David Dreizin, Lei Zhang, Nathan Sarkar, Uttam K Bodanapally, Guang Li, Jiazhen Hu, Haomin Chen, Mustafa Khedr, Udit Khetan, Peter Campbell, Mathias Unberath
{"title":"通过具有质量保证和减少偏差功能的人工智能协作标注,加速横断面成像的体素标注。","authors":"David Dreizin, Lei Zhang, Nathan Sarkar, Uttam K Bodanapally, Guang Li, Jiazhen Hu, Haomin Chen, Mustafa Khedr, Udit Khetan, Peter Campbell, Mathias Unberath","doi":"10.3389/fradi.2023.1202412","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>precision-medicine quantitative tools for cross-sectional imaging require painstaking labeling of targets that vary considerably in volume, prohibiting scaling of data annotation efforts and supervised training to large datasets for robust and generalizable clinical performance. A straight-forward time-saving strategy involves manual editing of AI-generated labels, which we call AI-collaborative labeling (AICL). Factors affecting the efficacy and utility of such an approach are unknown. Reduction in time effort is not well documented. Further, edited AI labels may be prone to automation bias.</p><p><strong>Purpose: </strong>In this pilot, using a cohort of CTs with intracavitary hemorrhage, we evaluate both time savings and AICL label quality and propose criteria that must be met for using AICL annotations as a high-throughput, high-quality ground truth.</p><p><strong>Methods: </strong>57 CT scans of patients with traumatic intracavitary hemorrhage were included. No participant recruited for this study had previously interpreted the scans. nnU-net models trained on small existing datasets for each feature (hemothorax/hemoperitoneum/pelvic hematoma; <i>n</i> = 77-253) were used in inference. Two common scenarios served as baseline comparison- <i>de novo</i> expert manual labeling, and expert edits of trained staff labels. Parameters included time effort and image quality graded by a blinded independent expert using a 9-point scale. The observer also attempted to discriminate AICL and expert labels in a random subset (<i>n</i> = 18). Data were compared with ANOVA and post-hoc paired signed rank tests with Bonferroni correction.</p><p><strong>Results: </strong>AICL reduced time effort 2.8-fold compared to staff label editing, and 8.7-fold compared to expert labeling (corrected <i>p</i> < 0.0006). Mean Likert grades for AICL (8.4, SD:0.6) were significantly higher than for expert labels (7.8, SD:0.9) and edited staff labels (7.7, SD:0.8) (corrected <i>p</i> < 0.0006). The independent observer failed to correctly discriminate AI and human labels.</p><p><strong>Conclusion: </strong>For our use case and annotators, AICL facilitates rapid large-scale curation of high-quality ground truth. The proposed quality control regime can be employed by other investigators prior to embarking on AICL for segmentation tasks in large datasets.</p>","PeriodicalId":73101,"journal":{"name":"Frontiers in radiology","volume":"3 ","pages":""},"PeriodicalIF":0.0000,"publicationDate":"2023-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10362988/pdf/","citationCount":"0","resultStr":"{\"title\":\"Accelerating voxelwise annotation of cross-sectional imaging through AI collaborative labeling with quality assurance and bias mitigation.\",\"authors\":\"David Dreizin, Lei Zhang, Nathan Sarkar, Uttam K Bodanapally, Guang Li, Jiazhen Hu, Haomin Chen, Mustafa Khedr, Udit Khetan, Peter Campbell, Mathias Unberath\",\"doi\":\"10.3389/fradi.2023.1202412\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>precision-medicine quantitative tools for cross-sectional imaging require painstaking labeling of targets that vary considerably in volume, prohibiting scaling of data annotation efforts and supervised training to large datasets for robust and generalizable clinical performance. A straight-forward time-saving strategy involves manual editing of AI-generated labels, which we call AI-collaborative labeling (AICL). Factors affecting the efficacy and utility of such an approach are unknown. Reduction in time effort is not well documented. Further, edited AI labels may be prone to automation bias.</p><p><strong>Purpose: </strong>In this pilot, using a cohort of CTs with intracavitary hemorrhage, we evaluate both time savings and AICL label quality and propose criteria that must be met for using AICL annotations as a high-throughput, high-quality ground truth.</p><p><strong>Methods: </strong>57 CT scans of patients with traumatic intracavitary hemorrhage were included. No participant recruited for this study had previously interpreted the scans. nnU-net models trained on small existing datasets for each feature (hemothorax/hemoperitoneum/pelvic hematoma; <i>n</i> = 77-253) were used in inference. Two common scenarios served as baseline comparison- <i>de novo</i> expert manual labeling, and expert edits of trained staff labels. Parameters included time effort and image quality graded by a blinded independent expert using a 9-point scale. The observer also attempted to discriminate AICL and expert labels in a random subset (<i>n</i> = 18). Data were compared with ANOVA and post-hoc paired signed rank tests with Bonferroni correction.</p><p><strong>Results: </strong>AICL reduced time effort 2.8-fold compared to staff label editing, and 8.7-fold compared to expert labeling (corrected <i>p</i> < 0.0006). Mean Likert grades for AICL (8.4, SD:0.6) were significantly higher than for expert labels (7.8, SD:0.9) and edited staff labels (7.7, SD:0.8) (corrected <i>p</i> < 0.0006). The independent observer failed to correctly discriminate AI and human labels.</p><p><strong>Conclusion: </strong>For our use case and annotators, AICL facilitates rapid large-scale curation of high-quality ground truth. The proposed quality control regime can be employed by other investigators prior to embarking on AICL for segmentation tasks in large datasets.</p>\",\"PeriodicalId\":73101,\"journal\":{\"name\":\"Frontiers in radiology\",\"volume\":\"3 \",\"pages\":\"\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2023-01-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10362988/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Frontiers in radiology\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.3389/fradi.2023.1202412\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2023/7/11 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Frontiers in radiology","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.3389/fradi.2023.1202412","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2023/7/11 0:00:00","PubModel":"Epub","JCR":"","JCRName":"","Score":null,"Total":0}
Accelerating voxelwise annotation of cross-sectional imaging through AI collaborative labeling with quality assurance and bias mitigation.
Background: precision-medicine quantitative tools for cross-sectional imaging require painstaking labeling of targets that vary considerably in volume, prohibiting scaling of data annotation efforts and supervised training to large datasets for robust and generalizable clinical performance. A straight-forward time-saving strategy involves manual editing of AI-generated labels, which we call AI-collaborative labeling (AICL). Factors affecting the efficacy and utility of such an approach are unknown. Reduction in time effort is not well documented. Further, edited AI labels may be prone to automation bias.
Purpose: In this pilot, using a cohort of CTs with intracavitary hemorrhage, we evaluate both time savings and AICL label quality and propose criteria that must be met for using AICL annotations as a high-throughput, high-quality ground truth.
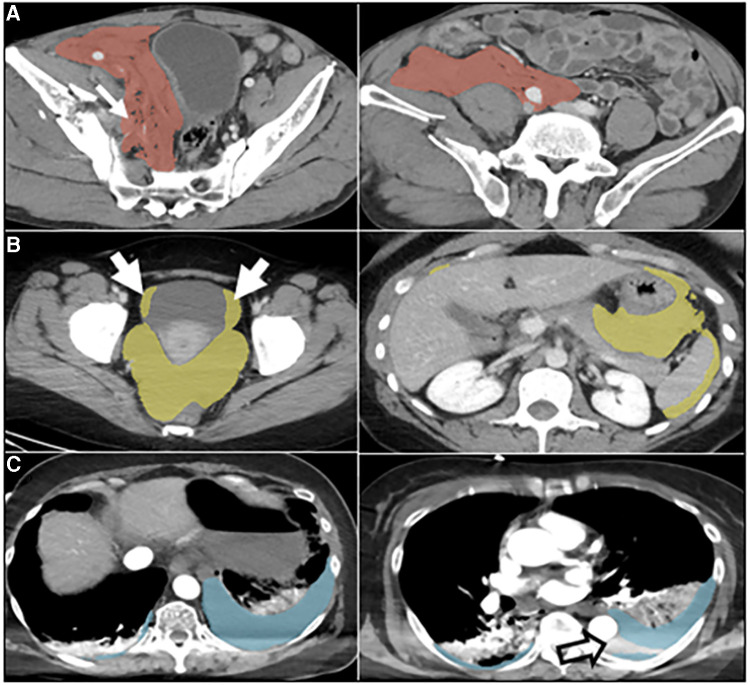
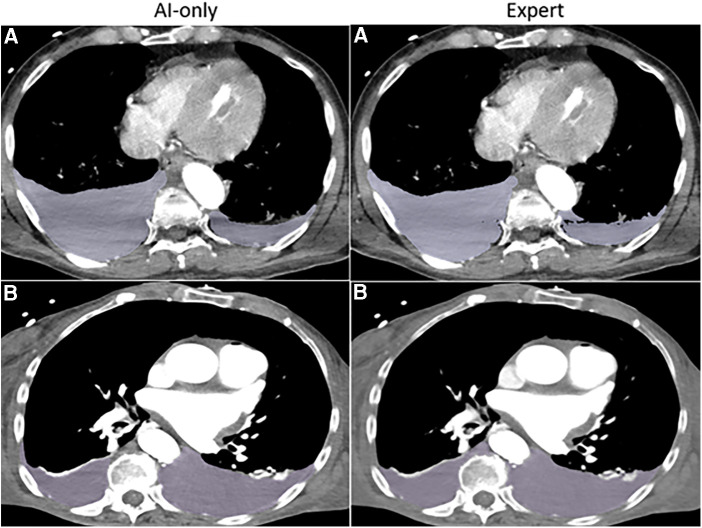
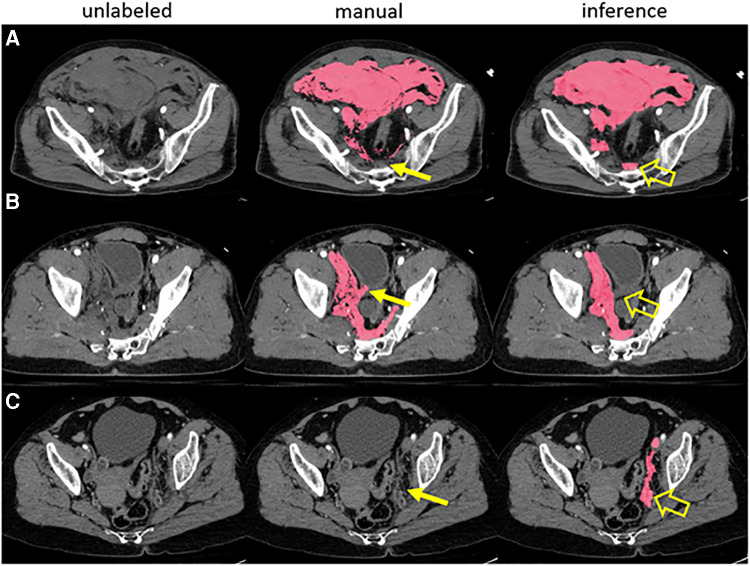
Methods: 57 CT scans of patients with traumatic intracavitary hemorrhage were included. No participant recruited for this study had previously interpreted the scans. nnU-net models trained on small existing datasets for each feature (hemothorax/hemoperitoneum/pelvic hematoma; n = 77-253) were used in inference. Two common scenarios served as baseline comparison- de novo expert manual labeling, and expert edits of trained staff labels. Parameters included time effort and image quality graded by a blinded independent expert using a 9-point scale. The observer also attempted to discriminate AICL and expert labels in a random subset (n = 18). Data were compared with ANOVA and post-hoc paired signed rank tests with Bonferroni correction.
Results: AICL reduced time effort 2.8-fold compared to staff label editing, and 8.7-fold compared to expert labeling (corrected p < 0.0006). Mean Likert grades for AICL (8.4, SD:0.6) were significantly higher than for expert labels (7.8, SD:0.9) and edited staff labels (7.7, SD:0.8) (corrected p < 0.0006). The independent observer failed to correctly discriminate AI and human labels.
Conclusion: For our use case and annotators, AICL facilitates rapid large-scale curation of high-quality ground truth. The proposed quality control regime can be employed by other investigators prior to embarking on AICL for segmentation tasks in large datasets.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


