Ulla Petti, Simon Baker, Anna Korhonen, Jessica Robin
{"title":"追踪阿尔茨海默病患者的语言变化需要多少语音数据?随机长度、5分钟和1分钟自发语音样本的比较。","authors":"Ulla Petti, Simon Baker, Anna Korhonen, Jessica Robin","doi":"10.1159/000533423","DOIUrl":null,"url":null,"abstract":"<p><strong>Introduction: </strong>Changes in speech can act as biomarkers of cognitive decline in Alzheimer's disease (AD). While shorter speech samples would promote data collection and analysis, the minimum length of informative speech samples remains debated. This study aims to provide insight into the effect of sample length in analyzing longitudinal recordings of spontaneous speech in AD by comparing the original random length, 5- and 1-minute-long samples. We hope to understand whether capping the audio improves the accuracy of the analysis, and whether an extra 4 min conveys necessary information.</p><p><strong>Methods: </strong>110 spontaneous speech samples were collected from decades of Youtube videos of 17 public figures, 9 of whom eventually developed AD. 456 language features were extracted and their text-length-sensitivity, comparability, and ability to capture change over time were analyzed across three different sample lengths.</p><p><strong>Results: </strong>Capped audio files had advantages over the random length ones. While most extracted features were statistically comparable or highly correlated across the datasets, potential effects of sample length should be acknowledged for some features. The 5-min dataset presented the highest reliability in tracking the evolution of the disease, suggesting that the 4 extra minutes do convey informative data.</p><p><strong>Conclusion: </strong>Sample length seems to play an important role in extracting the language feature values from speech and tracking disease progress over time. We highlight the importance of further research into optimal sample length and standardization of methods when studying speech in AD.</p>","PeriodicalId":11242,"journal":{"name":"Digital Biomarkers","volume":"7 1","pages":"157-166"},"PeriodicalIF":0.0000,"publicationDate":"2023-11-24","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10673351/pdf/","citationCount":"0","resultStr":"{\"title\":\"How Much Speech Data Is Needed for Tracking Language Change in Alzheimer's Disease? A Comparison of Random Length, 5-Min, and 1-Min Spontaneous Speech Samples.\",\"authors\":\"Ulla Petti, Simon Baker, Anna Korhonen, Jessica Robin\",\"doi\":\"10.1159/000533423\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Introduction: </strong>Changes in speech can act as biomarkers of cognitive decline in Alzheimer's disease (AD). While shorter speech samples would promote data collection and analysis, the minimum length of informative speech samples remains debated. This study aims to provide insight into the effect of sample length in analyzing longitudinal recordings of spontaneous speech in AD by comparing the original random length, 5- and 1-minute-long samples. We hope to understand whether capping the audio improves the accuracy of the analysis, and whether an extra 4 min conveys necessary information.</p><p><strong>Methods: </strong>110 spontaneous speech samples were collected from decades of Youtube videos of 17 public figures, 9 of whom eventually developed AD. 456 language features were extracted and their text-length-sensitivity, comparability, and ability to capture change over time were analyzed across three different sample lengths.</p><p><strong>Results: </strong>Capped audio files had advantages over the random length ones. While most extracted features were statistically comparable or highly correlated across the datasets, potential effects of sample length should be acknowledged for some features. The 5-min dataset presented the highest reliability in tracking the evolution of the disease, suggesting that the 4 extra minutes do convey informative data.</p><p><strong>Conclusion: </strong>Sample length seems to play an important role in extracting the language feature values from speech and tracking disease progress over time. We highlight the importance of further research into optimal sample length and standardization of methods when studying speech in AD.</p>\",\"PeriodicalId\":11242,\"journal\":{\"name\":\"Digital Biomarkers\",\"volume\":\"7 1\",\"pages\":\"157-166\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2023-11-24\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10673351/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Digital Biomarkers\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1159/000533423\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2023/1/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"Q1\",\"JCRName\":\"Computer Science\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Digital Biomarkers","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1159/000533423","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2023/1/1 0:00:00","PubModel":"eCollection","JCR":"Q1","JCRName":"Computer Science","Score":null,"Total":0}
How Much Speech Data Is Needed for Tracking Language Change in Alzheimer's Disease? A Comparison of Random Length, 5-Min, and 1-Min Spontaneous Speech Samples.
Introduction: Changes in speech can act as biomarkers of cognitive decline in Alzheimer's disease (AD). While shorter speech samples would promote data collection and analysis, the minimum length of informative speech samples remains debated. This study aims to provide insight into the effect of sample length in analyzing longitudinal recordings of spontaneous speech in AD by comparing the original random length, 5- and 1-minute-long samples. We hope to understand whether capping the audio improves the accuracy of the analysis, and whether an extra 4 min conveys necessary information.
Methods: 110 spontaneous speech samples were collected from decades of Youtube videos of 17 public figures, 9 of whom eventually developed AD. 456 language features were extracted and their text-length-sensitivity, comparability, and ability to capture change over time were analyzed across three different sample lengths.
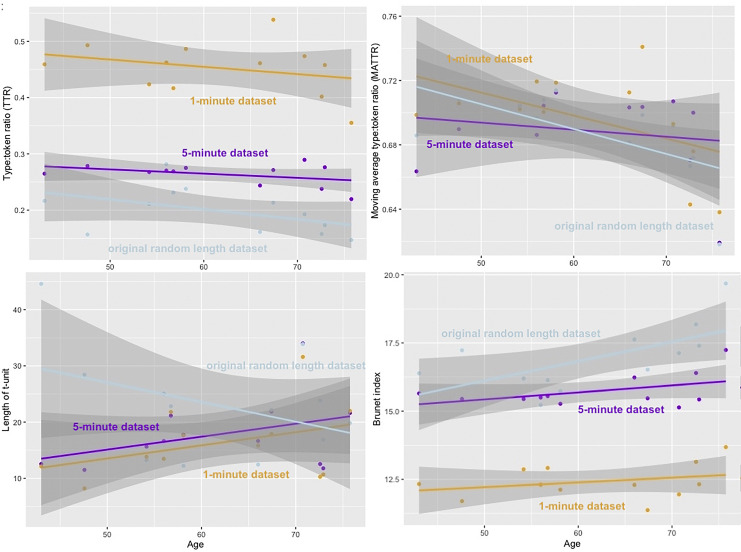
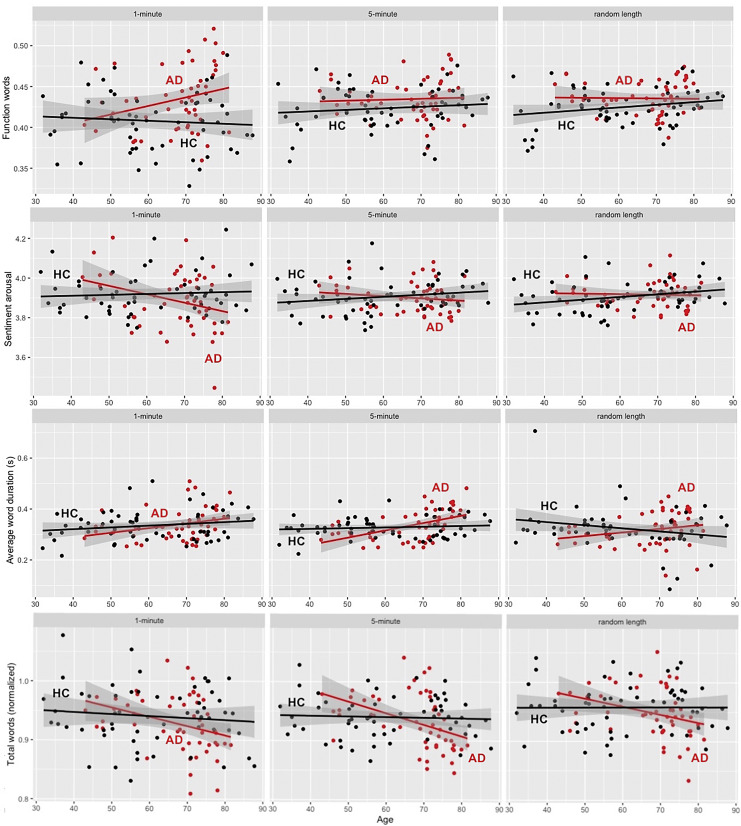
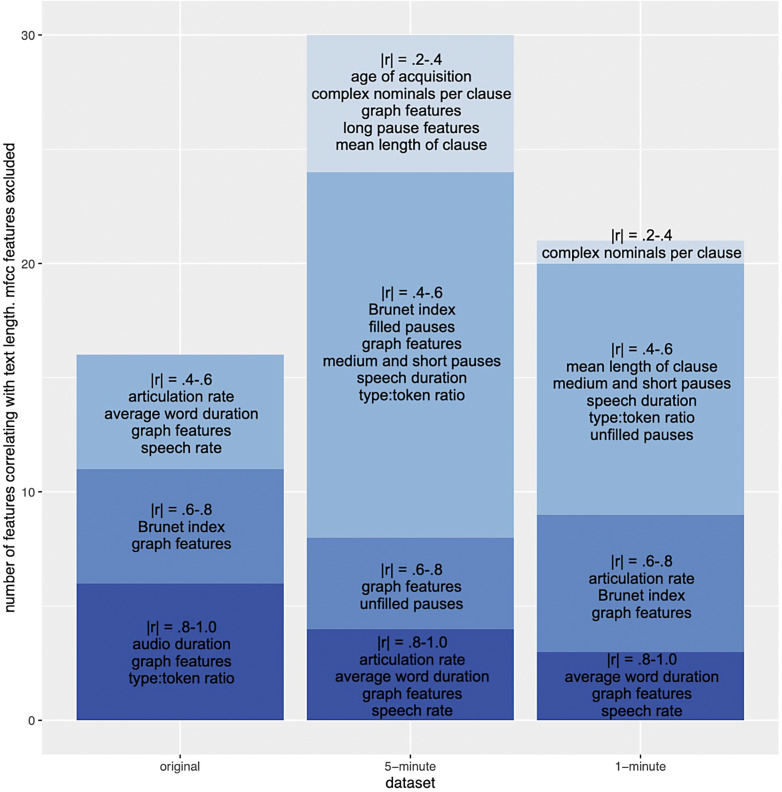
Results: Capped audio files had advantages over the random length ones. While most extracted features were statistically comparable or highly correlated across the datasets, potential effects of sample length should be acknowledged for some features. The 5-min dataset presented the highest reliability in tracking the evolution of the disease, suggesting that the 4 extra minutes do convey informative data.
Conclusion: Sample length seems to play an important role in extracting the language feature values from speech and tracking disease progress over time. We highlight the importance of further research into optimal sample length and standardization of methods when studying speech in AD.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


