{"title":"在COVID-19疫情期间,发现可能线索以预测误导性信息的框架激增。","authors":"Deepika Varshney, Dinesh Kumar Vishwakarma","doi":"10.1007/s00521-022-07938-3","DOIUrl":null,"url":null,"abstract":"<p><p>Spreading of misleading information on social web platforms has fuelled huge panic and confusion among the public regarding the Corona disease, the detection of which is of paramount importance. To identify the credibility of the posted claim, we have analyzed possible evidence from the news articles in the google search results. This paper proposes an intelligent and expert strategy to gather important clues from the top 10 google search results related to the claim. The N-gram, Levenshtein Distance, and Word-Similarity-based features are used to identify the clues from the news article that can automatically warn users against spreading false news if no significant supportive clues are identified concerning that claim. The complete process is done in four steps, wherein the first step we build a query from the posted claim received in the form of text or text additive images which further goes as an input to the search query phase, where the top 10 google results are processed. In the third step, the important clues are extracted from titles of the top 10 news articles. Lastly, useful pieces of evidence are extracted from the content of each news article. All the useful clues with respect to N-gram, Levenshtein Distance, and Word Similarity are finally fed into the machine learning model for classification and to evaluate its performances. It has been observed that our proposed intelligent strategy gives promising experimental results and is quite effective in predicting misleading information. The proposed work provides practical implications for the policymakers and health practitioners that could be useful in protecting the world from misleading information proliferation during this pandemic.</p>","PeriodicalId":49766,"journal":{"name":"Neural Computing & Applications","volume":"35 8","pages":"5999-6013"},"PeriodicalIF":4.5000,"publicationDate":"2023-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9660173/pdf/","citationCount":"0","resultStr":"{\"title\":\"Framework for detection of probable clues to predict misleading information proliferated during COVID-19 outbreak.\",\"authors\":\"Deepika Varshney, Dinesh Kumar Vishwakarma\",\"doi\":\"10.1007/s00521-022-07938-3\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Spreading of misleading information on social web platforms has fuelled huge panic and confusion among the public regarding the Corona disease, the detection of which is of paramount importance. To identify the credibility of the posted claim, we have analyzed possible evidence from the news articles in the google search results. This paper proposes an intelligent and expert strategy to gather important clues from the top 10 google search results related to the claim. The N-gram, Levenshtein Distance, and Word-Similarity-based features are used to identify the clues from the news article that can automatically warn users against spreading false news if no significant supportive clues are identified concerning that claim. The complete process is done in four steps, wherein the first step we build a query from the posted claim received in the form of text or text additive images which further goes as an input to the search query phase, where the top 10 google results are processed. In the third step, the important clues are extracted from titles of the top 10 news articles. Lastly, useful pieces of evidence are extracted from the content of each news article. All the useful clues with respect to N-gram, Levenshtein Distance, and Word Similarity are finally fed into the machine learning model for classification and to evaluate its performances. It has been observed that our proposed intelligent strategy gives promising experimental results and is quite effective in predicting misleading information. The proposed work provides practical implications for the policymakers and health practitioners that could be useful in protecting the world from misleading information proliferation during this pandemic.</p>\",\"PeriodicalId\":49766,\"journal\":{\"name\":\"Neural Computing & Applications\",\"volume\":\"35 8\",\"pages\":\"5999-6013\"},\"PeriodicalIF\":4.5000,\"publicationDate\":\"2023-01-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9660173/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Neural Computing & Applications\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1007/s00521-022-07938-3\",\"RegionNum\":3,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Neural Computing & Applications","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s00521-022-07938-3","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
Framework for detection of probable clues to predict misleading information proliferated during COVID-19 outbreak.
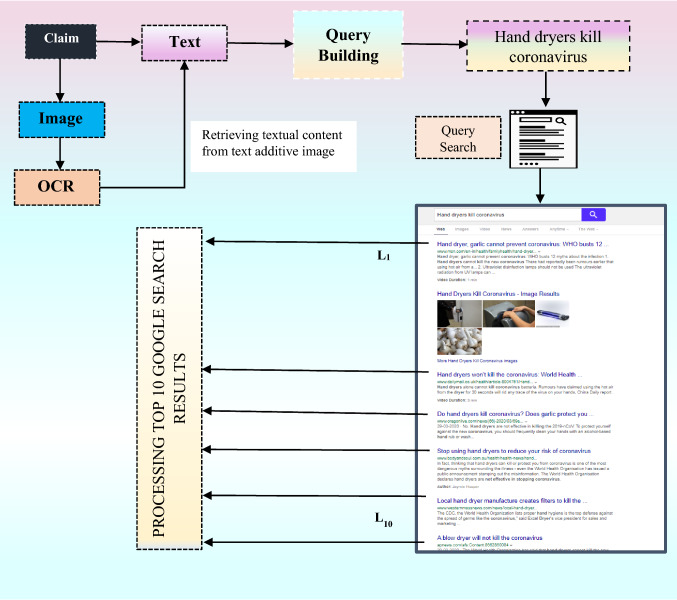
Spreading of misleading information on social web platforms has fuelled huge panic and confusion among the public regarding the Corona disease, the detection of which is of paramount importance. To identify the credibility of the posted claim, we have analyzed possible evidence from the news articles in the google search results. This paper proposes an intelligent and expert strategy to gather important clues from the top 10 google search results related to the claim. The N-gram, Levenshtein Distance, and Word-Similarity-based features are used to identify the clues from the news article that can automatically warn users against spreading false news if no significant supportive clues are identified concerning that claim. The complete process is done in four steps, wherein the first step we build a query from the posted claim received in the form of text or text additive images which further goes as an input to the search query phase, where the top 10 google results are processed. In the third step, the important clues are extracted from titles of the top 10 news articles. Lastly, useful pieces of evidence are extracted from the content of each news article. All the useful clues with respect to N-gram, Levenshtein Distance, and Word Similarity are finally fed into the machine learning model for classification and to evaluate its performances. It has been observed that our proposed intelligent strategy gives promising experimental results and is quite effective in predicting misleading information. The proposed work provides practical implications for the policymakers and health practitioners that could be useful in protecting the world from misleading information proliferation during this pandemic.
期刊介绍:
Neural Computing & Applications is an international journal which publishes original research and other information in the field of practical applications of neural computing and related techniques such as genetic algorithms, fuzzy logic and neuro-fuzzy systems.
All items relevant to building practical systems are within its scope, including but not limited to:
-adaptive computing-
algorithms-
applicable neural networks theory-
applied statistics-
architectures-
artificial intelligence-
benchmarks-
case histories of innovative applications-
fuzzy logic-
genetic algorithms-
hardware implementations-
hybrid intelligent systems-
intelligent agents-
intelligent control systems-
intelligent diagnostics-
intelligent forecasting-
machine learning-
neural networks-
neuro-fuzzy systems-
pattern recognition-
performance measures-
self-learning systems-
software simulations-
supervised and unsupervised learning methods-
system engineering and integration.
Featured contributions fall into several categories: Original Articles, Review Articles, Book Reviews and Announcements.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


