关于勃起功能障碍的常见问题:评估人工智能与专家指导的答案。
IF 2.5
3区 医学
Q2 UROLOGY & NEPHROLOGY
引用次数: 0
摘要
本研究评估了人工智能生成的勃起功能障碍常见问题回复的准确性。横向分析涉及在谷歌上搜索到的 56 个勃起功能障碍相关问题,分为九个部分:原因、诊断、治疗方案、治疗并发症、保护措施、与其他疾病的关系、治疗费用、草药治疗和预约。ChatGPT 3.5、ChatGPT 4 和 BARD 的回复由两位经验丰富的泌尿科专家使用 F1 和总体质量评分 (GQS) 对准确性、相关性和可理解性进行评估。在病因等类别上,ChatGPT 3.5 和 ChatGPT 4 的 GQS 分值高于 BARD(分别为 4.5 ± 0.54、4.5 ± 0.51、3.15 ± 1.01,p<0.05)。本文章由计算机程序翻译,如有差异,请以英文原文为准。

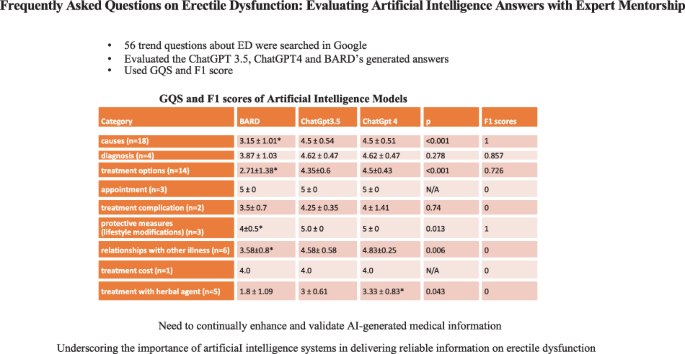
Frequently asked questions on erectile dysfunction: evaluating artificial intelligence answers with expert mentorship
The present study assessed the accuracy of artificiaI intelligence-generated responses to frequently asked questions on erectile dysfunction. A cross-sectional analysis involved 56 erectile dysfunction-related questions searched on Google, categorized into nine sections: causes, diagnosis, treatment options, treatment complications, protective measures, relationship with other illnesses, treatment costs, treatment with herbal agents, and appointments. Responses from ChatGPT 3.5, ChatGPT 4, and BARD were evaluated by two experienced urology experts using the F1 and global quality scores (GQS) for accuracy, relevance, and comprehensibility. ChatGPT 3.5 and ChatGPT 4 achieved higher GQS than BARD in categories such as causes (4.5 ± 0.54, 4.5 ± 0.51, 3.15 ± 1.01, respectively, p < 0.001), treatment options (4.35 ± 0.6, 4.5 ± 0.43, 2.71 ± 1.38, respectively, p < 0.001), protective measures (5.0 ± 0, 5.0 ± 0, 4 ± 0.5, respectively, p = 0.013), relationships with other illnesses (4.58 ± 0.58, 4.83 ± 0.25, 3.58 ± 0.8, respectively, p = 0.006), and treatment with herbal agents (3 ± 0.61, 3.33 ± 0.83, 1.8 ± 1.09, respectively, p = 0.043). F1 scores in categories: causes (1), diagnosis (0.857), treatment options (0.726), and protective measures (1), indicated their alignment with the guidelines. There was no significant difference between ChatGPT 3.5 and ChatGPT 4 regarding answer quality, but both outperformed BARD in the GQS. These results emphasize the need to continually enhance and validate AI-generated medical information, underscoring the importance of artificiaI intelligence systems in delivering reliable information on erectile dysfunction.
求助全文
通过发布文献求助,成功后即可免费获取论文全文。
去求助
来源期刊

International Journal of Impotence Research
医学-泌尿学与肾脏学
CiteScore
4.90
自引率
19.20%
发文量
140
审稿时长
>12 weeks
期刊介绍:
International Journal of Impotence Research: The Journal of Sexual Medicine addresses sexual medicine for both genders as an interdisciplinary field. This includes basic science researchers, urologists, endocrinologists, cardiologists, family practitioners, gynecologists, internists, neurologists, psychiatrists, psychologists, radiologists and other health care clinicians.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


