Xinlu Wu, Xijian Fan, Peng Luo, Sruti Das Choudhury, Tardi Tjahjadi, Chunhua Hu
{"title":"From Laboratory to Field: Unsupervised Domain Adaptation for Plant Disease Recognition in the Wild.","authors":"Xinlu Wu, Xijian Fan, Peng Luo, Sruti Das Choudhury, Tardi Tjahjadi, Chunhua Hu","doi":"10.34133/plantphenomics.0038","DOIUrl":null,"url":null,"abstract":"<p><p>Plant disease recognition is of vital importance to monitor plant development and predicting crop production. However, due to data degradation caused by different conditions of image acquisition, e.g., laboratory vs. field environment, machine learning-based recognition models generated within a specific dataset (source domain) tend to lose their validity when generalized to a novel dataset (target domain). To this end, domain adaptation methods can be leveraged for the recognition by learning invariant representations across domains. In this paper, we aim at addressing the issues of domain shift existing in plant disease recognition and propose a novel unsupervised domain adaptation method via uncertainty regularization, namely, Multi-Representation Subdomain Adaptation Network with Uncertainty Regularization for Cross-Species Plant Disease Classification (MSUN). Our simple but effective MSUN makes a breakthrough in plant disease recognition in the wild by using a large amount of unlabeled data and via nonadversarial training. Specifically, MSUN comprises multirepresentation, subdomain adaptation modules and auxiliary uncertainty regularization. The multirepresentation module enables MSUN to learn the overall structure of features and also focus on capturing more details by using the multiple representations of the source domain. This effectively alleviates the problem of large interdomain discrepancy. Subdomain adaptation is used to capture discriminative properties by addressing the issue of higher interclass similarity and lower intraclass variation. Finally, the auxiliary uncertainty regularization effectively suppresses the uncertainty problem due to domain transfer. MSUN was experimentally validated to achieve optimal results on the PlantDoc, Plant-Pathology, Corn-Leaf-Diseases, and Tomato-Leaf-Diseases datasets, with accuracies of 56.06%, 72.31%, 96.78%, and 50.58%, respectively, surpassing other state-of-the-art domain adaptation techniques considerably.</p>","PeriodicalId":20318,"journal":{"name":"Plant Phenomics","volume":"5 ","pages":"0038"},"PeriodicalIF":7.6000,"publicationDate":"2023-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10059679/pdf/","citationCount":"8","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Plant Phenomics","FirstCategoryId":"97","ListUrlMain":"https://doi.org/10.34133/plantphenomics.0038","RegionNum":1,"RegionCategory":"农林科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"AGRONOMY","Score":null,"Total":0}
引用次数: 8
Abstract
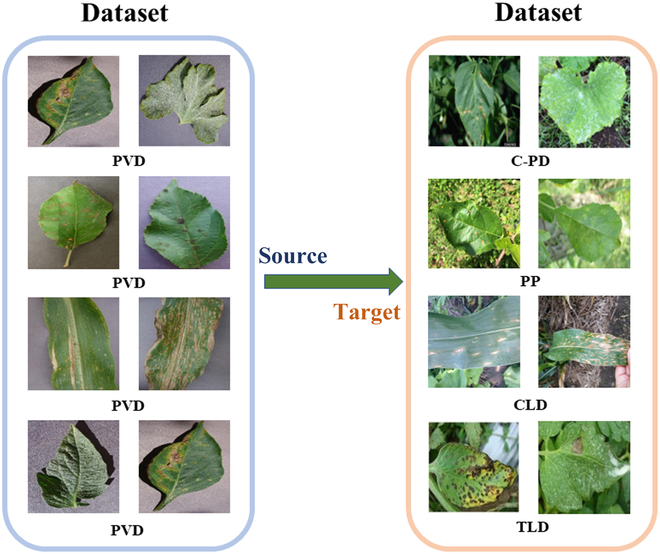
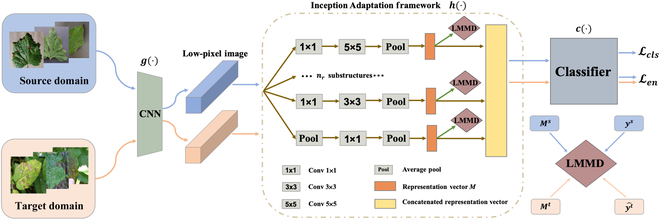
Plant disease recognition is of vital importance to monitor plant development and predicting crop production. However, due to data degradation caused by different conditions of image acquisition, e.g., laboratory vs. field environment, machine learning-based recognition models generated within a specific dataset (source domain) tend to lose their validity when generalized to a novel dataset (target domain). To this end, domain adaptation methods can be leveraged for the recognition by learning invariant representations across domains. In this paper, we aim at addressing the issues of domain shift existing in plant disease recognition and propose a novel unsupervised domain adaptation method via uncertainty regularization, namely, Multi-Representation Subdomain Adaptation Network with Uncertainty Regularization for Cross-Species Plant Disease Classification (MSUN). Our simple but effective MSUN makes a breakthrough in plant disease recognition in the wild by using a large amount of unlabeled data and via nonadversarial training. Specifically, MSUN comprises multirepresentation, subdomain adaptation modules and auxiliary uncertainty regularization. The multirepresentation module enables MSUN to learn the overall structure of features and also focus on capturing more details by using the multiple representations of the source domain. This effectively alleviates the problem of large interdomain discrepancy. Subdomain adaptation is used to capture discriminative properties by addressing the issue of higher interclass similarity and lower intraclass variation. Finally, the auxiliary uncertainty regularization effectively suppresses the uncertainty problem due to domain transfer. MSUN was experimentally validated to achieve optimal results on the PlantDoc, Plant-Pathology, Corn-Leaf-Diseases, and Tomato-Leaf-Diseases datasets, with accuracies of 56.06%, 72.31%, 96.78%, and 50.58%, respectively, surpassing other state-of-the-art domain adaptation techniques considerably.
期刊介绍:
Plant Phenomics is an Open Access journal published in affiliation with the State Key Laboratory of Crop Genetics & Germplasm Enhancement, Nanjing Agricultural University (NAU) and published by the American Association for the Advancement of Science (AAAS). Like all partners participating in the Science Partner Journal program, Plant Phenomics is editorially independent from the Science family of journals.
The mission of Plant Phenomics is to publish novel research that will advance all aspects of plant phenotyping from the cell to the plant population levels using innovative combinations of sensor systems and data analytics. Plant Phenomics aims also to connect phenomics to other science domains, such as genomics, genetics, physiology, molecular biology, bioinformatics, statistics, mathematics, and computer sciences. Plant Phenomics should thus contribute to advance plant sciences and agriculture/forestry/horticulture by addressing key scientific challenges in the area of plant phenomics.
The scope of the journal covers the latest technologies in plant phenotyping for data acquisition, data management, data interpretation, modeling, and their practical applications for crop cultivation, plant breeding, forestry, horticulture, ecology, and other plant-related domains.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


