Fenghao Zhang, Lin Zhao, Shengling Li, Wanjuan Su, Liman Liu, Wenbing Tao
{"title":"通过高效的二维线索从单目 RGB 进行三维手部姿势和形状估计","authors":"Fenghao Zhang, Lin Zhao, Shengling Li, Wanjuan Su, Liman Liu, Wenbing Tao","doi":"10.1007/s41095-023-0346-4","DOIUrl":null,"url":null,"abstract":"<p>Estimating 3D hand shape from a single-view RGB image is important for many applications. However, the diversity of hand shapes and postures, depth ambiguity, and occlusion may result in pose errors and noisy hand meshes. Making full use of 2D cues such as 2D pose can effectively improve the quality of 3D human hand shape estimation. In this paper, we use 2D joint heatmaps to obtain spatial details for robust pose estimation. We also introduce a depth-independent 2D mesh to avoid depth ambiguity in mesh regression for efficient hand-image alignment. Our method has four cascaded stages: 2D cue extraction, pose feature encoding, initial reconstruction, and reconstruction refinement. Specifically, we first encode the image to determine semantic features during 2D cue extraction; this is also used to predict hand joints and for segmentation. Then, during the pose feature encoding stage, we use a hand joints encoder to learn spatial information from the joint heatmaps. Next, a coarse 3D hand mesh and 2D mesh are obtained in the initial reconstruction step; a mesh squeeze-and-excitation block is used to fuse different hand features to enhance perception of 3D hand structures. Finally, a global mesh refinement stage learns non-local relations between vertices of the hand mesh from the predicted 2D mesh, to predict an offset hand mesh to fine-tune the reconstruction results. Quantitative and qualitative results on the FreiHAND benchmark dataset demonstrate that our approach achieves state-of-the-art performance.\n</p>","PeriodicalId":37301,"journal":{"name":"Computational Visual Media","volume":"26 1","pages":""},"PeriodicalIF":18.3000,"publicationDate":"2023-11-30","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"3D hand pose and shape estimation from monocular RGB via efficient 2D cues\",\"authors\":\"Fenghao Zhang, Lin Zhao, Shengling Li, Wanjuan Su, Liman Liu, Wenbing Tao\",\"doi\":\"10.1007/s41095-023-0346-4\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Estimating 3D hand shape from a single-view RGB image is important for many applications. However, the diversity of hand shapes and postures, depth ambiguity, and occlusion may result in pose errors and noisy hand meshes. Making full use of 2D cues such as 2D pose can effectively improve the quality of 3D human hand shape estimation. In this paper, we use 2D joint heatmaps to obtain spatial details for robust pose estimation. We also introduce a depth-independent 2D mesh to avoid depth ambiguity in mesh regression for efficient hand-image alignment. Our method has four cascaded stages: 2D cue extraction, pose feature encoding, initial reconstruction, and reconstruction refinement. Specifically, we first encode the image to determine semantic features during 2D cue extraction; this is also used to predict hand joints and for segmentation. Then, during the pose feature encoding stage, we use a hand joints encoder to learn spatial information from the joint heatmaps. Next, a coarse 3D hand mesh and 2D mesh are obtained in the initial reconstruction step; a mesh squeeze-and-excitation block is used to fuse different hand features to enhance perception of 3D hand structures. Finally, a global mesh refinement stage learns non-local relations between vertices of the hand mesh from the predicted 2D mesh, to predict an offset hand mesh to fine-tune the reconstruction results. Quantitative and qualitative results on the FreiHAND benchmark dataset demonstrate that our approach achieves state-of-the-art performance.\\n</p>\",\"PeriodicalId\":37301,\"journal\":{\"name\":\"Computational Visual Media\",\"volume\":\"26 1\",\"pages\":\"\"},\"PeriodicalIF\":18.3000,\"publicationDate\":\"2023-11-30\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Computational Visual Media\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1007/s41095-023-0346-4\",\"RegionNum\":3,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"COMPUTER SCIENCE, SOFTWARE ENGINEERING\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Computational Visual Media","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s41095-023-0346-4","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, SOFTWARE ENGINEERING","Score":null,"Total":0}
3D hand pose and shape estimation from monocular RGB via efficient 2D cues
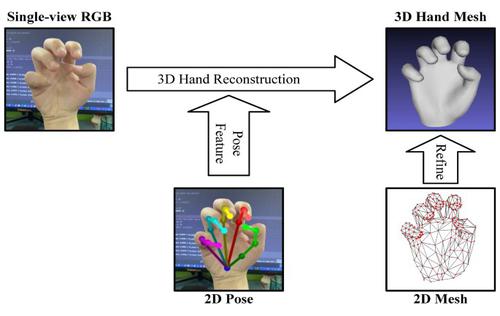
Estimating 3D hand shape from a single-view RGB image is important for many applications. However, the diversity of hand shapes and postures, depth ambiguity, and occlusion may result in pose errors and noisy hand meshes. Making full use of 2D cues such as 2D pose can effectively improve the quality of 3D human hand shape estimation. In this paper, we use 2D joint heatmaps to obtain spatial details for robust pose estimation. We also introduce a depth-independent 2D mesh to avoid depth ambiguity in mesh regression for efficient hand-image alignment. Our method has four cascaded stages: 2D cue extraction, pose feature encoding, initial reconstruction, and reconstruction refinement. Specifically, we first encode the image to determine semantic features during 2D cue extraction; this is also used to predict hand joints and for segmentation. Then, during the pose feature encoding stage, we use a hand joints encoder to learn spatial information from the joint heatmaps. Next, a coarse 3D hand mesh and 2D mesh are obtained in the initial reconstruction step; a mesh squeeze-and-excitation block is used to fuse different hand features to enhance perception of 3D hand structures. Finally, a global mesh refinement stage learns non-local relations between vertices of the hand mesh from the predicted 2D mesh, to predict an offset hand mesh to fine-tune the reconstruction results. Quantitative and qualitative results on the FreiHAND benchmark dataset demonstrate that our approach achieves state-of-the-art performance.
期刊介绍:
Computational Visual Media is a peer-reviewed open access journal. It publishes original high-quality research papers and significant review articles on novel ideas, methods, and systems relevant to visual media.
Computational Visual Media publishes articles that focus on, but are not limited to, the following areas:
• Editing and composition of visual media
• Geometric computing for images and video
• Geometry modeling and processing
• Machine learning for visual media
• Physically based animation
• Realistic rendering
• Recognition and understanding of visual media
• Visual computing for robotics
• Visualization and visual analytics
Other interdisciplinary research into visual media that combines aspects of computer graphics, computer vision, image and video processing, geometric computing, and machine learning is also within the journal''s scope.
This is an open access journal, published quarterly by Tsinghua University Press and Springer. The open access fees (article-processing charges) are fully sponsored by Tsinghua University, China. Authors can publish in the journal without any additional charges.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


