{"title":"利用迁移学习和小型人类与元伪标签数据集进行命名实体识别","authors":"Kyoungman Bae, Joon-Ho Lim","doi":"10.4218/etrij.2023-0321","DOIUrl":null,"url":null,"abstract":"<p>We introduce a high-performance named entity recognition (NER) model for written and spoken language. To overcome challenges related to labeled data scarcity and domain shifts, we use transfer learning to leverage our previously developed KorBERT as the base model. We also adopt a meta-pseudo-label method using a teacher/student framework with labeled and unlabeled data. Our model presents two modifications. First, the student model is updated with an average loss from both human- and pseudo-labeled data. Second, the influence of noisy pseudo-labeled data is mitigated by considering feedback scores and updating the teacher model only when below a threshold (0.0005). We achieve the target NER performance in the spoken language domain and improve that in the written language domain by proposing a straightforward rollback method that reverts to the best model based on scarce human-labeled data. Further improvement is achieved by adjusting the label vector weights in the named entity dictionary.</p>","PeriodicalId":11901,"journal":{"name":"ETRI Journal","volume":"46 1","pages":"59-70"},"PeriodicalIF":1.3000,"publicationDate":"2024-02-14","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.4218/etrij.2023-0321","citationCount":"0","resultStr":"{\"title\":\"Named entity recognition using transfer learning and small human- and meta-pseudo-labeled datasets\",\"authors\":\"Kyoungman Bae, Joon-Ho Lim\",\"doi\":\"10.4218/etrij.2023-0321\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>We introduce a high-performance named entity recognition (NER) model for written and spoken language. To overcome challenges related to labeled data scarcity and domain shifts, we use transfer learning to leverage our previously developed KorBERT as the base model. We also adopt a meta-pseudo-label method using a teacher/student framework with labeled and unlabeled data. Our model presents two modifications. First, the student model is updated with an average loss from both human- and pseudo-labeled data. Second, the influence of noisy pseudo-labeled data is mitigated by considering feedback scores and updating the teacher model only when below a threshold (0.0005). We achieve the target NER performance in the spoken language domain and improve that in the written language domain by proposing a straightforward rollback method that reverts to the best model based on scarce human-labeled data. Further improvement is achieved by adjusting the label vector weights in the named entity dictionary.</p>\",\"PeriodicalId\":11901,\"journal\":{\"name\":\"ETRI Journal\",\"volume\":\"46 1\",\"pages\":\"59-70\"},\"PeriodicalIF\":1.3000,\"publicationDate\":\"2024-02-14\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://onlinelibrary.wiley.com/doi/epdf/10.4218/etrij.2023-0321\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"ETRI Journal\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://onlinelibrary.wiley.com/doi/10.4218/etrij.2023-0321\",\"RegionNum\":4,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q3\",\"JCRName\":\"ENGINEERING, ELECTRICAL & ELECTRONIC\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"ETRI Journal","FirstCategoryId":"94","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.4218/etrij.2023-0321","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"ENGINEERING, ELECTRICAL & ELECTRONIC","Score":null,"Total":0}
引用次数: 0
摘要
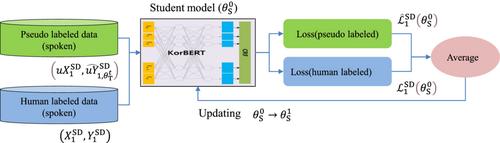
我们为书面语和口语引入了一种高性能命名实体识别(NER)模型。为了克服标注数据稀缺和领域转移带来的挑战,我们使用迁移学习来利用之前开发的 KorBERT 作为基础模型。我们还采用了一种元伪标签方法,使用带有标签和未标签数据的教师/学生框架。我们的模型有两处修改。首先,学生模型根据人类和伪标签数据的平均损失进行更新。其次,通过考虑反馈分数并仅在低于阈值(0.0005)时更新教师模型,减轻了噪声伪标签数据的影响。我们在口语领域实现了目标 NER 性能,并通过提出一种直接的回滚方法,在稀缺的人类标记数据基础上恢复到最佳模型,从而提高了书面语言领域的 NER 性能。通过调整命名实体字典中的标签向量权重,可以进一步提高性能。
Named entity recognition using transfer learning and small human- and meta-pseudo-labeled datasets
We introduce a high-performance named entity recognition (NER) model for written and spoken language. To overcome challenges related to labeled data scarcity and domain shifts, we use transfer learning to leverage our previously developed KorBERT as the base model. We also adopt a meta-pseudo-label method using a teacher/student framework with labeled and unlabeled data. Our model presents two modifications. First, the student model is updated with an average loss from both human- and pseudo-labeled data. Second, the influence of noisy pseudo-labeled data is mitigated by considering feedback scores and updating the teacher model only when below a threshold (0.0005). We achieve the target NER performance in the spoken language domain and improve that in the written language domain by proposing a straightforward rollback method that reverts to the best model based on scarce human-labeled data. Further improvement is achieved by adjusting the label vector weights in the named entity dictionary.
期刊介绍:
ETRI Journal is an international, peer-reviewed multidisciplinary journal published bimonthly in English. The main focus of the journal is to provide an open forum to exchange innovative ideas and technology in the fields of information, telecommunications, and electronics.
Key topics of interest include high-performance computing, big data analytics, cloud computing, multimedia technology, communication networks and services, wireless communications and mobile computing, material and component technology, as well as security.
With an international editorial committee and experts from around the world as reviewers, ETRI Journal publishes high-quality research papers on the latest and best developments from the global community.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


