Performance of emergency triage prediction of an open access natural language processing based chatbot application (ChatGPT): A preliminary, scenario-based cross-sectional study.
İbrahim Sarbay, Göksu Bozdereli Berikol, İbrahim Ulaş Özturan
{"title":"Performance of emergency triage prediction of an open access natural language processing based chatbot application (ChatGPT): A preliminary, scenario-based cross-sectional study.","authors":"İbrahim Sarbay, Göksu Bozdereli Berikol, İbrahim Ulaş Özturan","doi":"10.4103/tjem.tjem_79_23","DOIUrl":null,"url":null,"abstract":"<p><strong>Objectives: </strong>Artificial intelligence companies have been increasing their initiatives recently to improve the results of chatbots, which are software programs that can converse with a human in natural language. The role of chatbots in health care is deemed worthy of research. OpenAI's ChatGPT is a supervised and empowered machine learning-based chatbot. The aim of this study was to determine the performance of ChatGPT in emergency medicine (EM) triage prediction.</p><p><strong>Methods: </strong>This was a preliminary, cross-sectional study conducted with case scenarios generated by the researchers based on the emergency severity index (ESI) handbook v4 cases. Two independent EM specialists who were experts in the ESI triage scale determined the triage categories for each case. A third independent EM specialist was consulted as arbiter, if necessary. Consensus results for each case scenario were assumed as the reference triage category. Subsequently, each case scenario was queried with ChatGPT and the answer was recorded as the index triage category. Inconsistent classifications between the ChatGPT and reference category were defined as over-triage (false positive) or under-triage (false negative).</p><p><strong>Results: </strong>Fifty case scenarios were assessed in the study. Reliability analysis showed a fair agreement between EM specialists and ChatGPT (Cohen's Kappa: 0.341). Eleven cases (22%) were over triaged and 9 (18%) cases were under triaged by ChatGPT. In 9 cases (18%), ChatGPT reported two consecutive triage categories, one of which matched the expert consensus. It had an overall sensitivity of 57.1% (95% confidence interval [CI]: 34-78.2), specificity of 34.5% (95% CI: 17.9-54.3), positive predictive value (PPV) of 38.7% (95% CI: 21.8-57.8), negative predictive value (NPV) of 52.6 (95% CI: 28.9-75.6), and an F1 score of 0.461. In high acuity cases (ESI-1 and ESI-2), ChatGPT showed a sensitivity of 76.2% (95% CI: 52.8-91.8), specificity of 93.1% (95% CI: 77.2-99.2), PPV of 88.9% (95% CI: 65.3-98.6), NPV of 84.4 (95% CI: 67.2-94.7), and an F1 score of 0.821. The receiver operating characteristic curve showed an area under the curve of 0.846 (95% CI: 0.724-0.969, <i>P</i> < 0.001) for high acuity cases.</p><p><strong>Conclusion: </strong>The performance of ChatGPT was best when predicting high acuity cases (ESI-1 and ESI-2). It may be useful when determining the cases requiring critical care. When trained with more medical knowledge, ChatGPT may be more accurate for other triage category predictions.</p>","PeriodicalId":46536,"journal":{"name":"Turkish Journal of Emergency Medicine","volume":"23 3","pages":"156-161"},"PeriodicalIF":2.3000,"publicationDate":"2023-07-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://ftp.ncbi.nlm.nih.gov/pub/pmc/oa_pdf/c9/0b/TJEM-23-156.PMC10389099.pdf","citationCount":"3","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Turkish Journal of Emergency Medicine","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.4103/tjem.tjem_79_23","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"EMERGENCY MEDICINE","Score":null,"Total":0}
引用次数: 3
Abstract
Objectives: Artificial intelligence companies have been increasing their initiatives recently to improve the results of chatbots, which are software programs that can converse with a human in natural language. The role of chatbots in health care is deemed worthy of research. OpenAI's ChatGPT is a supervised and empowered machine learning-based chatbot. The aim of this study was to determine the performance of ChatGPT in emergency medicine (EM) triage prediction.
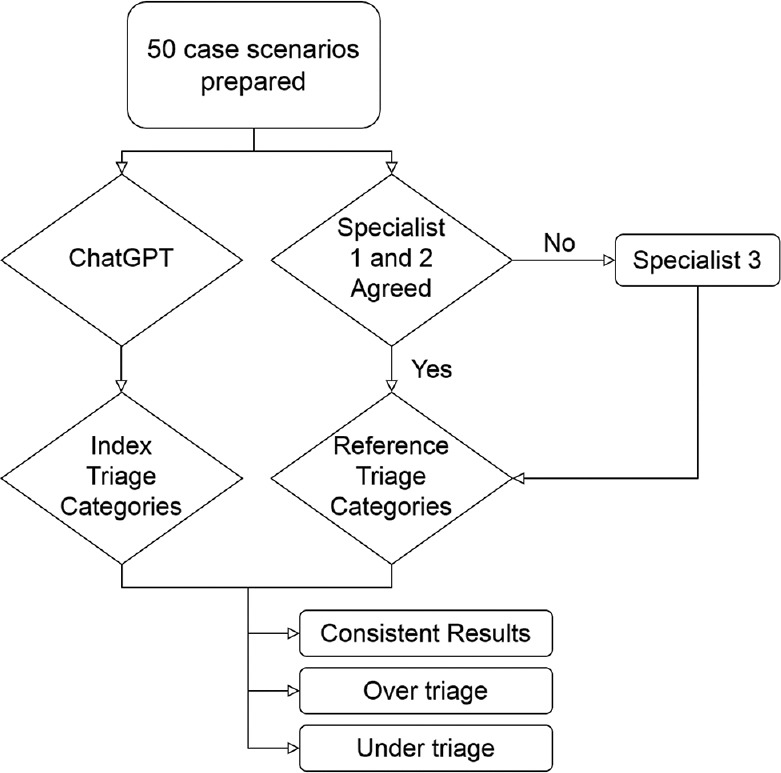
Methods: This was a preliminary, cross-sectional study conducted with case scenarios generated by the researchers based on the emergency severity index (ESI) handbook v4 cases. Two independent EM specialists who were experts in the ESI triage scale determined the triage categories for each case. A third independent EM specialist was consulted as arbiter, if necessary. Consensus results for each case scenario were assumed as the reference triage category. Subsequently, each case scenario was queried with ChatGPT and the answer was recorded as the index triage category. Inconsistent classifications between the ChatGPT and reference category were defined as over-triage (false positive) or under-triage (false negative).
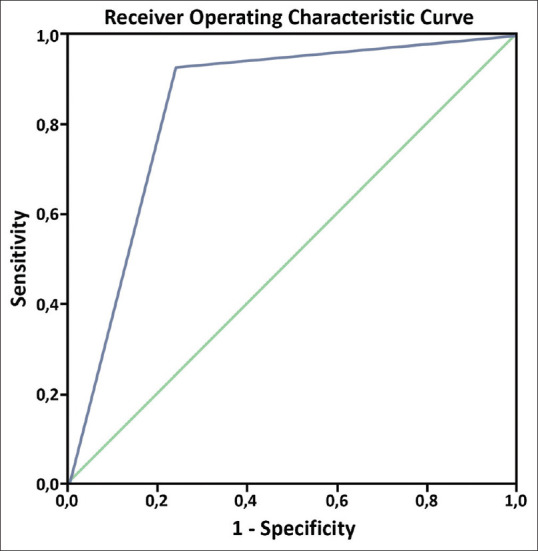
Results: Fifty case scenarios were assessed in the study. Reliability analysis showed a fair agreement between EM specialists and ChatGPT (Cohen's Kappa: 0.341). Eleven cases (22%) were over triaged and 9 (18%) cases were under triaged by ChatGPT. In 9 cases (18%), ChatGPT reported two consecutive triage categories, one of which matched the expert consensus. It had an overall sensitivity of 57.1% (95% confidence interval [CI]: 34-78.2), specificity of 34.5% (95% CI: 17.9-54.3), positive predictive value (PPV) of 38.7% (95% CI: 21.8-57.8), negative predictive value (NPV) of 52.6 (95% CI: 28.9-75.6), and an F1 score of 0.461. In high acuity cases (ESI-1 and ESI-2), ChatGPT showed a sensitivity of 76.2% (95% CI: 52.8-91.8), specificity of 93.1% (95% CI: 77.2-99.2), PPV of 88.9% (95% CI: 65.3-98.6), NPV of 84.4 (95% CI: 67.2-94.7), and an F1 score of 0.821. The receiver operating characteristic curve showed an area under the curve of 0.846 (95% CI: 0.724-0.969, P < 0.001) for high acuity cases.
Conclusion: The performance of ChatGPT was best when predicting high acuity cases (ESI-1 and ESI-2). It may be useful when determining the cases requiring critical care. When trained with more medical knowledge, ChatGPT may be more accurate for other triage category predictions.
期刊介绍:
The Turkish Journal of Emergency Medicine (Turk J Emerg Med) is an International, peer-reviewed, open-access journal that publishes clinical and experimental trials, case reports, invited reviews, case images, letters to the Editor, and interesting research conducted in all fields of Emergency Medicine. The Journal is the official scientific publication of the Emergency Medicine Association of Turkey (EMAT) and is printed four times a year, in January, April, July and October. The language of the journal is English. The Journal is based on independent and unbiased double-blinded peer-reviewed principles. Only unpublished papers that are not under review for publication elsewhere can be submitted. The authors are responsible for the scientific content of the material to be published. The Turkish Journal of Emergency Medicine reserves the right to request any research materials on which the paper is based. The Editorial Board of the Turkish Journal of Emergency Medicine and the Publisher adheres to the principles of the International Council of Medical Journal Editors, the World Association of Medical Editors, the Council of Science Editors, the Committee on Publication Ethics, the US National Library of Medicine, the US Office of Research Integrity, the European Association of Science Editors, and the International Society of Managing and Technical Editors.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


