{"title":"将像素艺术角色生成作为使用广义泛函模型的图像到图像转换问题","authors":"Flávio Coutinho , Luiz Chaimowicz","doi":"10.1016/j.gmod.2024.101213","DOIUrl":null,"url":null,"abstract":"<div><p>Asset creation in game development usually requires multiple iterations until a final version is achieved. This iterative process becomes more significant when the content is pixel art, in which the artist carefully places each pixel. We hypothesize that the problem of generating character sprites in a target pose (e.g., facing right) given a source (e.g., facing front) can be framed as an image-to-image translation task. Then, we present an architecture of deep generative models that takes as input an image of a character in one domain (pose) and transfers it to another. We approach the problem using generative adversarial networks (GANs) and build on Pix2Pix’s architecture while leveraging some specific characteristics of the pixel art style. We evaluated the trained models using four small datasets (less than 1k) and a more extensive and diverse one (12k). The models yielded promising results, and their generalization capacity varies according to the dataset size and variability. After training models to generate images among four domains (i.e., front, right, back, left), we present an early version of a mixed-initiative sprite editor that allows users to interact with them and iterate in creating character sprites.</p></div>","PeriodicalId":55083,"journal":{"name":"Graphical Models","volume":"132 ","pages":"Article 101213"},"PeriodicalIF":2.2000,"publicationDate":"2024-02-02","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.sciencedirect.com/science/article/pii/S1524070324000018/pdfft?md5=d7948e383c160b41fc886121e68e438f&pid=1-s2.0-S1524070324000018-main.pdf","citationCount":"0","resultStr":"{\"title\":\"Pixel art character generation as an image-to-image translation problem using GANs\",\"authors\":\"Flávio Coutinho , Luiz Chaimowicz\",\"doi\":\"10.1016/j.gmod.2024.101213\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><p>Asset creation in game development usually requires multiple iterations until a final version is achieved. This iterative process becomes more significant when the content is pixel art, in which the artist carefully places each pixel. We hypothesize that the problem of generating character sprites in a target pose (e.g., facing right) given a source (e.g., facing front) can be framed as an image-to-image translation task. Then, we present an architecture of deep generative models that takes as input an image of a character in one domain (pose) and transfers it to another. We approach the problem using generative adversarial networks (GANs) and build on Pix2Pix’s architecture while leveraging some specific characteristics of the pixel art style. We evaluated the trained models using four small datasets (less than 1k) and a more extensive and diverse one (12k). The models yielded promising results, and their generalization capacity varies according to the dataset size and variability. After training models to generate images among four domains (i.e., front, right, back, left), we present an early version of a mixed-initiative sprite editor that allows users to interact with them and iterate in creating character sprites.</p></div>\",\"PeriodicalId\":55083,\"journal\":{\"name\":\"Graphical Models\",\"volume\":\"132 \",\"pages\":\"Article 101213\"},\"PeriodicalIF\":2.2000,\"publicationDate\":\"2024-02-02\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.sciencedirect.com/science/article/pii/S1524070324000018/pdfft?md5=d7948e383c160b41fc886121e68e438f&pid=1-s2.0-S1524070324000018-main.pdf\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Graphical Models\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S1524070324000018\",\"RegionNum\":4,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"COMPUTER SCIENCE, SOFTWARE ENGINEERING\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Graphical Models","FirstCategoryId":"94","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S1524070324000018","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"COMPUTER SCIENCE, SOFTWARE ENGINEERING","Score":null,"Total":0}
Pixel art character generation as an image-to-image translation problem using GANs
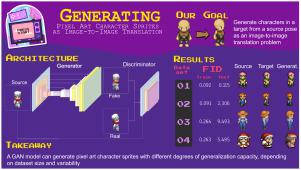
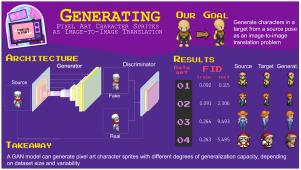
Asset creation in game development usually requires multiple iterations until a final version is achieved. This iterative process becomes more significant when the content is pixel art, in which the artist carefully places each pixel. We hypothesize that the problem of generating character sprites in a target pose (e.g., facing right) given a source (e.g., facing front) can be framed as an image-to-image translation task. Then, we present an architecture of deep generative models that takes as input an image of a character in one domain (pose) and transfers it to another. We approach the problem using generative adversarial networks (GANs) and build on Pix2Pix’s architecture while leveraging some specific characteristics of the pixel art style. We evaluated the trained models using four small datasets (less than 1k) and a more extensive and diverse one (12k). The models yielded promising results, and their generalization capacity varies according to the dataset size and variability. After training models to generate images among four domains (i.e., front, right, back, left), we present an early version of a mixed-initiative sprite editor that allows users to interact with them and iterate in creating character sprites.
期刊介绍:
Graphical Models is recognized internationally as a highly rated, top tier journal and is focused on the creation, geometric processing, animation, and visualization of graphical models and on their applications in engineering, science, culture, and entertainment. GMOD provides its readers with thoroughly reviewed and carefully selected papers that disseminate exciting innovations, that teach rigorous theoretical foundations, that propose robust and efficient solutions, or that describe ambitious systems or applications in a variety of topics.
We invite papers in five categories: research (contributions of novel theoretical or practical approaches or solutions), survey (opinionated views of the state-of-the-art and challenges in a specific topic), system (the architecture and implementation details of an innovative architecture for a complete system that supports model/animation design, acquisition, analysis, visualization?), application (description of a novel application of know techniques and evaluation of its impact), or lecture (an elegant and inspiring perspective on previously published results that clarifies them and teaches them in a new way).
GMOD offers its authors an accelerated review, feedback from experts in the field, immediate online publication of accepted papers, no restriction on color and length (when justified by the content) in the online version, and a broad promotion of published papers. A prestigious group of editors selected from among the premier international researchers in their fields oversees the review process.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


