揭开天空的面纱:利用机器学习技术对得克萨斯州 PM2.5 进行高分辨率预测。
IF 4.1
3区 医学
Q2 ENVIRONMENTAL SCIENCES
Journal of Exposure Science and Environmental Epidemiology
Pub Date : 2024-04-01
DOI:10.1038/s41370-024-00659-w
引用次数: 0
摘要
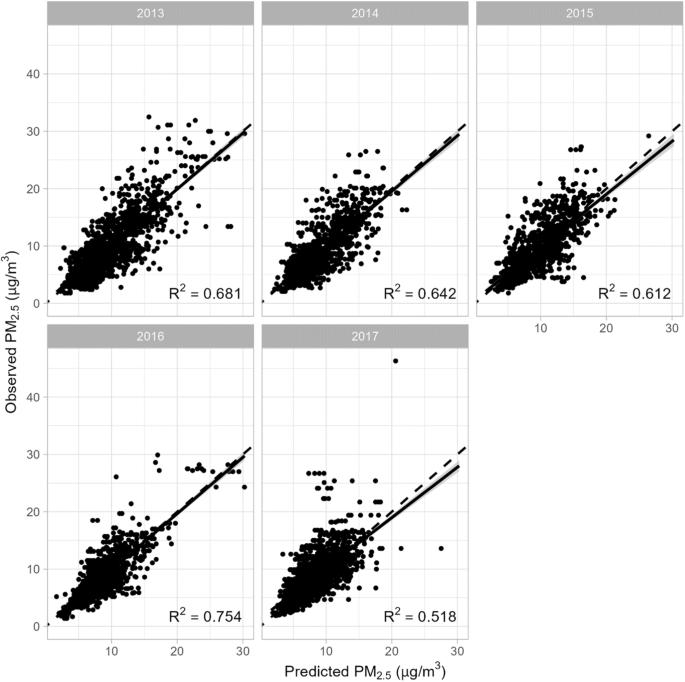
背景:尽管 PM2.5(空气动力学直径小于 2.5 µm 的细颗粒物)是德克萨斯州极为关注的一种空气污染物,但有限的监管监测器对决策和环境研究构成了重大挑战:本研究旨在利用新颖的机器学习方法,结合从卫星获取的气溶胶光学深度(AOD)以及各种天气和土地利用变量,预测每日精细空间尺度上的 PM2.5 浓度:我们汇编了 2013 年至 2017 年德克萨斯州的综合数据集,其中包括监管监测机构提供的地面 PM2.5 浓度;基于 MODIS 卫星图像检索的 1 千米分辨率 AOD 值;以及天气、土地使用、人口密度等。我们使用梯度提升树和随机森林两种机器学习方法,分别为每一年建立了预测模型,以估算 PM2.5 浓度。我们通过样本内和样本外验证对模型的预测性能进行了评估:梯度提升模型(0.94-0.97)和随机森林模型(0.81-0.90)产生的高 R2 值表明,我们的预测模型具有出色的样本内模型性能。然而,梯度提升模型的样本外 R2 值在 0.52-0.75 之间,随机森林模型的样本外 R2 值在 0.44-0.69 之间。不同年份的模型性能略有不同。在得克萨斯州东部,PM2.5 的预测浓度随时间呈总体下降趋势:我们利用机器学习方法来预测德克萨斯州的 PM2.5 浓度。梯度提升模型和随机森林模型都表现良好。梯度提升模型的表现略好于随机森林模型。我们的模型显示出出色的样本内预测性能(R2 > 0.9)。本文章由计算机程序翻译,如有差异,请以英文原文为准。
Unmasking the sky: high-resolution PM2.5 prediction in Texas using machine learning techniques
Although PM2.5 (fine particulate matter with an aerodynamic diameter less than 2.5 µm) is an air pollutant of great concern in Texas, limited regulatory monitors pose a significant challenge for decision-making and environmental studies. This study aimed to predict PM2.5 concentrations at a fine spatial scale on a daily basis by using novel machine learning approaches and incorporating satellite-derived Aerosol Optical Depth (AOD) and a variety of weather and land use variables. We compiled a comprehensive dataset in Texas from 2013 to 2017, including ground-level PM2.5 concentrations from regulatory monitors; AOD values at 1-km resolution based on images retrieved from the MODIS satellite; and weather, land-use, population density, among others. We built predictive models for each year separately to estimate PM2.5 concentrations using two machine learning approaches called gradient boosted trees and random forest. We evaluated the model prediction performance using in-sample and out-of-sample validations. Our predictive models demonstrate excellent in-sample model performance, as indicated by high R2 values generated from the gradient boosting models (0.94–0.97) and random forest models (0.81–0.90). However, the out-of-sample R2 values fall within a range of 0.52–0.75 for gradient boosting models and 0.44–0.69 for random forest models. Model performance varies slightly across years. A generally decreasing trend in predicted PM2.5 concentrations over time is observed in Eastern Texas. We utilized machine learning approaches to predict PM2.5 levels in Texas. Both gradient boosting and random forest models perform well. Gradient boosting models perform slightly better than random forest models. Our models showed excellent in-sample prediction performance (R2 > 0.9).
求助全文
通过发布文献求助,成功后即可免费获取论文全文。
去求助
来源期刊

CiteScore
8.90
自引率
6.70%
发文量
93
审稿时长
3 months
期刊介绍:
Journal of Exposure Science and Environmental Epidemiology (JESEE) aims to be the premier and authoritative source of information on advances in exposure science for professionals in a wide range of environmental and public health disciplines.
JESEE publishes original peer-reviewed research presenting significant advances in exposure science and exposure analysis, including development and application of the latest technologies for measuring exposures, and innovative computational approaches for translating novel data streams to characterize and predict exposures. The types of papers published in the research section of JESEE are original research articles, translation studies, and correspondence. Reported results should further understanding of the relationship between environmental exposure and human health, describe evaluated novel exposure science tools, or demonstrate potential of exposure science to enable decisions and actions that promote and protect human health.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


