{"title":"Sahand:使用自动编码器神经网络和 K-Means 算法的软件故障预测方法","authors":"Bahman Arasteh, Sahar Golshan, Shiva Shami, Farzad Kiani","doi":"10.1007/s10836-024-06116-8","DOIUrl":null,"url":null,"abstract":"<p>Software is playing a growing role in many safety-critical applications, and software systems dependability is a major concern. Predicting faulty modules of software before the testing phase is one method for enhancing software reliability. The ability to predict and identify the faulty modules of software can lower software testing costs. Machine learning algorithms can be used to solve software fault prediction problem. Identifying the faulty modules of software with the maximum accuracy, precision, and performance are the main objectives of this study. A hybrid method combining the autoencoder and the K-means algorithm is utilized in this paper to develop a software fault predictor. The autoencoder algorithm, as a preprocessor, is used to select the effective attributes of the training dataset and consequently to reduce its size. Using an autoencoder with the K-means clustering method results in lower clustering error and time. Tests conducted on the standard NASA PROMIS data sets demonstrate that by removing the inefficient elements from the training data set, the proposed fault predictor has increased accuracy (96%) and precision (93%). The recall criteria provided by the proposed method is about 87%. Also, reducing the time necessary to create the software fault predictor is the other merit of this study.</p>","PeriodicalId":501485,"journal":{"name":"Journal of Electronic Testing","volume":"16 1","pages":""},"PeriodicalIF":0.0000,"publicationDate":"2024-04-12","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Sahand: A Software Fault-Prediction Method Using Autoencoder Neural Network and K-Means Algorithm\",\"authors\":\"Bahman Arasteh, Sahar Golshan, Shiva Shami, Farzad Kiani\",\"doi\":\"10.1007/s10836-024-06116-8\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Software is playing a growing role in many safety-critical applications, and software systems dependability is a major concern. Predicting faulty modules of software before the testing phase is one method for enhancing software reliability. The ability to predict and identify the faulty modules of software can lower software testing costs. Machine learning algorithms can be used to solve software fault prediction problem. Identifying the faulty modules of software with the maximum accuracy, precision, and performance are the main objectives of this study. A hybrid method combining the autoencoder and the K-means algorithm is utilized in this paper to develop a software fault predictor. The autoencoder algorithm, as a preprocessor, is used to select the effective attributes of the training dataset and consequently to reduce its size. Using an autoencoder with the K-means clustering method results in lower clustering error and time. Tests conducted on the standard NASA PROMIS data sets demonstrate that by removing the inefficient elements from the training data set, the proposed fault predictor has increased accuracy (96%) and precision (93%). The recall criteria provided by the proposed method is about 87%. Also, reducing the time necessary to create the software fault predictor is the other merit of this study.</p>\",\"PeriodicalId\":501485,\"journal\":{\"name\":\"Journal of Electronic Testing\",\"volume\":\"16 1\",\"pages\":\"\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2024-04-12\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Electronic Testing\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1007/s10836-024-06116-8\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Electronic Testing","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1007/s10836-024-06116-8","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
摘要
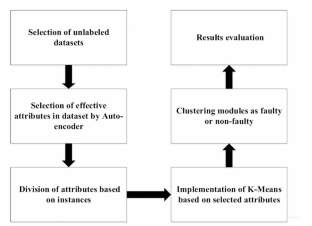
软件在许多安全关键型应用中发挥着越来越重要的作用,而软件系统的可靠性是人们关注的一个主要问题。在测试阶段之前预测软件的故障模块是提高软件可靠性的一种方法。预测和识别软件故障模块的能力可以降低软件测试成本。机器学习算法可用于解决软件故障预测问题。本研究的主要目标是以最高的准确度、精确度和性能识别软件故障模块。本文采用自编码器算法和 K-means 算法相结合的混合方法来开发软件故障预测器。自动编码器算法作为预处理器,用于选择训练数据集的有效属性,从而缩小数据集的规模。将自动编码器与 K-means 聚类方法结合使用,可以减少聚类误差和时间。在 NASA PROMIS 标准数据集上进行的测试表明,通过从训练数据集中删除低效元素,所提出的故障预测器提高了准确率(96%)和精确率(93%)。建议方法提供的召回标准约为 87%。此外,减少创建软件故障预测器所需的时间也是本研究的另一个优点。
Sahand: A Software Fault-Prediction Method Using Autoencoder Neural Network and K-Means Algorithm
Software is playing a growing role in many safety-critical applications, and software systems dependability is a major concern. Predicting faulty modules of software before the testing phase is one method for enhancing software reliability. The ability to predict and identify the faulty modules of software can lower software testing costs. Machine learning algorithms can be used to solve software fault prediction problem. Identifying the faulty modules of software with the maximum accuracy, precision, and performance are the main objectives of this study. A hybrid method combining the autoencoder and the K-means algorithm is utilized in this paper to develop a software fault predictor. The autoencoder algorithm, as a preprocessor, is used to select the effective attributes of the training dataset and consequently to reduce its size. Using an autoencoder with the K-means clustering method results in lower clustering error and time. Tests conducted on the standard NASA PROMIS data sets demonstrate that by removing the inefficient elements from the training data set, the proposed fault predictor has increased accuracy (96%) and precision (93%). The recall criteria provided by the proposed method is about 87%. Also, reducing the time necessary to create the software fault predictor is the other merit of this study.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


