{"title":"无属性嵌入的多模态少镜头分类","authors":"Jun Qing Chang, Deepu Rajan, Nicholas Vun","doi":"10.1186/s13640-024-00620-9","DOIUrl":null,"url":null,"abstract":"<p>Multimodal few-shot learning aims to exploit complementary information inherent in multiple modalities for vision tasks in low data scenarios. Most of the current research focuses on a suitable embedding space for the various modalities. While solutions based on embedding provide state-of-the-art results, they reduce the interpretability of the model. Separate visualization approaches enable the models to become more transparent. In this paper, a multimodal few-shot learning framework that is inherently interpretable is presented. This is achieved by using the textual modality in the form of attributes without embedding them. This enables the model to directly explain which attributes caused it to classify an image into a particular class. The model consists of a variational autoencoder to learn the visual latent representation, which is combined with a semantic latent representation that is learnt from a normal autoencoder, which calculates a semantic loss between the latent representation and a binary attribute vector. A decoder reconstructs the original image from concatenated latent vectors. The proposed model outperforms other multimodal methods when all test classes are used, e.g., 50 classes in a 50-way 1-shot setting, and is comparable for lesser number of ways. Since raw text attributes are used, the datasets for evaluation are CUB, SUN and AWA2. The effectiveness of interpretability provided by the model is evaluated by analyzing how well it has learnt to identify the attributes.</p>","PeriodicalId":49322,"journal":{"name":"Eurasip Journal on Image and Video Processing","volume":"4 1","pages":""},"PeriodicalIF":1.8000,"publicationDate":"2024-01-10","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Multimodal few-shot classification without attribute embedding\",\"authors\":\"Jun Qing Chang, Deepu Rajan, Nicholas Vun\",\"doi\":\"10.1186/s13640-024-00620-9\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Multimodal few-shot learning aims to exploit complementary information inherent in multiple modalities for vision tasks in low data scenarios. Most of the current research focuses on a suitable embedding space for the various modalities. While solutions based on embedding provide state-of-the-art results, they reduce the interpretability of the model. Separate visualization approaches enable the models to become more transparent. In this paper, a multimodal few-shot learning framework that is inherently interpretable is presented. This is achieved by using the textual modality in the form of attributes without embedding them. This enables the model to directly explain which attributes caused it to classify an image into a particular class. The model consists of a variational autoencoder to learn the visual latent representation, which is combined with a semantic latent representation that is learnt from a normal autoencoder, which calculates a semantic loss between the latent representation and a binary attribute vector. A decoder reconstructs the original image from concatenated latent vectors. The proposed model outperforms other multimodal methods when all test classes are used, e.g., 50 classes in a 50-way 1-shot setting, and is comparable for lesser number of ways. Since raw text attributes are used, the datasets for evaluation are CUB, SUN and AWA2. The effectiveness of interpretability provided by the model is evaluated by analyzing how well it has learnt to identify the attributes.</p>\",\"PeriodicalId\":49322,\"journal\":{\"name\":\"Eurasip Journal on Image and Video Processing\",\"volume\":\"4 1\",\"pages\":\"\"},\"PeriodicalIF\":1.8000,\"publicationDate\":\"2024-01-10\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Eurasip Journal on Image and Video Processing\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1186/s13640-024-00620-9\",\"RegionNum\":4,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Eurasip Journal on Image and Video Processing","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1186/s13640-024-00620-9","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
Multimodal few-shot classification without attribute embedding
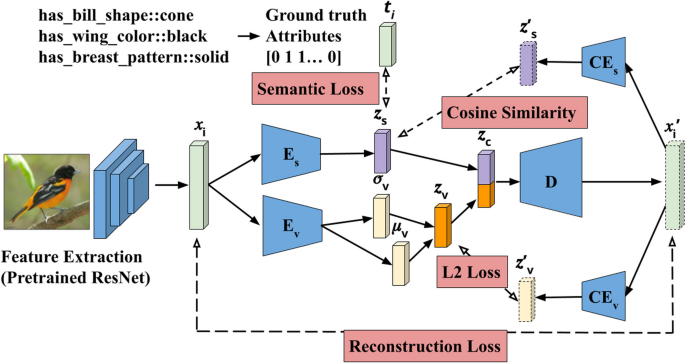
Multimodal few-shot learning aims to exploit complementary information inherent in multiple modalities for vision tasks in low data scenarios. Most of the current research focuses on a suitable embedding space for the various modalities. While solutions based on embedding provide state-of-the-art results, they reduce the interpretability of the model. Separate visualization approaches enable the models to become more transparent. In this paper, a multimodal few-shot learning framework that is inherently interpretable is presented. This is achieved by using the textual modality in the form of attributes without embedding them. This enables the model to directly explain which attributes caused it to classify an image into a particular class. The model consists of a variational autoencoder to learn the visual latent representation, which is combined with a semantic latent representation that is learnt from a normal autoencoder, which calculates a semantic loss between the latent representation and a binary attribute vector. A decoder reconstructs the original image from concatenated latent vectors. The proposed model outperforms other multimodal methods when all test classes are used, e.g., 50 classes in a 50-way 1-shot setting, and is comparable for lesser number of ways. Since raw text attributes are used, the datasets for evaluation are CUB, SUN and AWA2. The effectiveness of interpretability provided by the model is evaluated by analyzing how well it has learnt to identify the attributes.
期刊介绍:
EURASIP Journal on Image and Video Processing is intended for researchers from both academia and industry, who are active in the multidisciplinary field of image and video processing. The scope of the journal covers all theoretical and practical aspects of the domain, from basic research to development of application.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


