Mia Harada-Laszlo, Anahita Talwar, Oliver J. Robinson, Alexandra C. Pike
{"title":"一系列不幸事件:灾难化的人在经历负面结果后会学到更多东西吗?","authors":"Mia Harada-Laszlo, Anahita Talwar, Oliver J. Robinson, Alexandra C. Pike","doi":"10.1002/mhs2.49","DOIUrl":null,"url":null,"abstract":"<p>Catastrophizing is a transdiagnostic construct that has been suggested to precipitate and maintain a multiplicity of psychiatric disorders, including anxiety, depression, post-traumatic stress disorder, and obsessive-compulsive disorder. However, the underlying cognitive mechanisms that result in catastrophizing are unknown. Relating reinforcement learning model parameters to catastrophizing may allow us to further understand the process of catastrophizing. Using a modified four-armed bandit task, we aimed to investigate the relationship between reinforcement learning parameters and self-report catastrophizing questionnaire scores to gain a mechanistic understanding of how catastrophizing may alter learning. We recruited 211 participants to complete a computerized four-armed bandit task and tested the fit of six reinforcement learning models on our data, including two novel models which both incorporated a scaling factor related to a <i>history of negative outcomes</i> variable. We investigated the relationship between self-report catastrophizing scores and free parameters from the overall best-fitting model, along with the best-fitting model to include <i>history</i>, using Pearson's correlations. Subsequently, we reassessed these relationships using multiple regression analyses to evaluate whether any observed relationships were altered when relevant IQ and mental health covariates were applied. Model-agnostic analyses indicated there were effects of outcome history on reaction time and accuracy, and that the effects on accuracy related to catastrophizing. The overall model of best fit was the Standard Rescorla–Wagner Model and the best-fitting model to include <i>history</i> was a model in which learning rate was scaled by history of negative outcome. We found no effect of catastrophizing on the scaling by history of negative outcome parameter (<i>r</i> = 0.003, <i>p</i> = 0.679), the learning rate parameter (<i>r</i> = 0.026, <i>p</i> = 0.703), or the inverse temperature parameter (<i>r</i> = 0.086, <i>p</i> = 0.220). We were unable to relate catastrophizing to any of the reinforcement learning parameters we investigated. This implies that catastrophizing is not straightforwardly linked to any changes to learning after a series of negative outcomes are received. Future research could incorporate further exploration of the space of models which include a <i>history</i> parameter.</p>","PeriodicalId":94140,"journal":{"name":"Mental health science","volume":"2 1","pages":"73-84"},"PeriodicalIF":0.0000,"publicationDate":"2023-12-11","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1002/mhs2.49","citationCount":"0","resultStr":"{\"title\":\"A series of unfortunate events: Do those who catastrophize learn more after negative outcomes?\",\"authors\":\"Mia Harada-Laszlo, Anahita Talwar, Oliver J. Robinson, Alexandra C. Pike\",\"doi\":\"10.1002/mhs2.49\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Catastrophizing is a transdiagnostic construct that has been suggested to precipitate and maintain a multiplicity of psychiatric disorders, including anxiety, depression, post-traumatic stress disorder, and obsessive-compulsive disorder. However, the underlying cognitive mechanisms that result in catastrophizing are unknown. Relating reinforcement learning model parameters to catastrophizing may allow us to further understand the process of catastrophizing. Using a modified four-armed bandit task, we aimed to investigate the relationship between reinforcement learning parameters and self-report catastrophizing questionnaire scores to gain a mechanistic understanding of how catastrophizing may alter learning. We recruited 211 participants to complete a computerized four-armed bandit task and tested the fit of six reinforcement learning models on our data, including two novel models which both incorporated a scaling factor related to a <i>history of negative outcomes</i> variable. We investigated the relationship between self-report catastrophizing scores and free parameters from the overall best-fitting model, along with the best-fitting model to include <i>history</i>, using Pearson's correlations. Subsequently, we reassessed these relationships using multiple regression analyses to evaluate whether any observed relationships were altered when relevant IQ and mental health covariates were applied. Model-agnostic analyses indicated there were effects of outcome history on reaction time and accuracy, and that the effects on accuracy related to catastrophizing. The overall model of best fit was the Standard Rescorla–Wagner Model and the best-fitting model to include <i>history</i> was a model in which learning rate was scaled by history of negative outcome. We found no effect of catastrophizing on the scaling by history of negative outcome parameter (<i>r</i> = 0.003, <i>p</i> = 0.679), the learning rate parameter (<i>r</i> = 0.026, <i>p</i> = 0.703), or the inverse temperature parameter (<i>r</i> = 0.086, <i>p</i> = 0.220). We were unable to relate catastrophizing to any of the reinforcement learning parameters we investigated. This implies that catastrophizing is not straightforwardly linked to any changes to learning after a series of negative outcomes are received. Future research could incorporate further exploration of the space of models which include a <i>history</i> parameter.</p>\",\"PeriodicalId\":94140,\"journal\":{\"name\":\"Mental health science\",\"volume\":\"2 1\",\"pages\":\"73-84\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2023-12-11\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://onlinelibrary.wiley.com/doi/epdf/10.1002/mhs2.49\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Mental health science\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://onlinelibrary.wiley.com/doi/10.1002/mhs2.49\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Mental health science","FirstCategoryId":"1085","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1002/mhs2.49","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
A series of unfortunate events: Do those who catastrophize learn more after negative outcomes?
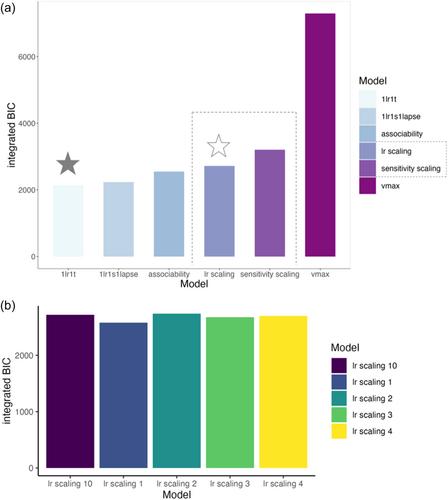
Catastrophizing is a transdiagnostic construct that has been suggested to precipitate and maintain a multiplicity of psychiatric disorders, including anxiety, depression, post-traumatic stress disorder, and obsessive-compulsive disorder. However, the underlying cognitive mechanisms that result in catastrophizing are unknown. Relating reinforcement learning model parameters to catastrophizing may allow us to further understand the process of catastrophizing. Using a modified four-armed bandit task, we aimed to investigate the relationship between reinforcement learning parameters and self-report catastrophizing questionnaire scores to gain a mechanistic understanding of how catastrophizing may alter learning. We recruited 211 participants to complete a computerized four-armed bandit task and tested the fit of six reinforcement learning models on our data, including two novel models which both incorporated a scaling factor related to a history of negative outcomes variable. We investigated the relationship between self-report catastrophizing scores and free parameters from the overall best-fitting model, along with the best-fitting model to include history, using Pearson's correlations. Subsequently, we reassessed these relationships using multiple regression analyses to evaluate whether any observed relationships were altered when relevant IQ and mental health covariates were applied. Model-agnostic analyses indicated there were effects of outcome history on reaction time and accuracy, and that the effects on accuracy related to catastrophizing. The overall model of best fit was the Standard Rescorla–Wagner Model and the best-fitting model to include history was a model in which learning rate was scaled by history of negative outcome. We found no effect of catastrophizing on the scaling by history of negative outcome parameter (r = 0.003, p = 0.679), the learning rate parameter (r = 0.026, p = 0.703), or the inverse temperature parameter (r = 0.086, p = 0.220). We were unable to relate catastrophizing to any of the reinforcement learning parameters we investigated. This implies that catastrophizing is not straightforwardly linked to any changes to learning after a series of negative outcomes are received. Future research could incorporate further exploration of the space of models which include a history parameter.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


