Demetris Avraam, Rebecca Wilson, Oliver Butters, Thomas Burton, Christos Nicolaides, Elinor Jones, Andy Boyd, Paul Burton
{"title":"Privacy preserving data visualizations.","authors":"Demetris Avraam, Rebecca Wilson, Oliver Butters, Thomas Burton, Christos Nicolaides, Elinor Jones, Andy Boyd, Paul Burton","doi":"10.1140/epjds/s13688-020-00257-4","DOIUrl":null,"url":null,"abstract":"<p><p>Data visualizations are a valuable tool used during both statistical analysis and the interpretation of results as they graphically reveal useful information about the structure, properties and relationships between variables, which may otherwise be concealed in tabulated data. In disciplines like medicine and the social sciences, where collected data include sensitive information about study participants, the sharing and publication of individual-level records is controlled by data protection laws and ethico-legal norms. Thus, as data visualizations - such as graphs and plots - may be linked to other released information and used to identify study participants and their personal attributes, their creation is often prohibited by the terms of data use. These restrictions are enforced to reduce the risk of breaching data subject confidentiality, however they limit analysts from displaying useful descriptive plots for their research features and findings. Here we propose the use of anonymization techniques to generate privacy-preserving visualizations that retain the statistical properties of the underlying data while still adhering to strict data disclosure rules. We demonstrate the use of (i) the well-known <i>k</i>-anonymization process which preserves privacy by reducing the granularity of the data using suppression and generalization, (ii) a novel deterministic approach that replaces individual-level observations with the centroids of each <i>k</i> nearest neighbours, and (iii) a probabilistic procedure that perturbs individual attributes with the addition of random stochastic noise. We apply the proposed methods to generate privacy-preserving data visualizations for exploratory data analysis and inferential regression plot diagnostics, and we discuss their strengths and limitations.</p>","PeriodicalId":11887,"journal":{"name":"EPJ Data Science","volume":"10 1","pages":"2"},"PeriodicalIF":3.0000,"publicationDate":"2021-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC7790778/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"EPJ Data Science","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1140/epjds/s13688-020-00257-4","RegionNum":2,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2021/1/7 0:00:00","PubModel":"Epub","JCR":"Q1","JCRName":"MATHEMATICS, INTERDISCIPLINARY APPLICATIONS","Score":null,"Total":0}
引用次数: 0
Abstract
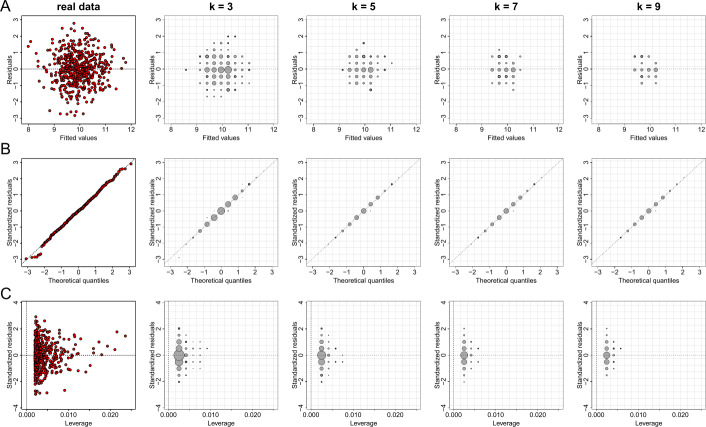
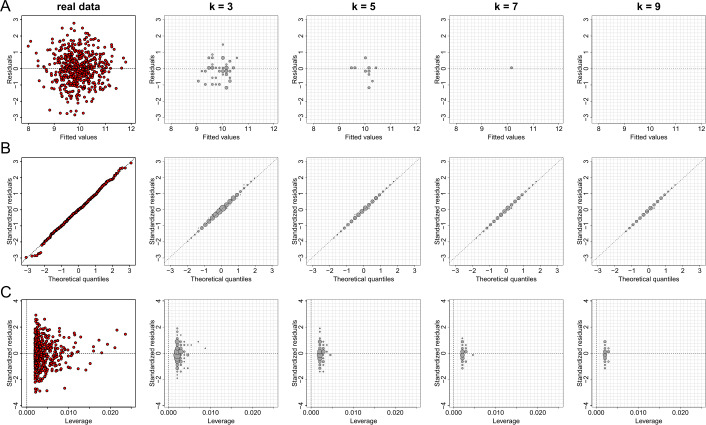
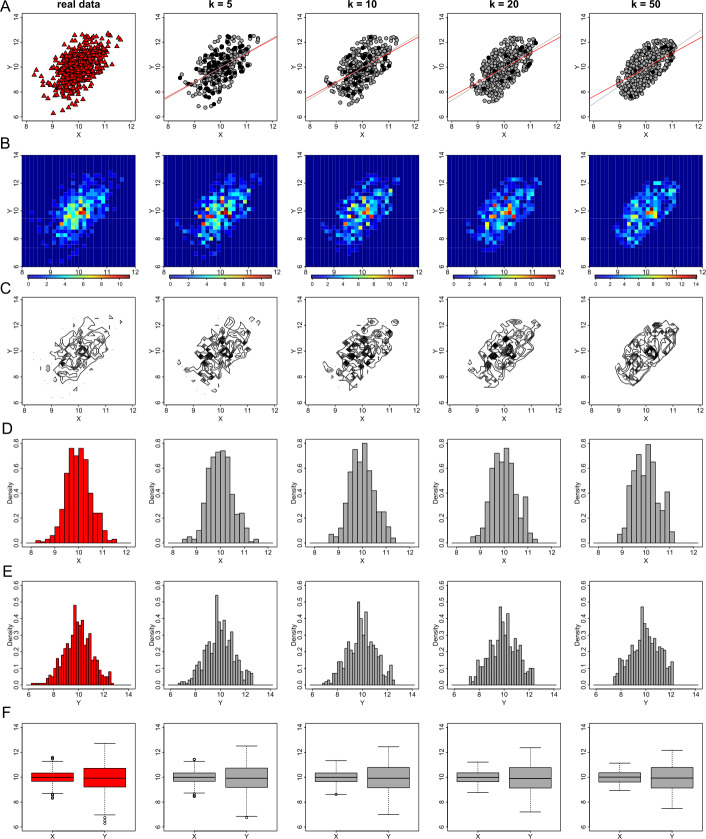
Data visualizations are a valuable tool used during both statistical analysis and the interpretation of results as they graphically reveal useful information about the structure, properties and relationships between variables, which may otherwise be concealed in tabulated data. In disciplines like medicine and the social sciences, where collected data include sensitive information about study participants, the sharing and publication of individual-level records is controlled by data protection laws and ethico-legal norms. Thus, as data visualizations - such as graphs and plots - may be linked to other released information and used to identify study participants and their personal attributes, their creation is often prohibited by the terms of data use. These restrictions are enforced to reduce the risk of breaching data subject confidentiality, however they limit analysts from displaying useful descriptive plots for their research features and findings. Here we propose the use of anonymization techniques to generate privacy-preserving visualizations that retain the statistical properties of the underlying data while still adhering to strict data disclosure rules. We demonstrate the use of (i) the well-known k-anonymization process which preserves privacy by reducing the granularity of the data using suppression and generalization, (ii) a novel deterministic approach that replaces individual-level observations with the centroids of each k nearest neighbours, and (iii) a probabilistic procedure that perturbs individual attributes with the addition of random stochastic noise. We apply the proposed methods to generate privacy-preserving data visualizations for exploratory data analysis and inferential regression plot diagnostics, and we discuss their strengths and limitations.
数据可视化是统计分析和结果解释过程中使用的重要工具,因为它们以图形方式揭示了变量之间的结构、属性和关系等有用信息,而这些信息可能隐藏在表格数据中。在医学和社会科学等学科中,所收集的数据包括研究参与者的敏感信息,个人层面记录的共享和发布受到数据保护法和伦理-法律规范的控制。因此,由于数据可视化(如图表和绘图)可能与其他已发布的信息相关联,并用于识别研究参与者及其个人属性,因此数据使用条款通常禁止创建这些可视化。实施这些限制是为了降低违反数据主体保密性的风险,但却限制了分析师为其研究特征和发现展示有用的描述性图表。在此,我们建议使用匿名化技术生成保护隐私的可视化图表,既能保留基础数据的统计属性,又能遵守严格的数据披露规则。我们展示了以下几种方法的使用:(i) 众所周知的 k 匿名化过程,该过程通过使用抑制和泛化来降低数据的粒度,从而保护隐私;(ii) 一种新颖的确定性方法,该方法用每 k 个近邻的中心点来替代个体级观测值;(iii) 一种概率性程序,该程序通过添加随机随机噪声来扰乱个体属性。我们应用所提出的方法生成保护隐私的数据可视化,用于探索性数据分析和推理回归图诊断,并讨论了这些方法的优势和局限性。
期刊介绍:
EPJ Data Science covers a broad range of research areas and applications and particularly encourages contributions from techno-socio-economic systems, where it comprises those research lines that now regard the digital “tracks” of human beings as first-order objects for scientific investigation. Topics include, but are not limited to, human behavior, social interaction (including animal societies), economic and financial systems, management and business networks, socio-technical infrastructure, health and environmental systems, the science of science, as well as general risk and crisis scenario forecasting up to and including policy advice.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


