Jinpei Tan, Fengyun Zhang, Jiening Wu, Li Luo, Shukai Duan, Lidan Wang
{"title":"增强量化忆阻器神经网络的现场更新:连体网络学习法","authors":"Jinpei Tan, Fengyun Zhang, Jiening Wu, Li Luo, Shukai Duan, Lidan Wang","doi":"10.1007/s11571-024-10069-1","DOIUrl":null,"url":null,"abstract":"<p>Brain-inspired neuromorphic computing has emerged as a promising solution to overcome the energy and speed limitations of conventional von Neumann architectures. In this context, in-memory computing utilizing memristors has gained attention as a key technology, harnessing their non-volatile characteristics to replicate synaptic behavior akin to the human brain. However, challenges arise from non-linearities, asymmetries, and device variations in memristive devices during synaptic weight updates, leading to inaccurate weight adjustments and diminished recognition accuracy. Moreover, the repetitive weight updates pose endurance challenges for these devices, adversely affecting latency and energy consumption. To address these issues, we propose a Siamese network learning approach to optimize the training of multi-level memristor neural networks. During neural inference, forward propagation takes place within the memristor neural network, enabling error and noise detection in the memristive devices and hardware circuits. Simultaneously, high-precision gradient computation occurs on the software side, initially updating the floating-point weights within the Siamese network with gradients. Subsequently, weight quantization is performed, and the memristor conductance values requiring updates are modified using a sparse update strategy. Additionally, we introduce gradient accumulation and weight quantization error compensation to further enhance network performance. The experimental results of MNIST data recognition, whether based on a MLP or a CNN model, demonstrate the rapid convergence of our network model. Moreover, our method successfully eliminates over 98% of weight updates for memristor conductance weights within a single epoch. This substantial reduction in weight updates leads to a significant decrease in energy consumption and time delay by more than 98% when compared to the basic closed-loop update method. Consequently, this approach effectively addresses the durability requirements of memristive devices.</p>","PeriodicalId":10500,"journal":{"name":"Cognitive Neurodynamics","volume":"12 1","pages":""},"PeriodicalIF":3.9000,"publicationDate":"2024-02-13","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Enhancing in-situ updates of quantized memristor neural networks: a Siamese network learning approach\",\"authors\":\"Jinpei Tan, Fengyun Zhang, Jiening Wu, Li Luo, Shukai Duan, Lidan Wang\",\"doi\":\"10.1007/s11571-024-10069-1\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Brain-inspired neuromorphic computing has emerged as a promising solution to overcome the energy and speed limitations of conventional von Neumann architectures. In this context, in-memory computing utilizing memristors has gained attention as a key technology, harnessing their non-volatile characteristics to replicate synaptic behavior akin to the human brain. However, challenges arise from non-linearities, asymmetries, and device variations in memristive devices during synaptic weight updates, leading to inaccurate weight adjustments and diminished recognition accuracy. Moreover, the repetitive weight updates pose endurance challenges for these devices, adversely affecting latency and energy consumption. To address these issues, we propose a Siamese network learning approach to optimize the training of multi-level memristor neural networks. During neural inference, forward propagation takes place within the memristor neural network, enabling error and noise detection in the memristive devices and hardware circuits. Simultaneously, high-precision gradient computation occurs on the software side, initially updating the floating-point weights within the Siamese network with gradients. Subsequently, weight quantization is performed, and the memristor conductance values requiring updates are modified using a sparse update strategy. Additionally, we introduce gradient accumulation and weight quantization error compensation to further enhance network performance. The experimental results of MNIST data recognition, whether based on a MLP or a CNN model, demonstrate the rapid convergence of our network model. Moreover, our method successfully eliminates over 98% of weight updates for memristor conductance weights within a single epoch. This substantial reduction in weight updates leads to a significant decrease in energy consumption and time delay by more than 98% when compared to the basic closed-loop update method. Consequently, this approach effectively addresses the durability requirements of memristive devices.</p>\",\"PeriodicalId\":10500,\"journal\":{\"name\":\"Cognitive Neurodynamics\",\"volume\":\"12 1\",\"pages\":\"\"},\"PeriodicalIF\":3.9000,\"publicationDate\":\"2024-02-13\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Cognitive Neurodynamics\",\"FirstCategoryId\":\"5\",\"ListUrlMain\":\"https://doi.org/10.1007/s11571-024-10069-1\",\"RegionNum\":3,\"RegionCategory\":\"工程技术\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"NEUROSCIENCES\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Cognitive Neurodynamics","FirstCategoryId":"5","ListUrlMain":"https://doi.org/10.1007/s11571-024-10069-1","RegionNum":3,"RegionCategory":"工程技术","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"NEUROSCIENCES","Score":null,"Total":0}
Enhancing in-situ updates of quantized memristor neural networks: a Siamese network learning approach
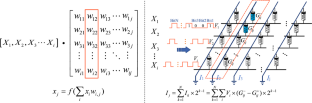
Brain-inspired neuromorphic computing has emerged as a promising solution to overcome the energy and speed limitations of conventional von Neumann architectures. In this context, in-memory computing utilizing memristors has gained attention as a key technology, harnessing their non-volatile characteristics to replicate synaptic behavior akin to the human brain. However, challenges arise from non-linearities, asymmetries, and device variations in memristive devices during synaptic weight updates, leading to inaccurate weight adjustments and diminished recognition accuracy. Moreover, the repetitive weight updates pose endurance challenges for these devices, adversely affecting latency and energy consumption. To address these issues, we propose a Siamese network learning approach to optimize the training of multi-level memristor neural networks. During neural inference, forward propagation takes place within the memristor neural network, enabling error and noise detection in the memristive devices and hardware circuits. Simultaneously, high-precision gradient computation occurs on the software side, initially updating the floating-point weights within the Siamese network with gradients. Subsequently, weight quantization is performed, and the memristor conductance values requiring updates are modified using a sparse update strategy. Additionally, we introduce gradient accumulation and weight quantization error compensation to further enhance network performance. The experimental results of MNIST data recognition, whether based on a MLP or a CNN model, demonstrate the rapid convergence of our network model. Moreover, our method successfully eliminates over 98% of weight updates for memristor conductance weights within a single epoch. This substantial reduction in weight updates leads to a significant decrease in energy consumption and time delay by more than 98% when compared to the basic closed-loop update method. Consequently, this approach effectively addresses the durability requirements of memristive devices.
期刊介绍:
Cognitive Neurodynamics provides a unique forum of communication and cooperation for scientists and engineers working in the field of cognitive neurodynamics, intelligent science and applications, bridging the gap between theory and application, without any preference for pure theoretical, experimental or computational models.
The emphasis is to publish original models of cognitive neurodynamics, novel computational theories and experimental results. In particular, intelligent science inspired by cognitive neuroscience and neurodynamics is also very welcome.
The scope of Cognitive Neurodynamics covers cognitive neuroscience, neural computation based on dynamics, computer science, intelligent science as well as their interdisciplinary applications in the natural and engineering sciences. Papers that are appropriate for non-specialist readers are encouraged.
1. There is no page limit for manuscripts submitted to Cognitive Neurodynamics. Research papers should clearly represent an important advance of especially broad interest to researchers and technologists in neuroscience, biophysics, BCI, neural computer and intelligent robotics.
2. Cognitive Neurodynamics also welcomes brief communications: short papers reporting results that are of genuinely broad interest but that for one reason and another do not make a sufficiently complete story to justify a full article publication. Brief Communications should consist of approximately four manuscript pages.
3. Cognitive Neurodynamics publishes review articles in which a specific field is reviewed through an exhaustive literature survey. There are no restrictions on the number of pages. Review articles are usually invited, but submitted reviews will also be considered.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


