{"title":"EduNER: a Chinese named entity recognition dataset for education research.","authors":"Xu Li, Chengkun Wei, Zhuoren Jiang, Wenlong Meng, Fan Ouyang, Zihui Zhang, Wenzhi Chen","doi":"10.1007/s00521-023-08635-5","DOIUrl":null,"url":null,"abstract":"<p><p>A high-quality domain-oriented dataset is crucial for the domain-specific named entity recognition (NER) task. In this study, we introduce a novel education-oriented Chinese NER dataset (EduNER). To provide representative and diverse training data, we collect data from multiple sources, including textbooks, academic papers, and education-related web pages. The collected documents span ten years (2012-2021). A team of domain experts is invited to accomplish the education NER schema definition, and a group of trained annotators is hired to complete the annotation. A collaborative labeling platform is built for accelerating human annotation. The constructed EduNER dataset includes 16 entity types, 11k+ sentences, and 35,731 entities. We conduct a thorough statistical analysis of EduNER and summarize its distinctive characteristics by comparing it with eight open-domain or domain-specific NER datasets. Sixteen state-of-the-art models are further utilized for NER tasks validation. The experimental results can enlighten further exploration. To the best of our knowledge, EduNER is the first publicly available dataset for NER task in the education domain, which may promote the development of education-oriented NER models.</p>","PeriodicalId":49766,"journal":{"name":"Neural Computing & Applications","volume":" ","pages":"1-15"},"PeriodicalIF":4.5000,"publicationDate":"2023-05-20","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10199663/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Neural Computing & Applications","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s00521-023-08635-5","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 0
Abstract
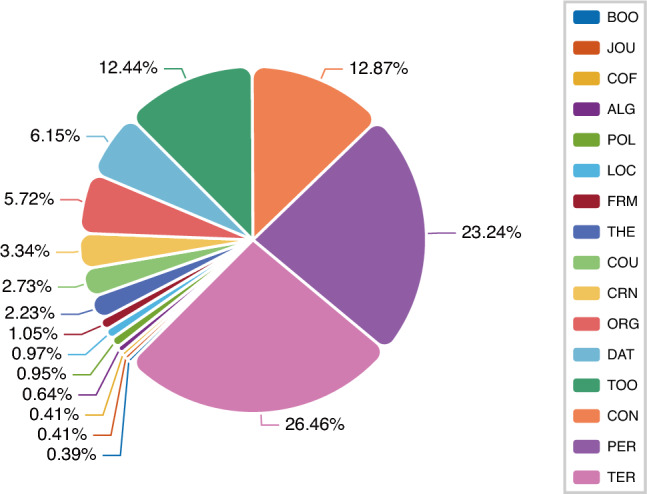
A high-quality domain-oriented dataset is crucial for the domain-specific named entity recognition (NER) task. In this study, we introduce a novel education-oriented Chinese NER dataset (EduNER). To provide representative and diverse training data, we collect data from multiple sources, including textbooks, academic papers, and education-related web pages. The collected documents span ten years (2012-2021). A team of domain experts is invited to accomplish the education NER schema definition, and a group of trained annotators is hired to complete the annotation. A collaborative labeling platform is built for accelerating human annotation. The constructed EduNER dataset includes 16 entity types, 11k+ sentences, and 35,731 entities. We conduct a thorough statistical analysis of EduNER and summarize its distinctive characteristics by comparing it with eight open-domain or domain-specific NER datasets. Sixteen state-of-the-art models are further utilized for NER tasks validation. The experimental results can enlighten further exploration. To the best of our knowledge, EduNER is the first publicly available dataset for NER task in the education domain, which may promote the development of education-oriented NER models.
期刊介绍:
Neural Computing & Applications is an international journal which publishes original research and other information in the field of practical applications of neural computing and related techniques such as genetic algorithms, fuzzy logic and neuro-fuzzy systems.
All items relevant to building practical systems are within its scope, including but not limited to:
-adaptive computing-
algorithms-
applicable neural networks theory-
applied statistics-
architectures-
artificial intelligence-
benchmarks-
case histories of innovative applications-
fuzzy logic-
genetic algorithms-
hardware implementations-
hybrid intelligent systems-
intelligent agents-
intelligent control systems-
intelligent diagnostics-
intelligent forecasting-
machine learning-
neural networks-
neuro-fuzzy systems-
pattern recognition-
performance measures-
self-learning systems-
software simulations-
supervised and unsupervised learning methods-
system engineering and integration.
Featured contributions fall into several categories: Original Articles, Review Articles, Book Reviews and Announcements.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


