{"title":"为分层图像分类生成多粒度序列","authors":"Xinda Liu, Lili Wang","doi":"10.1007/s41095-022-0332-2","DOIUrl":null,"url":null,"abstract":"<p>Hierarchical multi-granularity image classification is a challenging task that aims to tag each given image with multiple granularity labels simultaneously. Existing methods tend to overlook that different image regions contribute differently to label prediction at different granularities, and also insufficiently consider relationships between the hierarchical multi-granularity labels. We introduce a sequence-to-sequence mechanism to overcome these two problems and propose a multi-granularity sequence generation (MGSG) approach for the hierarchical multi-granularity image classification task. Specifically, we introduce a transformer architecture to encode the image into visual representation sequences. Next, we traverse the taxonomic tree and organize the multi-granularity labels into sequences, and vectorize them and add positional information. The proposed multi-granularity sequence generation method builds a decoder that takes visual representation sequences and semantic label embedding as inputs, and outputs the predicted multi-granularity label sequence. The decoder models dependencies and correlations between multi-granularity labels through a masked multi-head self-attention mechanism, and relates visual information to the semantic label information through a cross-modality attention mechanism. In this way, the proposed method preserves the relationships between labels at different granularity levels and takes into account the influence of different image regions on labels with different granularities. Evaluations on six public benchmarks qualitatively and quantitatively demonstrate the advantages of the proposed method. Our project is available at https://github.com/liuxindazz/mgsg.\n</p>","PeriodicalId":37301,"journal":{"name":"Computational Visual Media","volume":"19 1","pages":""},"PeriodicalIF":18.3000,"publicationDate":"2024-01-03","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Multi-granularity sequence generation for hierarchical image classification\",\"authors\":\"Xinda Liu, Lili Wang\",\"doi\":\"10.1007/s41095-022-0332-2\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Hierarchical multi-granularity image classification is a challenging task that aims to tag each given image with multiple granularity labels simultaneously. Existing methods tend to overlook that different image regions contribute differently to label prediction at different granularities, and also insufficiently consider relationships between the hierarchical multi-granularity labels. We introduce a sequence-to-sequence mechanism to overcome these two problems and propose a multi-granularity sequence generation (MGSG) approach for the hierarchical multi-granularity image classification task. Specifically, we introduce a transformer architecture to encode the image into visual representation sequences. Next, we traverse the taxonomic tree and organize the multi-granularity labels into sequences, and vectorize them and add positional information. The proposed multi-granularity sequence generation method builds a decoder that takes visual representation sequences and semantic label embedding as inputs, and outputs the predicted multi-granularity label sequence. The decoder models dependencies and correlations between multi-granularity labels through a masked multi-head self-attention mechanism, and relates visual information to the semantic label information through a cross-modality attention mechanism. In this way, the proposed method preserves the relationships between labels at different granularity levels and takes into account the influence of different image regions on labels with different granularities. Evaluations on six public benchmarks qualitatively and quantitatively demonstrate the advantages of the proposed method. Our project is available at https://github.com/liuxindazz/mgsg.\\n</p>\",\"PeriodicalId\":37301,\"journal\":{\"name\":\"Computational Visual Media\",\"volume\":\"19 1\",\"pages\":\"\"},\"PeriodicalIF\":18.3000,\"publicationDate\":\"2024-01-03\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Computational Visual Media\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1007/s41095-022-0332-2\",\"RegionNum\":3,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"COMPUTER SCIENCE, SOFTWARE ENGINEERING\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Computational Visual Media","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s41095-022-0332-2","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, SOFTWARE ENGINEERING","Score":null,"Total":0}
Multi-granularity sequence generation for hierarchical image classification
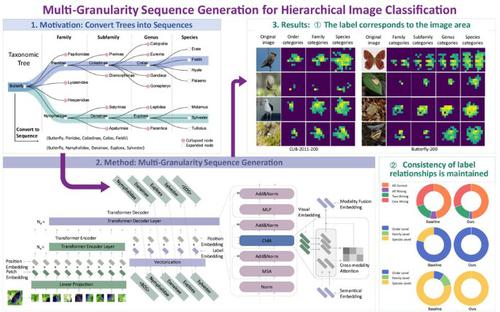
Hierarchical multi-granularity image classification is a challenging task that aims to tag each given image with multiple granularity labels simultaneously. Existing methods tend to overlook that different image regions contribute differently to label prediction at different granularities, and also insufficiently consider relationships between the hierarchical multi-granularity labels. We introduce a sequence-to-sequence mechanism to overcome these two problems and propose a multi-granularity sequence generation (MGSG) approach for the hierarchical multi-granularity image classification task. Specifically, we introduce a transformer architecture to encode the image into visual representation sequences. Next, we traverse the taxonomic tree and organize the multi-granularity labels into sequences, and vectorize them and add positional information. The proposed multi-granularity sequence generation method builds a decoder that takes visual representation sequences and semantic label embedding as inputs, and outputs the predicted multi-granularity label sequence. The decoder models dependencies and correlations between multi-granularity labels through a masked multi-head self-attention mechanism, and relates visual information to the semantic label information through a cross-modality attention mechanism. In this way, the proposed method preserves the relationships between labels at different granularity levels and takes into account the influence of different image regions on labels with different granularities. Evaluations on six public benchmarks qualitatively and quantitatively demonstrate the advantages of the proposed method. Our project is available at https://github.com/liuxindazz/mgsg.
期刊介绍:
Computational Visual Media is a peer-reviewed open access journal. It publishes original high-quality research papers and significant review articles on novel ideas, methods, and systems relevant to visual media.
Computational Visual Media publishes articles that focus on, but are not limited to, the following areas:
• Editing and composition of visual media
• Geometric computing for images and video
• Geometry modeling and processing
• Machine learning for visual media
• Physically based animation
• Realistic rendering
• Recognition and understanding of visual media
• Visual computing for robotics
• Visualization and visual analytics
Other interdisciplinary research into visual media that combines aspects of computer graphics, computer vision, image and video processing, geometric computing, and machine learning is also within the journal''s scope.
This is an open access journal, published quarterly by Tsinghua University Press and Springer. The open access fees (article-processing charges) are fully sponsored by Tsinghua University, China. Authors can publish in the journal without any additional charges.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


