Hao Ma, Dieter Büchler, Bernhard Schölkopf, Michael Muehlebach
{"title":"基于模型前馈输入的乒乓球机器人强化学习","authors":"Hao Ma, Dieter Büchler, Bernhard Schölkopf, Michael Muehlebach","doi":"10.1007/s10514-023-10140-6","DOIUrl":null,"url":null,"abstract":"<div><p>We rethink the traditional reinforcement learning approach, which is based on optimizing over feedback policies, and propose a new framework that optimizes over feedforward inputs instead. This not only mitigates the risk of destabilizing the system during training but also reduces the bulk of the learning to a supervised learning task. As a result, efficient and well-understood supervised learning techniques can be applied and are tuned using a validation data set. The labels are generated with a variant of iterative learning control, which also includes prior knowledge about the underlying dynamics. Our framework is applied for intercepting and returning ping-pong balls that are played to a four-degrees-of-freedom robotic arm in real-world experiments. The robot arm is driven by pneumatic artificial muscles, which makes the control and learning tasks challenging. We highlight the potential of our framework by comparing it to a reinforcement learning approach that optimizes over feedback policies. We find that our framework achieves a higher success rate for the returns (<span>\\(100\\%\\)</span> vs. <span>\\(96\\%\\)</span>, on 107 consecutive trials, see https://youtu.be/kR9jowEH7PY) while requiring only about one tenth of the samples during training. We also find that our approach is able to deal with a variant of different incoming trajectories.\n</p></div>","PeriodicalId":55409,"journal":{"name":"Autonomous Robots","volume":"47 8","pages":"1387 - 1403"},"PeriodicalIF":4.3000,"publicationDate":"2023-10-17","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://link.springer.com/content/pdf/10.1007/s10514-023-10140-6.pdf","citationCount":"0","resultStr":"{\"title\":\"Reinforcement learning with model-based feedforward inputs for robotic table tennis\",\"authors\":\"Hao Ma, Dieter Büchler, Bernhard Schölkopf, Michael Muehlebach\",\"doi\":\"10.1007/s10514-023-10140-6\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><p>We rethink the traditional reinforcement learning approach, which is based on optimizing over feedback policies, and propose a new framework that optimizes over feedforward inputs instead. This not only mitigates the risk of destabilizing the system during training but also reduces the bulk of the learning to a supervised learning task. As a result, efficient and well-understood supervised learning techniques can be applied and are tuned using a validation data set. The labels are generated with a variant of iterative learning control, which also includes prior knowledge about the underlying dynamics. Our framework is applied for intercepting and returning ping-pong balls that are played to a four-degrees-of-freedom robotic arm in real-world experiments. The robot arm is driven by pneumatic artificial muscles, which makes the control and learning tasks challenging. We highlight the potential of our framework by comparing it to a reinforcement learning approach that optimizes over feedback policies. We find that our framework achieves a higher success rate for the returns (<span>\\\\(100\\\\%\\\\)</span> vs. <span>\\\\(96\\\\%\\\\)</span>, on 107 consecutive trials, see https://youtu.be/kR9jowEH7PY) while requiring only about one tenth of the samples during training. We also find that our approach is able to deal with a variant of different incoming trajectories.\\n</p></div>\",\"PeriodicalId\":55409,\"journal\":{\"name\":\"Autonomous Robots\",\"volume\":\"47 8\",\"pages\":\"1387 - 1403\"},\"PeriodicalIF\":4.3000,\"publicationDate\":\"2023-10-17\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://link.springer.com/content/pdf/10.1007/s10514-023-10140-6.pdf\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Autonomous Robots\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://link.springer.com/article/10.1007/s10514-023-10140-6\",\"RegionNum\":3,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Autonomous Robots","FirstCategoryId":"94","ListUrlMain":"https://link.springer.com/article/10.1007/s10514-023-10140-6","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 0
摘要
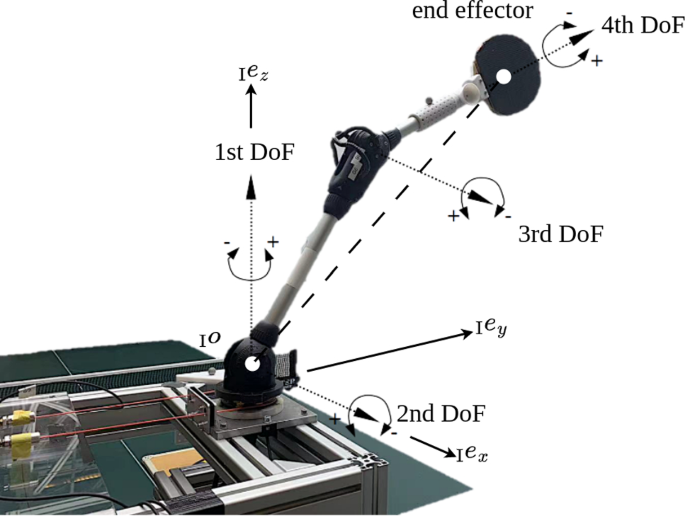
我们重新思考了传统的基于反馈策略优化的强化学习方法,并提出了一个新的框架来优化前馈输入。这不仅降低了在训练期间系统不稳定的风险,而且还减少了大量的学习到监督学习任务。因此,可以应用高效且易于理解的监督学习技术,并使用验证数据集进行调优。标签是用迭代学习控制的一种变体生成的,它还包括关于潜在动力学的先验知识。我们的框架在现实世界的实验中被应用于乒乓球的拦截和返回,乒乓球被打给一个四自由度的机械臂。机器人手臂由气动人造肌肉驱动,这使得控制和学习任务具有挑战性。我们通过将其与优化反馈策略的强化学习方法进行比较,突出了我们框架的潜力。我们发现我们的框架在107次连续试验中获得了更高的成功率(\(100\%\) vs. \(96\%\),见https://youtu.be/kR9jowEH7PY),而在训练期间只需要大约十分之一的样本。我们还发现,我们的方法能够处理各种不同的入射轨迹。
Reinforcement learning with model-based feedforward inputs for robotic table tennis
We rethink the traditional reinforcement learning approach, which is based on optimizing over feedback policies, and propose a new framework that optimizes over feedforward inputs instead. This not only mitigates the risk of destabilizing the system during training but also reduces the bulk of the learning to a supervised learning task. As a result, efficient and well-understood supervised learning techniques can be applied and are tuned using a validation data set. The labels are generated with a variant of iterative learning control, which also includes prior knowledge about the underlying dynamics. Our framework is applied for intercepting and returning ping-pong balls that are played to a four-degrees-of-freedom robotic arm in real-world experiments. The robot arm is driven by pneumatic artificial muscles, which makes the control and learning tasks challenging. We highlight the potential of our framework by comparing it to a reinforcement learning approach that optimizes over feedback policies. We find that our framework achieves a higher success rate for the returns (\(100\%\) vs. \(96\%\), on 107 consecutive trials, see https://youtu.be/kR9jowEH7PY) while requiring only about one tenth of the samples during training. We also find that our approach is able to deal with a variant of different incoming trajectories.
期刊介绍:
Autonomous Robots reports on the theory and applications of robotic systems capable of some degree of self-sufficiency. It features papers that include performance data on actual robots in the real world. Coverage includes: control of autonomous robots · real-time vision · autonomous wheeled and tracked vehicles · legged vehicles · computational architectures for autonomous systems · distributed architectures for learning, control and adaptation · studies of autonomous robot systems · sensor fusion · theory of autonomous systems · terrain mapping and recognition · self-calibration and self-repair for robots · self-reproducing intelligent structures · genetic algorithms as models for robot development.
The focus is on the ability to move and be self-sufficient, not on whether the system is an imitation of biology. Of course, biological models for robotic systems are of major interest to the journal since living systems are prototypes for autonomous behavior.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


