{"title":"Go beyond the limits of genetic algorithm in daily covariate selection practice.","authors":"D Ronchi, E M Tosca, R Bartolucci, P Magni","doi":"10.1007/s10928-023-09875-7","DOIUrl":null,"url":null,"abstract":"<p><p>Covariate identification is an important step in the development of a population pharmacokinetic/pharmacodynamic model. Among the different available approaches, the stepwise covariate model (SCM) is the most used. However, SCM is based on a local search strategy, in which the model-building process iteratively tests the addition or elimination of a single covariate at a time given all the others. This introduces a heuristic to limit the searching space and then the computational complexity, but, at the same time, can lead to a suboptimal solution. The application of genetic algorithms (GAs) for covariate selection has been proposed as a possible solution to overcome these limitations. However, their actual use during model building is limited by the extremely high computational costs and convergence issues, both related to the number of models being tested. In this paper, we proposed a new GA for covariate selection to address these challenges. The GA was first developed on a simulated case study where the heuristics introduced to overcome the limitations affecting currently available GA approaches resulted able to limit the selection of redundant covariates, increase replicability of results and reduce convergence times. Then, we tested the proposed GA on a real-world problem related to remifentanil. It obtained good results both in terms of selected covariates and fitness optimization, outperforming the SCM.</p>","PeriodicalId":16851,"journal":{"name":"Journal of Pharmacokinetics and Pharmacodynamics","volume":" ","pages":"109-121"},"PeriodicalIF":2.2000,"publicationDate":"2024-04-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10982092/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Pharmacokinetics and Pharmacodynamics","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1007/s10928-023-09875-7","RegionNum":4,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2023/7/26 0:00:00","PubModel":"Epub","JCR":"Q3","JCRName":"PHARMACOLOGY & PHARMACY","Score":null,"Total":0}
引用次数: 0
Abstract
Covariate identification is an important step in the development of a population pharmacokinetic/pharmacodynamic model. Among the different available approaches, the stepwise covariate model (SCM) is the most used. However, SCM is based on a local search strategy, in which the model-building process iteratively tests the addition or elimination of a single covariate at a time given all the others. This introduces a heuristic to limit the searching space and then the computational complexity, but, at the same time, can lead to a suboptimal solution. The application of genetic algorithms (GAs) for covariate selection has been proposed as a possible solution to overcome these limitations. However, their actual use during model building is limited by the extremely high computational costs and convergence issues, both related to the number of models being tested. In this paper, we proposed a new GA for covariate selection to address these challenges. The GA was first developed on a simulated case study where the heuristics introduced to overcome the limitations affecting currently available GA approaches resulted able to limit the selection of redundant covariates, increase replicability of results and reduce convergence times. Then, we tested the proposed GA on a real-world problem related to remifentanil. It obtained good results both in terms of selected covariates and fitness optimization, outperforming the SCM.
协变量识别是开发群体药代动力学/药效学模型的重要步骤。在现有的各种方法中,使用最多的是逐步协变量模型(SCM)。然而,SCM 基于局部搜索策略,即在建立模型的过程中,在考虑到所有其他协变量的情况下,每次迭代测试增加或取消一个协变量。这引入了一种启发式方法来限制搜索空间和计算复杂度,但同时也可能导致次优解。遗传算法(GA)在协变量选择中的应用被认为是克服这些局限性的可行方案。然而,在模型构建过程中,遗传算法的实际应用受到了极高的计算成本和收敛问题的限制,这两个问题都与被测模型的数量有关。在本文中,我们提出了一种新的用于协变量选择的 GA 来应对这些挑战。我们首先在一个模拟案例研究中开发了该 GA,在该案例研究中,我们引入了启发式方法来克服影响现有 GA 方法的局限性,从而限制了冗余协变量的选择,提高了结果的可复制性并缩短了收敛时间。然后,我们在一个与瑞芬太尼相关的实际问题上测试了所提出的 GA。它在所选协变量和适应度优化方面都取得了良好的结果,优于单片机。
期刊介绍:
Broadly speaking, the Journal of Pharmacokinetics and Pharmacodynamics covers the area of pharmacometrics. The journal is devoted to illustrating the importance of pharmacokinetics, pharmacodynamics, and pharmacometrics in drug development, clinical care, and the understanding of drug action. The journal publishes on a variety of topics related to pharmacometrics, including, but not limited to, clinical, experimental, and theoretical papers examining the kinetics of drug disposition and effects of drug action in humans, animals, in vitro, or in silico; modeling and simulation methodology, including optimal design; precision medicine; systems pharmacology; and mathematical pharmacology (including computational biology, bioengineering, and biophysics related to pharmacology, pharmacokinetics, orpharmacodynamics). Clinical papers that include population pharmacokinetic-pharmacodynamic relationships are welcome. The journal actively invites and promotes up-and-coming areas of pharmacometric research, such as real-world evidence, quality of life analyses, and artificial intelligence. The Journal of Pharmacokinetics and Pharmacodynamics is an official journal of the International Society of Pharmacometrics.
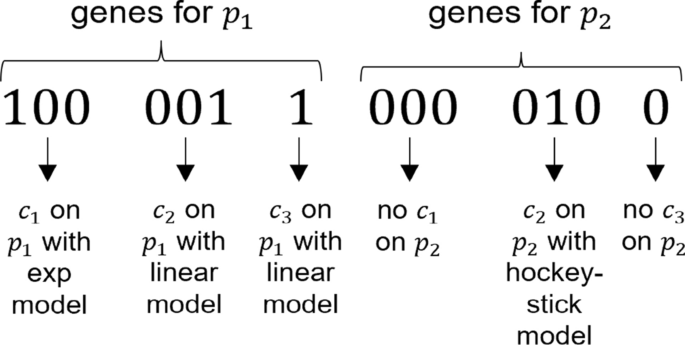

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


