Multilingual text categorization and sentiment analysis: a comparative analysis of the utilization of multilingual approaches for classifying twitter data.
IF 4.5 3区 计算机科学Q2 COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE
George Manias, Argyro Mavrogiorgou, Athanasios Kiourtis, Chrysostomos Symvoulidis, Dimosthenis Kyriazis
{"title":"Multilingual text categorization and sentiment analysis: a comparative analysis of the utilization of multilingual approaches for classifying twitter data.","authors":"George Manias, Argyro Mavrogiorgou, Athanasios Kiourtis, Chrysostomos Symvoulidis, Dimosthenis Kyriazis","doi":"10.1007/s00521-023-08629-3","DOIUrl":null,"url":null,"abstract":"<p><p>Text categorization and sentiment analysis are two of the most typical natural language processing tasks with various emerging applications implemented and utilized in different domains, such as health care and policy making. At the same time, the tremendous growth in the popularity and usage of social media, such as Twitter, has resulted on an immense increase in user-generated data, as mainly represented by the corresponding texts in users' posts. However, the analysis of these specific data and the extraction of actionable knowledge and added value out of them is a challenging task due to the domain diversity and the high multilingualism that characterizes these data. The latter highlights the emerging need for the implementation and utilization of domain-agnostic and multilingual solutions. To investigate a portion of these challenges this research work performs a comparative analysis of multilingual approaches for classifying both the sentiment and the text of an examined multilingual corpus. In this context, four multilingual BERT-based classifiers and a zero-shot classification approach are utilized and compared in terms of their accuracy and applicability in the classification of multilingual data. Their comparison has unveiled insightful outcomes and has a twofold interpretation. Multilingual BERT-based classifiers achieve high performances and transfer inference when trained and fine-tuned on multilingual data. While also the zero-shot approach presents a novel technique for creating multilingual solutions in a faster, more efficient, and scalable way. It can easily be fitted to new languages and new tasks while achieving relatively good results across many languages. However, when efficiency and scalability are less important than accuracy, it seems that this model, and zero-shot models in general, can not be compared to fine-tuned and trained multilingual BERT-based classifiers.</p>","PeriodicalId":49766,"journal":{"name":"Neural Computing & Applications","volume":" ","pages":"1-17"},"PeriodicalIF":4.5000,"publicationDate":"2023-05-08","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10165589/pdf/","citationCount":"5","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Neural Computing & Applications","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s00521-023-08629-3","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 5
Abstract
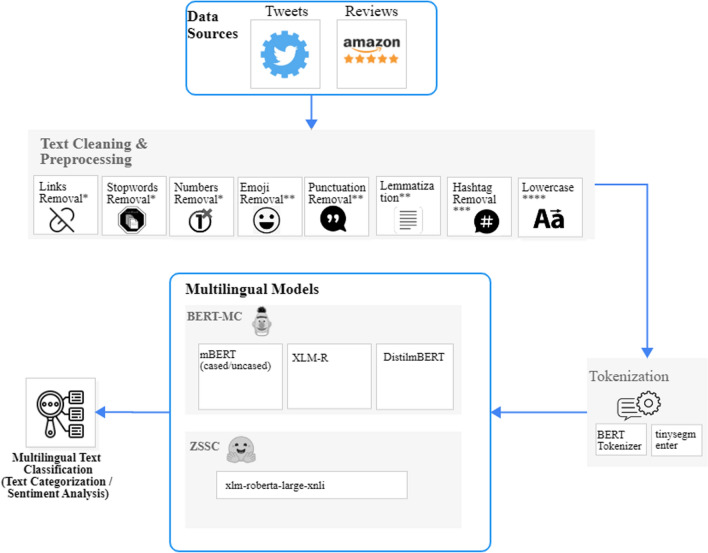
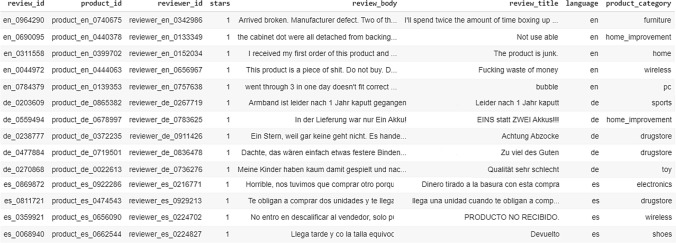
Text categorization and sentiment analysis are two of the most typical natural language processing tasks with various emerging applications implemented and utilized in different domains, such as health care and policy making. At the same time, the tremendous growth in the popularity and usage of social media, such as Twitter, has resulted on an immense increase in user-generated data, as mainly represented by the corresponding texts in users' posts. However, the analysis of these specific data and the extraction of actionable knowledge and added value out of them is a challenging task due to the domain diversity and the high multilingualism that characterizes these data. The latter highlights the emerging need for the implementation and utilization of domain-agnostic and multilingual solutions. To investigate a portion of these challenges this research work performs a comparative analysis of multilingual approaches for classifying both the sentiment and the text of an examined multilingual corpus. In this context, four multilingual BERT-based classifiers and a zero-shot classification approach are utilized and compared in terms of their accuracy and applicability in the classification of multilingual data. Their comparison has unveiled insightful outcomes and has a twofold interpretation. Multilingual BERT-based classifiers achieve high performances and transfer inference when trained and fine-tuned on multilingual data. While also the zero-shot approach presents a novel technique for creating multilingual solutions in a faster, more efficient, and scalable way. It can easily be fitted to new languages and new tasks while achieving relatively good results across many languages. However, when efficiency and scalability are less important than accuracy, it seems that this model, and zero-shot models in general, can not be compared to fine-tuned and trained multilingual BERT-based classifiers.
期刊介绍:
Neural Computing & Applications is an international journal which publishes original research and other information in the field of practical applications of neural computing and related techniques such as genetic algorithms, fuzzy logic and neuro-fuzzy systems.
All items relevant to building practical systems are within its scope, including but not limited to:
-adaptive computing-
algorithms-
applicable neural networks theory-
applied statistics-
architectures-
artificial intelligence-
benchmarks-
case histories of innovative applications-
fuzzy logic-
genetic algorithms-
hardware implementations-
hybrid intelligent systems-
intelligent agents-
intelligent control systems-
intelligent diagnostics-
intelligent forecasting-
machine learning-
neural networks-
neuro-fuzzy systems-
pattern recognition-
performance measures-
self-learning systems-
software simulations-
supervised and unsupervised learning methods-
system engineering and integration.
Featured contributions fall into several categories: Original Articles, Review Articles, Book Reviews and Announcements.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


