Sinuo Deng, Lifang Wu, Ge Shi, Lehao Xing, Meng Jian, Ye Xiang, Ruihai Dong
{"title":"学习编写用于图像情感分类的多样化提示语","authors":"Sinuo Deng, Lifang Wu, Ge Shi, Lehao Xing, Meng Jian, Ye Xiang, Ruihai Dong","doi":"10.1007/s41095-023-0389-6","DOIUrl":null,"url":null,"abstract":"<p>Image emotion classification (IEC) aims to extract the abstract emotions evoked in images. Recently, language-supervised methods such as contrastive language-image pretraining (CLIP) have demonstrated superior performance in image understanding. However, the underexplored task of IEC presents three major challenges: a tremendous training objective gap between pretraining and IEC, shared suboptimal prompts, and invariant prompts for all instances. In this study, we propose a general framework that effectively exploits the language-supervised CLIP method for the IEC task. First, a prompt-tuning method that mimics the pretraining objective of CLIP is introduced, to exploit the rich image and text semantics associated with CLIP. Subsequently, instance-specific prompts are automatically composed, conditioning them on the categories and image content of instances, diversifying the prompts, and thus avoiding suboptimal problems. Evaluations on six widely used affective datasets show that the proposed method significantly outperforms state-of-the-art methods (up to 9.29% accuracy gain on the EmotionROI dataset) on IEC tasks with only a few trained parameters. The code is publicly available at https://github.com/dsn0w/PT-DPC/for research purposes.\n</p>","PeriodicalId":37301,"journal":{"name":"Computational Visual Media","volume":"44 1","pages":""},"PeriodicalIF":18.3000,"publicationDate":"2024-04-26","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Learning to compose diversified prompts for image emotion classification\",\"authors\":\"Sinuo Deng, Lifang Wu, Ge Shi, Lehao Xing, Meng Jian, Ye Xiang, Ruihai Dong\",\"doi\":\"10.1007/s41095-023-0389-6\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Image emotion classification (IEC) aims to extract the abstract emotions evoked in images. Recently, language-supervised methods such as contrastive language-image pretraining (CLIP) have demonstrated superior performance in image understanding. However, the underexplored task of IEC presents three major challenges: a tremendous training objective gap between pretraining and IEC, shared suboptimal prompts, and invariant prompts for all instances. In this study, we propose a general framework that effectively exploits the language-supervised CLIP method for the IEC task. First, a prompt-tuning method that mimics the pretraining objective of CLIP is introduced, to exploit the rich image and text semantics associated with CLIP. Subsequently, instance-specific prompts are automatically composed, conditioning them on the categories and image content of instances, diversifying the prompts, and thus avoiding suboptimal problems. Evaluations on six widely used affective datasets show that the proposed method significantly outperforms state-of-the-art methods (up to 9.29% accuracy gain on the EmotionROI dataset) on IEC tasks with only a few trained parameters. The code is publicly available at https://github.com/dsn0w/PT-DPC/for research purposes.\\n</p>\",\"PeriodicalId\":37301,\"journal\":{\"name\":\"Computational Visual Media\",\"volume\":\"44 1\",\"pages\":\"\"},\"PeriodicalIF\":18.3000,\"publicationDate\":\"2024-04-26\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Computational Visual Media\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1007/s41095-023-0389-6\",\"RegionNum\":3,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"COMPUTER SCIENCE, SOFTWARE ENGINEERING\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Computational Visual Media","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s41095-023-0389-6","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, SOFTWARE ENGINEERING","Score":null,"Total":0}
Learning to compose diversified prompts for image emotion classification
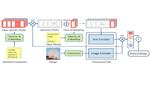
Image emotion classification (IEC) aims to extract the abstract emotions evoked in images. Recently, language-supervised methods such as contrastive language-image pretraining (CLIP) have demonstrated superior performance in image understanding. However, the underexplored task of IEC presents three major challenges: a tremendous training objective gap between pretraining and IEC, shared suboptimal prompts, and invariant prompts for all instances. In this study, we propose a general framework that effectively exploits the language-supervised CLIP method for the IEC task. First, a prompt-tuning method that mimics the pretraining objective of CLIP is introduced, to exploit the rich image and text semantics associated with CLIP. Subsequently, instance-specific prompts are automatically composed, conditioning them on the categories and image content of instances, diversifying the prompts, and thus avoiding suboptimal problems. Evaluations on six widely used affective datasets show that the proposed method significantly outperforms state-of-the-art methods (up to 9.29% accuracy gain on the EmotionROI dataset) on IEC tasks with only a few trained parameters. The code is publicly available at https://github.com/dsn0w/PT-DPC/for research purposes.
期刊介绍:
Computational Visual Media is a peer-reviewed open access journal. It publishes original high-quality research papers and significant review articles on novel ideas, methods, and systems relevant to visual media.
Computational Visual Media publishes articles that focus on, but are not limited to, the following areas:
• Editing and composition of visual media
• Geometric computing for images and video
• Geometry modeling and processing
• Machine learning for visual media
• Physically based animation
• Realistic rendering
• Recognition and understanding of visual media
• Visual computing for robotics
• Visualization and visual analytics
Other interdisciplinary research into visual media that combines aspects of computer graphics, computer vision, image and video processing, geometric computing, and machine learning is also within the journal''s scope.
This is an open access journal, published quarterly by Tsinghua University Press and Springer. The open access fees (article-processing charges) are fully sponsored by Tsinghua University, China. Authors can publish in the journal without any additional charges.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


