Stefano Alessandrini, Scott Meech, Will Cheng, Christopher Rozoff, Rajesh Kumar
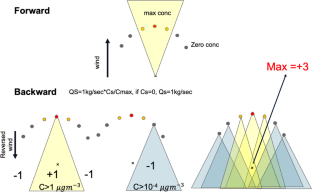
{"title":"比较源项估算的机器学习和逆向建模方法","authors":"Stefano Alessandrini, Scott Meech, Will Cheng, Christopher Rozoff, Rajesh Kumar","doi":"10.1007/s11869-024-01570-x","DOIUrl":null,"url":null,"abstract":"<div><p>Mathematical models serve as crucial tools for quantitatively assessing the environmental and population impact resulting from the release of hazardous substances. Often, precise source parameters remain elusive, leading to a reliance on rudimentary assumptions. This challenge is particularly pronounced in scenarios involving releases that are accidental or deliberate acts of terrorism. A conventional method for estimating the source term involves the construction of backward plumes originating from various sensors measuring tracer concentrations. The area displaying the highest overlap of these backward plumes typically offers an initial approximation for the most probable release location. The backward plume (BP) method has been compared with a machine learning based method. Both methods use data from a field campaign and from a synthetic dataset built from a simple setup featuring receptors arranged linearly downwind from the release point. A substantial number (~ 1500) of forward plume simulations are conducted, each initiated from random locations and under varying meteorological conditions. This extensive dataset encompasses critical meteorological variables and concentration measurements recorded by idealized receptors. Subsequently, the dataset has been partitioned into training and testing subsets. A feed-forward neural network (NN) has been employed. This NN is trained using the concentration data from the receptors and the associated meteorological variables as input, with the source location coordinates serving as the output. Subsequent verification is carried out using the testing dataset, facilitating a comparison between the NN's and BP’s predictions and the actual source locations. One of the key advantages of the NN-based approach is its ability to rapidly estimate the source term, typically within a fraction of a second on a standard laptop. This speed is of paramount significance in scenarios involving accidental releases, where swift response is essential. Notably, the computationally intensive tasks of dataset construction and NN training can be conducted offline, providing preparedness in areas where accidental releases may be anticipated.</p></div>","PeriodicalId":49109,"journal":{"name":"Air Quality Atmosphere and Health","volume":"17 10","pages":"2169 - 2186"},"PeriodicalIF":2.9000,"publicationDate":"2024-04-24","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Comparing machine learning and inverse modeling approaches for the source term estimation\",\"authors\":\"Stefano Alessandrini, Scott Meech, Will Cheng, Christopher Rozoff, Rajesh Kumar\",\"doi\":\"10.1007/s11869-024-01570-x\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><p>Mathematical models serve as crucial tools for quantitatively assessing the environmental and population impact resulting from the release of hazardous substances. Often, precise source parameters remain elusive, leading to a reliance on rudimentary assumptions. This challenge is particularly pronounced in scenarios involving releases that are accidental or deliberate acts of terrorism. A conventional method for estimating the source term involves the construction of backward plumes originating from various sensors measuring tracer concentrations. The area displaying the highest overlap of these backward plumes typically offers an initial approximation for the most probable release location. The backward plume (BP) method has been compared with a machine learning based method. Both methods use data from a field campaign and from a synthetic dataset built from a simple setup featuring receptors arranged linearly downwind from the release point. A substantial number (~ 1500) of forward plume simulations are conducted, each initiated from random locations and under varying meteorological conditions. This extensive dataset encompasses critical meteorological variables and concentration measurements recorded by idealized receptors. Subsequently, the dataset has been partitioned into training and testing subsets. A feed-forward neural network (NN) has been employed. This NN is trained using the concentration data from the receptors and the associated meteorological variables as input, with the source location coordinates serving as the output. Subsequent verification is carried out using the testing dataset, facilitating a comparison between the NN's and BP’s predictions and the actual source locations. One of the key advantages of the NN-based approach is its ability to rapidly estimate the source term, typically within a fraction of a second on a standard laptop. This speed is of paramount significance in scenarios involving accidental releases, where swift response is essential. Notably, the computationally intensive tasks of dataset construction and NN training can be conducted offline, providing preparedness in areas where accidental releases may be anticipated.</p></div>\",\"PeriodicalId\":49109,\"journal\":{\"name\":\"Air Quality Atmosphere and Health\",\"volume\":\"17 10\",\"pages\":\"2169 - 2186\"},\"PeriodicalIF\":2.9000,\"publicationDate\":\"2024-04-24\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Air Quality Atmosphere and Health\",\"FirstCategoryId\":\"93\",\"ListUrlMain\":\"https://link.springer.com/article/10.1007/s11869-024-01570-x\",\"RegionNum\":4,\"RegionCategory\":\"环境科学与生态学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q3\",\"JCRName\":\"ENVIRONMENTAL SCIENCES\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Air Quality Atmosphere and Health","FirstCategoryId":"93","ListUrlMain":"https://link.springer.com/article/10.1007/s11869-024-01570-x","RegionNum":4,"RegionCategory":"环境科学与生态学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"ENVIRONMENTAL SCIENCES","Score":null,"Total":0}
引用次数: 0
摘要
数学模型是定量评估有害物质排放对环境和人口影响的重要工具。通常情况下,精确的来源参数仍然难以确定,这就导致了对基本假设的依赖。在涉及意外释放或蓄意恐怖主义行为的情况下,这一挑战尤为突出。估算源项的传统方法包括构建源自各种测量示踪剂浓度的传感器的后向羽流。这些后向羽流重叠度最高的区域通常是最可能的释放位置的初始近似值。后向羽流 (BP) 方法与基于机器学习的方法进行了比较。这两种方法都使用了来自现场活动的数据和由简单设置(从释放点向下风向线性排列受体)建立的合成数据集的数据。我们进行了大量(约 1500 次)前向羽流模拟,每次模拟都是从随机位置开始,并在不同的气象条件下进行。这个广泛的数据集包括关键气象变量和理想化受体记录的浓度测量值。随后,数据集被划分为训练子集和测试子集。采用了一个前馈神经网络(NN)。该神经网络使用来自受体的浓度数据和相关气象变量作为输入进行训练,将源位置坐标作为输出。随后使用测试数据集进行验证,以便对 NN 和 BP 的预测结果与实际污染源位置进行比较。基于 NN 的方法的主要优势之一是能够快速估计声源项,通常在标准笔记本电脑上只需几分之一秒的时间。在涉及意外排放的情况下,这种速度至关重要,因为在这种情况下必须迅速做出反应。值得注意的是,数据集构建和 NN 训练等计算密集型任务可以离线进行,从而为可能发生意外释放的地区做好准备。
Comparing machine learning and inverse modeling approaches for the source term estimation
Mathematical models serve as crucial tools for quantitatively assessing the environmental and population impact resulting from the release of hazardous substances. Often, precise source parameters remain elusive, leading to a reliance on rudimentary assumptions. This challenge is particularly pronounced in scenarios involving releases that are accidental or deliberate acts of terrorism. A conventional method for estimating the source term involves the construction of backward plumes originating from various sensors measuring tracer concentrations. The area displaying the highest overlap of these backward plumes typically offers an initial approximation for the most probable release location. The backward plume (BP) method has been compared with a machine learning based method. Both methods use data from a field campaign and from a synthetic dataset built from a simple setup featuring receptors arranged linearly downwind from the release point. A substantial number (~ 1500) of forward plume simulations are conducted, each initiated from random locations and under varying meteorological conditions. This extensive dataset encompasses critical meteorological variables and concentration measurements recorded by idealized receptors. Subsequently, the dataset has been partitioned into training and testing subsets. A feed-forward neural network (NN) has been employed. This NN is trained using the concentration data from the receptors and the associated meteorological variables as input, with the source location coordinates serving as the output. Subsequent verification is carried out using the testing dataset, facilitating a comparison between the NN's and BP’s predictions and the actual source locations. One of the key advantages of the NN-based approach is its ability to rapidly estimate the source term, typically within a fraction of a second on a standard laptop. This speed is of paramount significance in scenarios involving accidental releases, where swift response is essential. Notably, the computationally intensive tasks of dataset construction and NN training can be conducted offline, providing preparedness in areas where accidental releases may be anticipated.
期刊介绍:
Air Quality, Atmosphere, and Health is a multidisciplinary journal which, by its very name, illustrates the broad range of work it publishes and which focuses on atmospheric consequences of human activities and their implications for human and ecological health.
It offers research papers, critical literature reviews and commentaries, as well as special issues devoted to topical subjects or themes.
International in scope, the journal presents papers that inform and stimulate a global readership, as the topic addressed are global in their import. Consequently, we do not encourage submission of papers involving local data that relate to local problems. Unless they demonstrate wide applicability, these are better submitted to national or regional journals.
Air Quality, Atmosphere & Health addresses such topics as acid precipitation; airborne particulate matter; air quality monitoring and management; exposure assessment; risk assessment; indoor air quality; atmospheric chemistry; atmospheric modeling and prediction; air pollution climatology; climate change and air quality; air pollution measurement; atmospheric impact assessment; forest-fire emissions; atmospheric science; greenhouse gases; health and ecological effects; clean air technology; regional and global change and satellite measurements.
This journal benefits a diverse audience of researchers, public health officials and policy makers addressing problems that call for solutions based in evidence from atmospheric and exposure assessment scientists, epidemiologists, and risk assessors. Publication in the journal affords the opportunity to reach beyond defined disciplinary niches to this broader readership.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


