Anders Lenskjold, Janus Uhd Nybing, Charlotte Trampedach, Astrid Galsgaard, Mathias Willadsen Brejnebøl, Henriette Raaschou, Martin Høyer Rose, Mikael Boesen
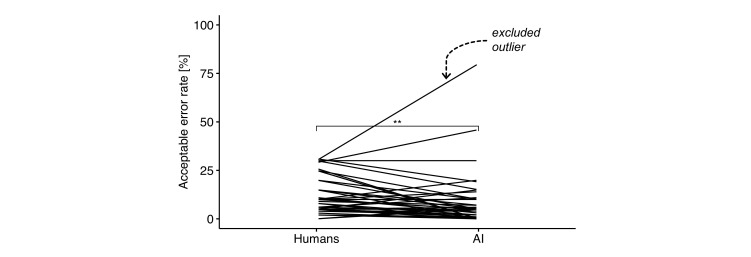
{"title":"Should artificial intelligence have lower acceptable error rates than humans?","authors":"Anders Lenskjold, Janus Uhd Nybing, Charlotte Trampedach, Astrid Galsgaard, Mathias Willadsen Brejnebøl, Henriette Raaschou, Martin Høyer Rose, Mikael Boesen","doi":"10.1259/bjro.20220053","DOIUrl":null,"url":null,"abstract":"<p><p>The first patient was misclassified in the diagnostic conclusion according to a local clinical expert opinion in a new clinical implementation of a knee osteoarthritis artificial intelligence (AI) algorithm at Bispebjerg-Frederiksberg University Hospital, Copenhagen, Denmark. In preparation for the evaluation of the AI algorithm, the implementation team collaborated with internal and external partners to plan workflows, and the algorithm was externally validated. After the misclassification, the team was left wondering: what is an acceptable error rate for a low-risk AI diagnostic algorithm? A survey among employees at the Department of Radiology showed significantly lower acceptable error rates for AI (6.8 %) than humans (11.3 %). A general mistrust of AI could cause the discrepancy in acceptable errors. AI may have the disadvantage of limited social capital and likeability compared to human co-workers, and therefore, less potential for forgiveness. Future AI development and implementation require further investigation of the fear of AI's unknown errors to enhance the trustworthiness of perceiving AI as a co-worker. Benchmark tools, transparency, and explainability are also needed to evaluate AI algorithms in clinical implementations to ensure acceptable performance.</p>","PeriodicalId":72419,"journal":{"name":"BJR open","volume":"5 1","pages":"20220053"},"PeriodicalIF":2.1000,"publicationDate":"2023-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10301708/pdf/","citationCount":"1","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"BJR open","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1259/bjro.20220053","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 1
Abstract
The first patient was misclassified in the diagnostic conclusion according to a local clinical expert opinion in a new clinical implementation of a knee osteoarthritis artificial intelligence (AI) algorithm at Bispebjerg-Frederiksberg University Hospital, Copenhagen, Denmark. In preparation for the evaluation of the AI algorithm, the implementation team collaborated with internal and external partners to plan workflows, and the algorithm was externally validated. After the misclassification, the team was left wondering: what is an acceptable error rate for a low-risk AI diagnostic algorithm? A survey among employees at the Department of Radiology showed significantly lower acceptable error rates for AI (6.8 %) than humans (11.3 %). A general mistrust of AI could cause the discrepancy in acceptable errors. AI may have the disadvantage of limited social capital and likeability compared to human co-workers, and therefore, less potential for forgiveness. Future AI development and implementation require further investigation of the fear of AI's unknown errors to enhance the trustworthiness of perceiving AI as a co-worker. Benchmark tools, transparency, and explainability are also needed to evaluate AI algorithms in clinical implementations to ensure acceptable performance.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


