Min Pan, Teng Li, Yu Liu, Quanli Pei, Ellen Anne Huang, Jimmy X. Huang
{"title":"具有抽象概括功能的语义增强型文本检索框架","authors":"Min Pan, Teng Li, Yu Liu, Quanli Pei, Ellen Anne Huang, Jimmy X. Huang","doi":"10.1111/coin.12603","DOIUrl":null,"url":null,"abstract":"<p>Recently, large pretrained language models (PLMs) have led a revolution in the information retrieval community. In most PLMs-based retrieval frameworks, the ranking performance broadly depends on the model structure and the semantic complexity of the input text. Sequence-to-sequence generative models for question answering or text generation have proven to be competitive, so we wonder whether these models can improve ranking effectiveness by enhancing input semantics. This article introduces SE-BERT, a semantically enhanced bidirectional encoder representation from transformers (BERT) based ranking framework that captures more semantic information by modifying the input text. SE-BERT utilizes a pretrained generative language model to summarize both sides of the candidate passage and concatenate them into a new input sequence, allowing BERT to acquire more semantic information within the constraints of the input sequence's length. Experimental results from two Text Retrieval Conference datasets demonstrate that our approach's effectiveness increasing as the length of the input text increases.</p>","PeriodicalId":55228,"journal":{"name":"Computational Intelligence","volume":"40 1","pages":""},"PeriodicalIF":1.8000,"publicationDate":"2023-09-28","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1111/coin.12603","citationCount":"0","resultStr":"{\"title\":\"A semantically enhanced text retrieval framework with abstractive summarization\",\"authors\":\"Min Pan, Teng Li, Yu Liu, Quanli Pei, Ellen Anne Huang, Jimmy X. Huang\",\"doi\":\"10.1111/coin.12603\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Recently, large pretrained language models (PLMs) have led a revolution in the information retrieval community. In most PLMs-based retrieval frameworks, the ranking performance broadly depends on the model structure and the semantic complexity of the input text. Sequence-to-sequence generative models for question answering or text generation have proven to be competitive, so we wonder whether these models can improve ranking effectiveness by enhancing input semantics. This article introduces SE-BERT, a semantically enhanced bidirectional encoder representation from transformers (BERT) based ranking framework that captures more semantic information by modifying the input text. SE-BERT utilizes a pretrained generative language model to summarize both sides of the candidate passage and concatenate them into a new input sequence, allowing BERT to acquire more semantic information within the constraints of the input sequence's length. Experimental results from two Text Retrieval Conference datasets demonstrate that our approach's effectiveness increasing as the length of the input text increases.</p>\",\"PeriodicalId\":55228,\"journal\":{\"name\":\"Computational Intelligence\",\"volume\":\"40 1\",\"pages\":\"\"},\"PeriodicalIF\":1.8000,\"publicationDate\":\"2023-09-28\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://onlinelibrary.wiley.com/doi/epdf/10.1111/coin.12603\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Computational Intelligence\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://onlinelibrary.wiley.com/doi/10.1111/coin.12603\",\"RegionNum\":4,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q3\",\"JCRName\":\"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Computational Intelligence","FirstCategoryId":"94","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1111/coin.12603","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
A semantically enhanced text retrieval framework with abstractive summarization
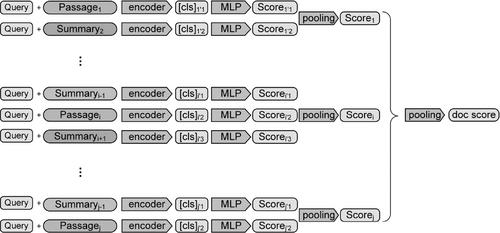
Recently, large pretrained language models (PLMs) have led a revolution in the information retrieval community. In most PLMs-based retrieval frameworks, the ranking performance broadly depends on the model structure and the semantic complexity of the input text. Sequence-to-sequence generative models for question answering or text generation have proven to be competitive, so we wonder whether these models can improve ranking effectiveness by enhancing input semantics. This article introduces SE-BERT, a semantically enhanced bidirectional encoder representation from transformers (BERT) based ranking framework that captures more semantic information by modifying the input text. SE-BERT utilizes a pretrained generative language model to summarize both sides of the candidate passage and concatenate them into a new input sequence, allowing BERT to acquire more semantic information within the constraints of the input sequence's length. Experimental results from two Text Retrieval Conference datasets demonstrate that our approach's effectiveness increasing as the length of the input text increases.
期刊介绍:
This leading international journal promotes and stimulates research in the field of artificial intelligence (AI). Covering a wide range of issues - from the tools and languages of AI to its philosophical implications - Computational Intelligence provides a vigorous forum for the publication of both experimental and theoretical research, as well as surveys and impact studies. The journal is designed to meet the needs of a wide range of AI workers in academic and industrial research.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


