Ryan A. Folk, Robert P. Guralnick, Raphael T. LaFrance
{"title":"FloraTraiter:从描述性生物多样性文献中自动解析特征","authors":"Ryan A. Folk, Robert P. Guralnick, Raphael T. LaFrance","doi":"10.1002/aps3.11563","DOIUrl":null,"url":null,"abstract":"<div>\n \n \n <section>\n \n <h3> Premise</h3>\n \n <p>Plant trait data are essential for quantifying biodiversity and function across Earth, but these data are challenging to acquire for large studies. Diverse strategies are needed, including the liberation of heritage data locked within specialist literature such as floras and taxonomic monographs. Here we report FloraTraiter, a novel approach using rule-based natural language processing (NLP) to parse computable trait data from biodiversity literature.</p>\n </section>\n \n <section>\n \n <h3> Methods</h3>\n \n <p>FloraTraiter was implemented through collaborative work between programmers and botanical experts and customized for both online floras and scanned literature. We report a strategy spanning optical character recognition, recognition of taxa, iterative building of traits, and establishing linkages among all of these, as well as curational tools and code for turning these results into standard morphological matrices.</p>\n </section>\n \n <section>\n \n <h3> Results</h3>\n \n <p>Over 95% of treatment content was successfully parsed for traits with <1% error. Data for more than 700 taxa are reported, including a demonstration of common downstream uses.</p>\n </section>\n \n <section>\n \n <h3> Conclusions</h3>\n \n <p>We identify strategies, applications, tips, and challenges that we hope will facilitate future similar efforts to produce large open-source trait data sets for broad community reuse. Largely automated tools like FloraTraiter will be an important addition to the toolkit for assembling trait data at scale.</p>\n </section>\n </div>","PeriodicalId":8022,"journal":{"name":"Applications in Plant Sciences","volume":"12 1","pages":""},"PeriodicalIF":2.4000,"publicationDate":"2024-01-18","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1002/aps3.11563","citationCount":"0","resultStr":"{\"title\":\"FloraTraiter: Automated parsing of traits from descriptive biodiversity literature\",\"authors\":\"Ryan A. Folk, Robert P. Guralnick, Raphael T. LaFrance\",\"doi\":\"10.1002/aps3.11563\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div>\\n \\n \\n <section>\\n \\n <h3> Premise</h3>\\n \\n <p>Plant trait data are essential for quantifying biodiversity and function across Earth, but these data are challenging to acquire for large studies. Diverse strategies are needed, including the liberation of heritage data locked within specialist literature such as floras and taxonomic monographs. Here we report FloraTraiter, a novel approach using rule-based natural language processing (NLP) to parse computable trait data from biodiversity literature.</p>\\n </section>\\n \\n <section>\\n \\n <h3> Methods</h3>\\n \\n <p>FloraTraiter was implemented through collaborative work between programmers and botanical experts and customized for both online floras and scanned literature. We report a strategy spanning optical character recognition, recognition of taxa, iterative building of traits, and establishing linkages among all of these, as well as curational tools and code for turning these results into standard morphological matrices.</p>\\n </section>\\n \\n <section>\\n \\n <h3> Results</h3>\\n \\n <p>Over 95% of treatment content was successfully parsed for traits with <1% error. Data for more than 700 taxa are reported, including a demonstration of common downstream uses.</p>\\n </section>\\n \\n <section>\\n \\n <h3> Conclusions</h3>\\n \\n <p>We identify strategies, applications, tips, and challenges that we hope will facilitate future similar efforts to produce large open-source trait data sets for broad community reuse. Largely automated tools like FloraTraiter will be an important addition to the toolkit for assembling trait data at scale.</p>\\n </section>\\n </div>\",\"PeriodicalId\":8022,\"journal\":{\"name\":\"Applications in Plant Sciences\",\"volume\":\"12 1\",\"pages\":\"\"},\"PeriodicalIF\":2.4000,\"publicationDate\":\"2024-01-18\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://onlinelibrary.wiley.com/doi/epdf/10.1002/aps3.11563\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Applications in Plant Sciences\",\"FirstCategoryId\":\"99\",\"ListUrlMain\":\"https://bsapubs.onlinelibrary.wiley.com/doi/10.1002/aps3.11563\",\"RegionNum\":3,\"RegionCategory\":\"生物学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"PLANT SCIENCES\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Applications in Plant Sciences","FirstCategoryId":"99","ListUrlMain":"https://bsapubs.onlinelibrary.wiley.com/doi/10.1002/aps3.11563","RegionNum":3,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"PLANT SCIENCES","Score":null,"Total":0}
FloraTraiter: Automated parsing of traits from descriptive biodiversity literature
Premise
Plant trait data are essential for quantifying biodiversity and function across Earth, but these data are challenging to acquire for large studies. Diverse strategies are needed, including the liberation of heritage data locked within specialist literature such as floras and taxonomic monographs. Here we report FloraTraiter, a novel approach using rule-based natural language processing (NLP) to parse computable trait data from biodiversity literature.
Methods
FloraTraiter was implemented through collaborative work between programmers and botanical experts and customized for both online floras and scanned literature. We report a strategy spanning optical character recognition, recognition of taxa, iterative building of traits, and establishing linkages among all of these, as well as curational tools and code for turning these results into standard morphological matrices.
Results
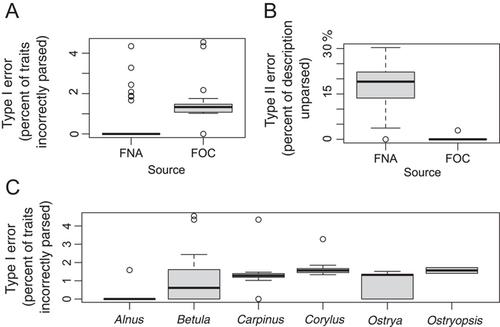
Over 95% of treatment content was successfully parsed for traits with <1% error. Data for more than 700 taxa are reported, including a demonstration of common downstream uses.
Conclusions
We identify strategies, applications, tips, and challenges that we hope will facilitate future similar efforts to produce large open-source trait data sets for broad community reuse. Largely automated tools like FloraTraiter will be an important addition to the toolkit for assembling trait data at scale.
期刊介绍:
Applications in Plant Sciences (APPS) is a monthly, peer-reviewed, open access journal promoting the rapid dissemination of newly developed, innovative tools and protocols in all areas of the plant sciences, including genetics, structure, function, development, evolution, systematics, and ecology. Given the rapid progress today in technology and its application in the plant sciences, the goal of APPS is to foster communication within the plant science community to advance scientific research. APPS is a publication of the Botanical Society of America, originating in 2009 as the American Journal of Botany''s online-only section, AJB Primer Notes & Protocols in the Plant Sciences.
APPS publishes the following types of articles: (1) Protocol Notes describe new methods and technological advancements; (2) Genomic Resources Articles characterize the development and demonstrate the usefulness of newly developed genomic resources, including transcriptomes; (3) Software Notes detail new software applications; (4) Application Articles illustrate the application of a new protocol, method, or software application within the context of a larger study; (5) Review Articles evaluate available techniques, methods, or protocols; (6) Primer Notes report novel genetic markers with evidence of wide applicability.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


