Tzyy-Shyang Lin, Nathan J. Rebello, Guang-He Lee, Melody A. Morris and Bradley D. Olsen*,
{"title":"定义骨架聚合物的BigSMILES规范化","authors":"Tzyy-Shyang Lin, Nathan J. Rebello, Guang-He Lee, Melody A. Morris and Bradley D. Olsen*, ","doi":"10.1021/acspolymersau.2c00009","DOIUrl":null,"url":null,"abstract":"<p >BigSMILES, a line notation for encapsulating the molecular structure of stochastic molecules such as polymers, was recently proposed as a compact and readable solution for writing macromolecules. While BigSMILES strings serve as useful identifiers for reconstructing the molecular connectivity for polymers, in general, BigSMILES allows the same polymer to be codified into multiple equally valid representations. Having a canonicalization scheme that eliminates the multiplicity would be very useful in reducing time-intensive tasks like structural comparison and molecular search into simple string-matching tasks. Motivated by this, in this work, two strategies for deriving canonical representations for linear polymers are proposed. In the first approach, a canonicalization scheme is proposed to standardize the expression of BigSMILES stochastic objects, thereby standardizing the expression of overall BigSMILES strings. In the second approach, an analogy between formal language theory and the molecular ensemble of polymer molecules is drawn. Linear polymers can be converted into regular languages, and the minimal deterministic finite automaton uniquely associated with each prescribed language is used as the basis for constructing the unique text identifier associated with each distinct polymer. Overall, this work presents algorithms to convert linear polymers into unique structure-based text identifiers. The derived identifiers can be readily applied in chemical information systems for polymers and other polymer informatics applications.</p>","PeriodicalId":72049,"journal":{"name":"ACS polymers Au","volume":"2 6","pages":"486–500"},"PeriodicalIF":4.7000,"publicationDate":"2022-10-14","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://ftp.ncbi.nlm.nih.gov/pub/pmc/oa_pdf/aa/f3/lg2c00009.PMC9761857.pdf","citationCount":"9","resultStr":"{\"title\":\"Canonicalizing BigSMILES for Polymers with Defined Backbones\",\"authors\":\"Tzyy-Shyang Lin, Nathan J. Rebello, Guang-He Lee, Melody A. Morris and Bradley D. Olsen*, \",\"doi\":\"10.1021/acspolymersau.2c00009\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p >BigSMILES, a line notation for encapsulating the molecular structure of stochastic molecules such as polymers, was recently proposed as a compact and readable solution for writing macromolecules. While BigSMILES strings serve as useful identifiers for reconstructing the molecular connectivity for polymers, in general, BigSMILES allows the same polymer to be codified into multiple equally valid representations. Having a canonicalization scheme that eliminates the multiplicity would be very useful in reducing time-intensive tasks like structural comparison and molecular search into simple string-matching tasks. Motivated by this, in this work, two strategies for deriving canonical representations for linear polymers are proposed. In the first approach, a canonicalization scheme is proposed to standardize the expression of BigSMILES stochastic objects, thereby standardizing the expression of overall BigSMILES strings. In the second approach, an analogy between formal language theory and the molecular ensemble of polymer molecules is drawn. Linear polymers can be converted into regular languages, and the minimal deterministic finite automaton uniquely associated with each prescribed language is used as the basis for constructing the unique text identifier associated with each distinct polymer. Overall, this work presents algorithms to convert linear polymers into unique structure-based text identifiers. The derived identifiers can be readily applied in chemical information systems for polymers and other polymer informatics applications.</p>\",\"PeriodicalId\":72049,\"journal\":{\"name\":\"ACS polymers Au\",\"volume\":\"2 6\",\"pages\":\"486–500\"},\"PeriodicalIF\":4.7000,\"publicationDate\":\"2022-10-14\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://ftp.ncbi.nlm.nih.gov/pub/pmc/oa_pdf/aa/f3/lg2c00009.PMC9761857.pdf\",\"citationCount\":\"9\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"ACS polymers Au\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://pubs.acs.org/doi/10.1021/acspolymersau.2c00009\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"POLYMER SCIENCE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"ACS polymers Au","FirstCategoryId":"1085","ListUrlMain":"https://pubs.acs.org/doi/10.1021/acspolymersau.2c00009","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"POLYMER SCIENCE","Score":null,"Total":0}
Canonicalizing BigSMILES for Polymers with Defined Backbones
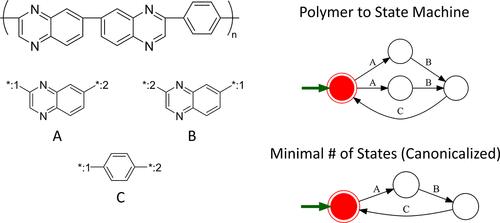
BigSMILES, a line notation for encapsulating the molecular structure of stochastic molecules such as polymers, was recently proposed as a compact and readable solution for writing macromolecules. While BigSMILES strings serve as useful identifiers for reconstructing the molecular connectivity for polymers, in general, BigSMILES allows the same polymer to be codified into multiple equally valid representations. Having a canonicalization scheme that eliminates the multiplicity would be very useful in reducing time-intensive tasks like structural comparison and molecular search into simple string-matching tasks. Motivated by this, in this work, two strategies for deriving canonical representations for linear polymers are proposed. In the first approach, a canonicalization scheme is proposed to standardize the expression of BigSMILES stochastic objects, thereby standardizing the expression of overall BigSMILES strings. In the second approach, an analogy between formal language theory and the molecular ensemble of polymer molecules is drawn. Linear polymers can be converted into regular languages, and the minimal deterministic finite automaton uniquely associated with each prescribed language is used as the basis for constructing the unique text identifier associated with each distinct polymer. Overall, this work presents algorithms to convert linear polymers into unique structure-based text identifiers. The derived identifiers can be readily applied in chemical information systems for polymers and other polymer informatics applications.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


