{"title":"通过生成模型生成多样化的穿衣三维人体动画","authors":"Min Shi, Wenke Feng, Lin Gao, Dengming Zhu","doi":"10.1007/s41095-022-0324-2","DOIUrl":null,"url":null,"abstract":"<p>Data-driven garment animation is a current topic of interest in the computer graphics industry. Existing approaches generally establish the mapping between a single human pose or a temporal pose sequence, and garment deformation, but it is difficult to quickly generate diverse clothed human animations. We address this problem with a method to automatically synthesize dressed human animations with temporal consistency from a specified human motion label. At the heart of our method is a two-stage strategy. Specifically, we first learn a latent space encoding the sequence-level distribution of human motions utilizing a transformer-based conditional variational autoencoder (Transformer-CVAE). Then a garment simulator synthesizes dynamic garment shapes using a transformer encoder–decoder architecture. Since the learned latent space comes from varied human motions, our method can generate a variety of styles of motions given a specific motion label. By means of a novel beginning of sequence (BOS) learning strategy and a self-supervised refinement procedure, our garment simulator is capable of efficiently synthesizing garment deformation sequences corresponding to the generated human motions while maintaining temporal and spatial consistency. We verify our ideas experimentally. This is the first generative model that directly dresses human animation.\n</p>","PeriodicalId":37301,"journal":{"name":"Computational Visual Media","volume":"24 1","pages":""},"PeriodicalIF":18.3000,"publicationDate":"2024-01-03","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Generating diverse clothed 3D human animations via a generative model\",\"authors\":\"Min Shi, Wenke Feng, Lin Gao, Dengming Zhu\",\"doi\":\"10.1007/s41095-022-0324-2\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Data-driven garment animation is a current topic of interest in the computer graphics industry. Existing approaches generally establish the mapping between a single human pose or a temporal pose sequence, and garment deformation, but it is difficult to quickly generate diverse clothed human animations. We address this problem with a method to automatically synthesize dressed human animations with temporal consistency from a specified human motion label. At the heart of our method is a two-stage strategy. Specifically, we first learn a latent space encoding the sequence-level distribution of human motions utilizing a transformer-based conditional variational autoencoder (Transformer-CVAE). Then a garment simulator synthesizes dynamic garment shapes using a transformer encoder–decoder architecture. Since the learned latent space comes from varied human motions, our method can generate a variety of styles of motions given a specific motion label. By means of a novel beginning of sequence (BOS) learning strategy and a self-supervised refinement procedure, our garment simulator is capable of efficiently synthesizing garment deformation sequences corresponding to the generated human motions while maintaining temporal and spatial consistency. We verify our ideas experimentally. This is the first generative model that directly dresses human animation.\\n</p>\",\"PeriodicalId\":37301,\"journal\":{\"name\":\"Computational Visual Media\",\"volume\":\"24 1\",\"pages\":\"\"},\"PeriodicalIF\":18.3000,\"publicationDate\":\"2024-01-03\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Computational Visual Media\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1007/s41095-022-0324-2\",\"RegionNum\":3,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"COMPUTER SCIENCE, SOFTWARE ENGINEERING\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Computational Visual Media","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s41095-022-0324-2","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, SOFTWARE ENGINEERING","Score":null,"Total":0}
Generating diverse clothed 3D human animations via a generative model
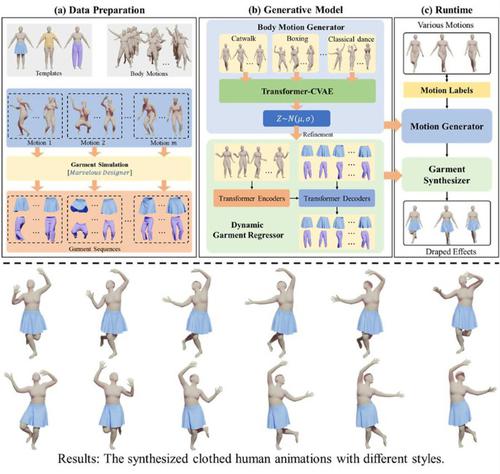
Data-driven garment animation is a current topic of interest in the computer graphics industry. Existing approaches generally establish the mapping between a single human pose or a temporal pose sequence, and garment deformation, but it is difficult to quickly generate diverse clothed human animations. We address this problem with a method to automatically synthesize dressed human animations with temporal consistency from a specified human motion label. At the heart of our method is a two-stage strategy. Specifically, we first learn a latent space encoding the sequence-level distribution of human motions utilizing a transformer-based conditional variational autoencoder (Transformer-CVAE). Then a garment simulator synthesizes dynamic garment shapes using a transformer encoder–decoder architecture. Since the learned latent space comes from varied human motions, our method can generate a variety of styles of motions given a specific motion label. By means of a novel beginning of sequence (BOS) learning strategy and a self-supervised refinement procedure, our garment simulator is capable of efficiently synthesizing garment deformation sequences corresponding to the generated human motions while maintaining temporal and spatial consistency. We verify our ideas experimentally. This is the first generative model that directly dresses human animation.
期刊介绍:
Computational Visual Media is a peer-reviewed open access journal. It publishes original high-quality research papers and significant review articles on novel ideas, methods, and systems relevant to visual media.
Computational Visual Media publishes articles that focus on, but are not limited to, the following areas:
• Editing and composition of visual media
• Geometric computing for images and video
• Geometry modeling and processing
• Machine learning for visual media
• Physically based animation
• Realistic rendering
• Recognition and understanding of visual media
• Visual computing for robotics
• Visualization and visual analytics
Other interdisciplinary research into visual media that combines aspects of computer graphics, computer vision, image and video processing, geometric computing, and machine learning is also within the journal''s scope.
This is an open access journal, published quarterly by Tsinghua University Press and Springer. The open access fees (article-processing charges) are fully sponsored by Tsinghua University, China. Authors can publish in the journal without any additional charges.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


