{"title":"使用机器学习方法对不平衡代码混合数据进行情感分析。","authors":"R Srinivasan, C N Subalalitha","doi":"10.1007/s10619-021-07331-4","DOIUrl":null,"url":null,"abstract":"<p><p>Knowledge discovery from various perspectives has become a crucial asset in almost all fields. Sentimental analysis is a classification task used to classify the sentence based on the meaning of their context. This paper addresses class imbalance problem which is one of the important issues in sentimental analysis. Not much works focused on sentimental analysis with imbalanced class label distribution. The paper also focusses on another aspect of the problem which involves a concept called \"Code Mixing\". Code mixed data consists of text alternating between two or more languages. Class imbalance distribution is a commonly noted phenomenon in a code-mixed data. The existing works have focused more on analyzing the sentiments in a monolingual data but not in a code-mixed data. This paper addresses all these issues and comes up with a solution to analyze sentiments for a class imbalanced code-mixed data using sampling technique combined with levenshtein distance metrics. Furthermore, this paper compares the performances of various machine learning approaches namely, Random Forest Classifier, Logistic Regression, XGBoost classifier, Support Vector Machine and Naïve Bayes Classifier using F1- Score.</p>","PeriodicalId":50568,"journal":{"name":"Distributed and Parallel Databases","volume":"41 1-2","pages":"37-52"},"PeriodicalIF":0.9000,"publicationDate":"2023-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://sci-hub-pdf.com/10.1007/s10619-021-07331-4","citationCount":"17","resultStr":"{\"title\":\"Sentimental analysis from imbalanced code-mixed data using machine learning approaches.\",\"authors\":\"R Srinivasan, C N Subalalitha\",\"doi\":\"10.1007/s10619-021-07331-4\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Knowledge discovery from various perspectives has become a crucial asset in almost all fields. Sentimental analysis is a classification task used to classify the sentence based on the meaning of their context. This paper addresses class imbalance problem which is one of the important issues in sentimental analysis. Not much works focused on sentimental analysis with imbalanced class label distribution. The paper also focusses on another aspect of the problem which involves a concept called \\\"Code Mixing\\\". Code mixed data consists of text alternating between two or more languages. Class imbalance distribution is a commonly noted phenomenon in a code-mixed data. The existing works have focused more on analyzing the sentiments in a monolingual data but not in a code-mixed data. This paper addresses all these issues and comes up with a solution to analyze sentiments for a class imbalanced code-mixed data using sampling technique combined with levenshtein distance metrics. Furthermore, this paper compares the performances of various machine learning approaches namely, Random Forest Classifier, Logistic Regression, XGBoost classifier, Support Vector Machine and Naïve Bayes Classifier using F1- Score.</p>\",\"PeriodicalId\":50568,\"journal\":{\"name\":\"Distributed and Parallel Databases\",\"volume\":\"41 1-2\",\"pages\":\"37-52\"},\"PeriodicalIF\":0.9000,\"publicationDate\":\"2023-01-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://sci-hub-pdf.com/10.1007/s10619-021-07331-4\",\"citationCount\":\"17\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Distributed and Parallel Databases\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1007/s10619-021-07331-4\",\"RegionNum\":4,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q3\",\"JCRName\":\"COMPUTER SCIENCE, INFORMATION SYSTEMS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Distributed and Parallel Databases","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s10619-021-07331-4","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"COMPUTER SCIENCE, INFORMATION SYSTEMS","Score":null,"Total":0}
Sentimental analysis from imbalanced code-mixed data using machine learning approaches.
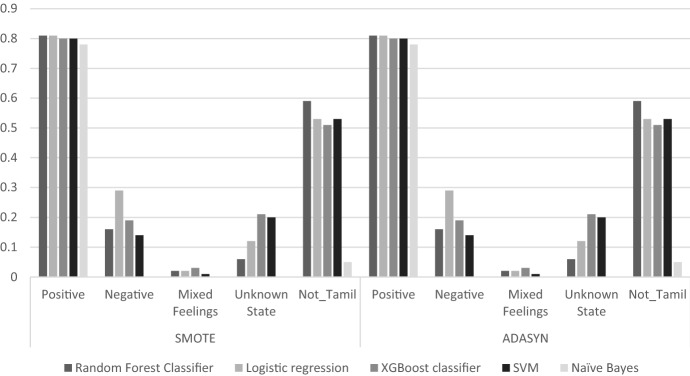
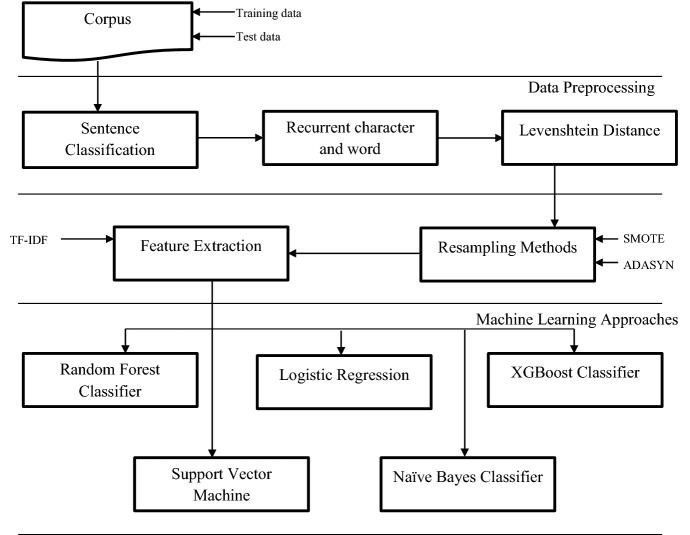
Knowledge discovery from various perspectives has become a crucial asset in almost all fields. Sentimental analysis is a classification task used to classify the sentence based on the meaning of their context. This paper addresses class imbalance problem which is one of the important issues in sentimental analysis. Not much works focused on sentimental analysis with imbalanced class label distribution. The paper also focusses on another aspect of the problem which involves a concept called "Code Mixing". Code mixed data consists of text alternating between two or more languages. Class imbalance distribution is a commonly noted phenomenon in a code-mixed data. The existing works have focused more on analyzing the sentiments in a monolingual data but not in a code-mixed data. This paper addresses all these issues and comes up with a solution to analyze sentiments for a class imbalanced code-mixed data using sampling technique combined with levenshtein distance metrics. Furthermore, this paper compares the performances of various machine learning approaches namely, Random Forest Classifier, Logistic Regression, XGBoost classifier, Support Vector Machine and Naïve Bayes Classifier using F1- Score.
期刊介绍:
Distributed and Parallel Databases publishes papers in all the traditional as well as most emerging areas of database research, including:
Availability and reliability;
Benchmarking and performance evaluation, and tuning;
Big Data Storage and Processing;
Cloud Computing and Database-as-a-Service;
Crowdsourcing;
Data curation, annotation and provenance;
Data integration, metadata Management, and interoperability;
Data models, semantics, query languages;
Data mining and knowledge discovery;
Data privacy, security, trust;
Data provenance, workflows, Scientific Data Management;
Data visualization and interactive data exploration;
Data warehousing, OLAP, Analytics;
Graph data management, RDF, social networks;
Information Extraction and Data Cleaning;
Middleware and Workflow Management;
Modern Hardware and In-Memory Database Systems;
Query Processing and Optimization;
Semantic Web and open data;
Social Networks;
Storage, indexing, and physical database design;
Streams, sensor networks, and complex event processing;
Strings, Texts, and Keyword Search;
Spatial, temporal, and spatio-temporal databases;
Transaction processing;
Uncertain, probabilistic, and approximate databases.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


