their subsequent identification within Wikidata, employing Wikidata's Unified Resource Identifiers for precise mapping. This dual capability not only facilitates the construction of KGs directly from unstructured texts but also enhances the process of identifying triple mentions within Wikidata, marking a significant advancement in the domain. Our comprehensive evaluation, conducted using the renowned WebNLG benchmark dataset, reveals the Doc-KG model's superior performance in triple extraction tasks, achieving an unprecedented accuracy rate of 86.64%. In the domain of triple identification, the model demonstrated exceptional efficacy by mapping 61.35% of the local KG to Wikidata, thereby contributing 38.65% of novel information for KG enrichment. A qualitative analysis based on a manually annotated dataset further confirms the model's excellence, outshining baseline methods in extracting high-fidelity triples. This research embodies a novel contribution to the field of knowledge extraction and management, offering a robust framework for the semantic structuring of unstructured data and paving the way for the next generation of KGs.
期刊介绍:
Expert Systems: The Journal of Knowledge Engineering publishes papers dealing with all aspects of knowledge engineering, including individual methods and techniques in knowledge acquisition and representation, and their application in the construction of systems – including expert systems – based thereon. Detailed scientific evaluation is an essential part of any paper.
As well as traditional application areas, such as Software and Requirements Engineering, Human-Computer Interaction, and Artificial Intelligence, we are aiming at the new and growing markets for these technologies, such as Business, Economy, Market Research, and Medical and Health Care. The shift towards this new focus will be marked by a series of special issues covering hot and emergent topics.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


