{"title":"多任务学习以及摄像机定位和物体检测之间的联合改进","authors":"Junyi Wang, Yue Qi","doi":"10.1007/s41095-022-0319-z","DOIUrl":null,"url":null,"abstract":"<p>Visual localization and object detection both play important roles in various tasks. In many indoor application scenarios where some detected objects have fixed positions, the two techniques work closely together. However, few researchers consider these two tasks simultaneously, because of a lack of datasets and the little attention paid to such environments. In this paper, we explore multi-task network design and joint refinement of detection and localization. To address the dataset problem, we construct a medium indoor scene of an aviation exhibition hall through a semi-automatic process. The dataset provides localization and detection information, and is publicly available at https://drive.google.com/drive/folders/1U28zkuN4_I0dbzkqyIAKlAl5k9oUK0jI?usp=sharing for benchmarking localization and object detection tasks. Targeting this dataset, we have designed a multi-task network, JLDNet, based on YOLO v3, that outputs a target point cloud and object bounding boxes. For dynamic environments, the detection branch also promotes the perception of dynamics. JLDNet includes image feature learning, point feature learning, feature fusion, detection construction, and point cloud regression. Moreover, object-level bundle adjustment is used to further improve localization and detection accuracy. To test JLDNet and compare it to other methods, we have conducted experiments on 7 static scenes, our constructed dataset, and the dynamic TUM RGB-D and Bonn datasets. Our results show state-of-the-art accuracy for both tasks, and the benefit of jointly working on both tasks is demonstrated.\n</p>","PeriodicalId":37301,"journal":{"name":"Computational Visual Media","volume":"4 1","pages":""},"PeriodicalIF":18.3000,"publicationDate":"2024-02-08","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Multi-task learning and joint refinement between camera localization and object detection\",\"authors\":\"Junyi Wang, Yue Qi\",\"doi\":\"10.1007/s41095-022-0319-z\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Visual localization and object detection both play important roles in various tasks. In many indoor application scenarios where some detected objects have fixed positions, the two techniques work closely together. However, few researchers consider these two tasks simultaneously, because of a lack of datasets and the little attention paid to such environments. In this paper, we explore multi-task network design and joint refinement of detection and localization. To address the dataset problem, we construct a medium indoor scene of an aviation exhibition hall through a semi-automatic process. The dataset provides localization and detection information, and is publicly available at https://drive.google.com/drive/folders/1U28zkuN4_I0dbzkqyIAKlAl5k9oUK0jI?usp=sharing for benchmarking localization and object detection tasks. Targeting this dataset, we have designed a multi-task network, JLDNet, based on YOLO v3, that outputs a target point cloud and object bounding boxes. For dynamic environments, the detection branch also promotes the perception of dynamics. JLDNet includes image feature learning, point feature learning, feature fusion, detection construction, and point cloud regression. Moreover, object-level bundle adjustment is used to further improve localization and detection accuracy. To test JLDNet and compare it to other methods, we have conducted experiments on 7 static scenes, our constructed dataset, and the dynamic TUM RGB-D and Bonn datasets. Our results show state-of-the-art accuracy for both tasks, and the benefit of jointly working on both tasks is demonstrated.\\n</p>\",\"PeriodicalId\":37301,\"journal\":{\"name\":\"Computational Visual Media\",\"volume\":\"4 1\",\"pages\":\"\"},\"PeriodicalIF\":18.3000,\"publicationDate\":\"2024-02-08\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Computational Visual Media\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1007/s41095-022-0319-z\",\"RegionNum\":3,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"COMPUTER SCIENCE, SOFTWARE ENGINEERING\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Computational Visual Media","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s41095-022-0319-z","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, SOFTWARE ENGINEERING","Score":null,"Total":0}
Multi-task learning and joint refinement between camera localization and object detection
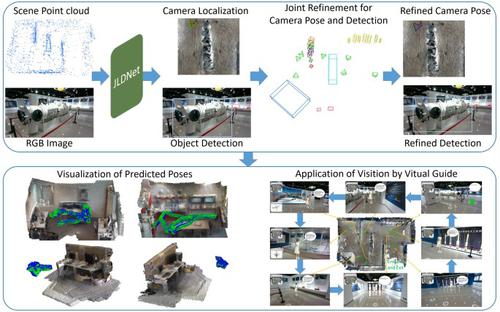
Visual localization and object detection both play important roles in various tasks. In many indoor application scenarios where some detected objects have fixed positions, the two techniques work closely together. However, few researchers consider these two tasks simultaneously, because of a lack of datasets and the little attention paid to such environments. In this paper, we explore multi-task network design and joint refinement of detection and localization. To address the dataset problem, we construct a medium indoor scene of an aviation exhibition hall through a semi-automatic process. The dataset provides localization and detection information, and is publicly available at https://drive.google.com/drive/folders/1U28zkuN4_I0dbzkqyIAKlAl5k9oUK0jI?usp=sharing for benchmarking localization and object detection tasks. Targeting this dataset, we have designed a multi-task network, JLDNet, based on YOLO v3, that outputs a target point cloud and object bounding boxes. For dynamic environments, the detection branch also promotes the perception of dynamics. JLDNet includes image feature learning, point feature learning, feature fusion, detection construction, and point cloud regression. Moreover, object-level bundle adjustment is used to further improve localization and detection accuracy. To test JLDNet and compare it to other methods, we have conducted experiments on 7 static scenes, our constructed dataset, and the dynamic TUM RGB-D and Bonn datasets. Our results show state-of-the-art accuracy for both tasks, and the benefit of jointly working on both tasks is demonstrated.
期刊介绍:
Computational Visual Media is a peer-reviewed open access journal. It publishes original high-quality research papers and significant review articles on novel ideas, methods, and systems relevant to visual media.
Computational Visual Media publishes articles that focus on, but are not limited to, the following areas:
• Editing and composition of visual media
• Geometric computing for images and video
• Geometry modeling and processing
• Machine learning for visual media
• Physically based animation
• Realistic rendering
• Recognition and understanding of visual media
• Visual computing for robotics
• Visualization and visual analytics
Other interdisciplinary research into visual media that combines aspects of computer graphics, computer vision, image and video processing, geometric computing, and machine learning is also within the journal''s scope.
This is an open access journal, published quarterly by Tsinghua University Press and Springer. The open access fees (article-processing charges) are fully sponsored by Tsinghua University, China. Authors can publish in the journal without any additional charges.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


