Segun Taofeek Aroyehun, Lukas Malik, Hannah Metzler, Nikolas Haimerl, Anna Di Natale, David Garcia
{"title":"情感识别的语言嵌入。","authors":"Segun Taofeek Aroyehun, Lukas Malik, Hannah Metzler, Nikolas Haimerl, Anna Di Natale, David Garcia","doi":"10.1140/epjds/s13688-023-00427-0","DOIUrl":null,"url":null,"abstract":"<p><p>The wealth of text data generated by social media has enabled new kinds of analysis of emotions with language models. These models are often trained on small and costly datasets of text annotations produced by readers who guess the emotions expressed by others in social media posts. This affects the quality of emotion identification methods due to training data size limitations and noise in the production of labels used in model development. We present LEIA, a model for emotion identification in text that has been trained on a dataset of more than 6 million posts with self-annotated emotion labels for happiness, affection, sadness, anger, and fear. LEIA is based on a word masking method that enhances the learning of emotion words during model pre-training. LEIA achieves macro-F1 values of approximately 73 on three in-domain test datasets, outperforming other supervised and unsupervised methods in a strong benchmark that shows that LEIA generalizes across posts, users, and time periods. We further perform an out-of-domain evaluation on five different datasets of social media and other sources, showing LEIA's robust performance across media, data collection methods, and annotation schemes. Our results show that LEIA generalizes its classification of anger, happiness, and sadness beyond the domain it was trained on. LEIA can be applied in future research to provide better identification of emotions in text from the perspective of the writer.</p>","PeriodicalId":11887,"journal":{"name":"EPJ Data Science","volume":"12 1","pages":"52"},"PeriodicalIF":2.5000,"publicationDate":"2023-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10654159/pdf/","citationCount":"0","resultStr":"{\"title\":\"LEIA: Linguistic Embeddings for the Identification of Affect.\",\"authors\":\"Segun Taofeek Aroyehun, Lukas Malik, Hannah Metzler, Nikolas Haimerl, Anna Di Natale, David Garcia\",\"doi\":\"10.1140/epjds/s13688-023-00427-0\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>The wealth of text data generated by social media has enabled new kinds of analysis of emotions with language models. These models are often trained on small and costly datasets of text annotations produced by readers who guess the emotions expressed by others in social media posts. This affects the quality of emotion identification methods due to training data size limitations and noise in the production of labels used in model development. We present LEIA, a model for emotion identification in text that has been trained on a dataset of more than 6 million posts with self-annotated emotion labels for happiness, affection, sadness, anger, and fear. LEIA is based on a word masking method that enhances the learning of emotion words during model pre-training. LEIA achieves macro-F1 values of approximately 73 on three in-domain test datasets, outperforming other supervised and unsupervised methods in a strong benchmark that shows that LEIA generalizes across posts, users, and time periods. We further perform an out-of-domain evaluation on five different datasets of social media and other sources, showing LEIA's robust performance across media, data collection methods, and annotation schemes. Our results show that LEIA generalizes its classification of anger, happiness, and sadness beyond the domain it was trained on. LEIA can be applied in future research to provide better identification of emotions in text from the perspective of the writer.</p>\",\"PeriodicalId\":11887,\"journal\":{\"name\":\"EPJ Data Science\",\"volume\":\"12 1\",\"pages\":\"52\"},\"PeriodicalIF\":2.5000,\"publicationDate\":\"2023-01-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10654159/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"EPJ Data Science\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1140/epjds/s13688-023-00427-0\",\"RegionNum\":2,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2023/11/16 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q1\",\"JCRName\":\"MATHEMATICS, INTERDISCIPLINARY APPLICATIONS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"EPJ Data Science","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1140/epjds/s13688-023-00427-0","RegionNum":2,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2023/11/16 0:00:00","PubModel":"Epub","JCR":"Q1","JCRName":"MATHEMATICS, INTERDISCIPLINARY APPLICATIONS","Score":null,"Total":0}
LEIA: Linguistic Embeddings for the Identification of Affect.
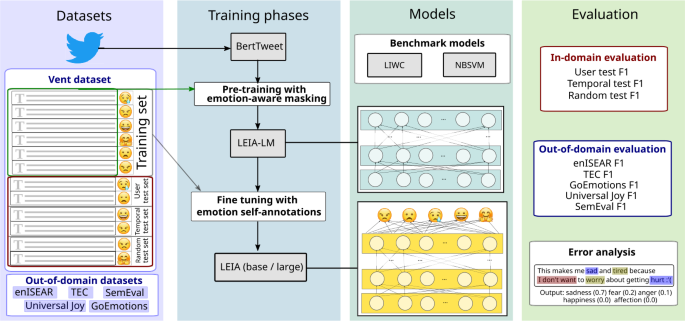
The wealth of text data generated by social media has enabled new kinds of analysis of emotions with language models. These models are often trained on small and costly datasets of text annotations produced by readers who guess the emotions expressed by others in social media posts. This affects the quality of emotion identification methods due to training data size limitations and noise in the production of labels used in model development. We present LEIA, a model for emotion identification in text that has been trained on a dataset of more than 6 million posts with self-annotated emotion labels for happiness, affection, sadness, anger, and fear. LEIA is based on a word masking method that enhances the learning of emotion words during model pre-training. LEIA achieves macro-F1 values of approximately 73 on three in-domain test datasets, outperforming other supervised and unsupervised methods in a strong benchmark that shows that LEIA generalizes across posts, users, and time periods. We further perform an out-of-domain evaluation on five different datasets of social media and other sources, showing LEIA's robust performance across media, data collection methods, and annotation schemes. Our results show that LEIA generalizes its classification of anger, happiness, and sadness beyond the domain it was trained on. LEIA can be applied in future research to provide better identification of emotions in text from the perspective of the writer.
期刊介绍:
EPJ Data Science covers a broad range of research areas and applications and particularly encourages contributions from techno-socio-economic systems, where it comprises those research lines that now regard the digital “tracks” of human beings as first-order objects for scientific investigation. Topics include, but are not limited to, human behavior, social interaction (including animal societies), economic and financial systems, management and business networks, socio-technical infrastructure, health and environmental systems, the science of science, as well as general risk and crisis scenario forecasting up to and including policy advice.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


