Meta-reinforcement learning via orbitofrontal cortex
IF 21.2
1区 医学
Q1 NEUROSCIENCES
引用次数: 0
Abstract
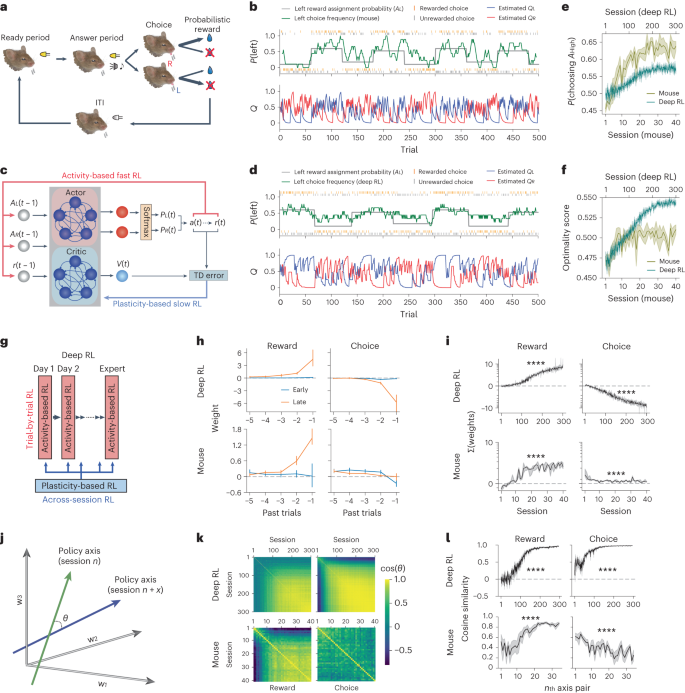
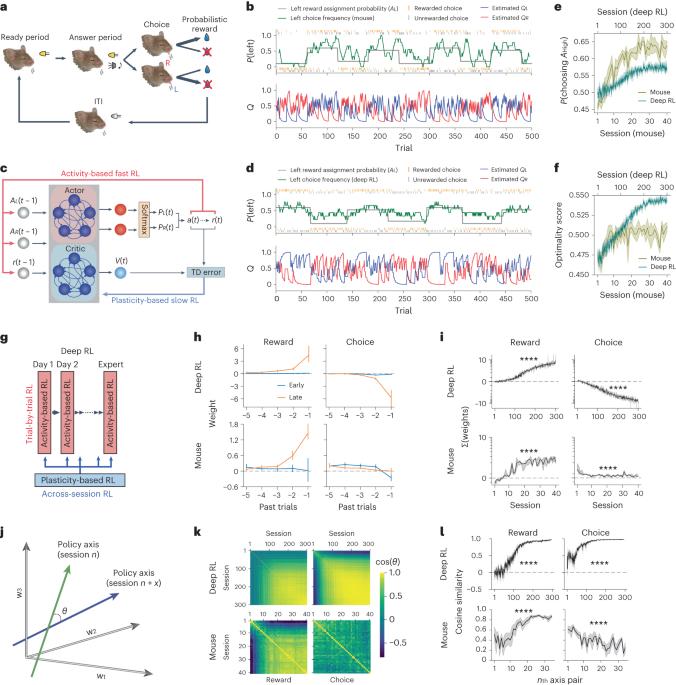
The meta-reinforcement learning (meta-RL) framework, which involves RL over multiple timescales, has been successful in training deep RL models that generalize to new environments. It has been hypothesized that the prefrontal cortex may mediate meta-RL in the brain, but the evidence is scarce. Here we show that the orbitofrontal cortex (OFC) mediates meta-RL. We trained mice and deep RL models on a probabilistic reversal learning task across sessions during which they improved their trial-by-trial RL policy through meta-learning. Ca2+/calmodulin-dependent protein kinase II-dependent synaptic plasticity in OFC was necessary for this meta-learning but not for the within-session trial-by-trial RL in experts. After meta-learning, OFC activity robustly encoded value signals, and OFC inactivation impaired the RL behaviors. Longitudinal tracking of OFC activity revealed that meta-learning gradually shapes population value coding to guide the ongoing behavioral policy. Our results indicate that two distinct RL algorithms with distinct neural mechanisms and timescales coexist in OFC to support adaptive decision-making. The authors show that neural activity and synaptic plasticity in the orbitofrontal cortex mediate multiple timescales of reinforcement learning (RL) for meta-RL, which parallels a form of meta-RL in artificial intelligence.
眶额叶皮层的元强化学习。
元强化学习(meta-RL)框架涉及多个时间尺度的强化学习,在训练可推广到新环境的深度强化学习模型方面取得了成功。有假说认为,前额叶皮层可能介导大脑的后rl,但证据很少。在这里,我们发现眶额皮质(OFC)介导后rl。我们对小鼠和深度强化学习模型进行了跨会话的概率逆转学习任务训练,在此期间,它们通过元学习改进了逐个试验的强化学习策略。OFC中Ca2+/钙调素依赖性蛋白激酶ii依赖性突触可塑性对于这种元学习是必要的,但对于专家的会话内逐试验RL不是必要的。在元学习后,OFC活动稳健地编码了价值信号,OFC失活损害了RL行为。OFC活动的纵向跟踪显示,元学习逐渐形成群体价值编码,以指导正在进行的行为政策。研究结果表明,两种具有不同神经机制和时间尺度的强化学习算法在OFC中共存,以支持自适应决策。
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文
来源期刊

Nature neuroscience
医学-神经科学
CiteScore
38.60
自引率
1.20%
发文量
212
审稿时长
1 months
期刊介绍:
Nature Neuroscience, a multidisciplinary journal, publishes papers of the utmost quality and significance across all realms of neuroscience. The editors welcome contributions spanning molecular, cellular, systems, and cognitive neuroscience, along with psychophysics, computational modeling, and nervous system disorders. While no area is off-limits, studies offering fundamental insights into nervous system function receive priority.
The journal offers high visibility to both readers and authors, fostering interdisciplinary communication and accessibility to a broad audience. It maintains high standards of copy editing and production, rigorous peer review, rapid publication, and operates independently from academic societies and other vested interests.
In addition to primary research, Nature Neuroscience features news and views, reviews, editorials, commentaries, perspectives, book reviews, and correspondence, aiming to serve as the voice of the global neuroscience community.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


