A topological data analysis based classifier
Abstract
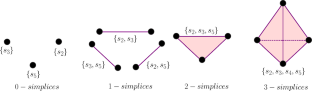
Topological Data Analysis (TDA) is an emerging field that aims to discover a dataset’s underlying topological information. TDA tools have been commonly used to create filters and topological descriptors to improve Machine Learning (ML) methods. This paper proposes a different TDA pipeline to classify balanced and imbalanced multi-class datasets without additional ML methods. Our proposed method was designed to solve multi-class and imbalanced classification problems with no data resampling preprocessing stage. The proposed TDA-based classifier (TDABC) builds a filtered simplicial complex on the dataset representing high-order data relationships. Following the assumption that a meaningful sub-complex exists in the filtration that approximates the data topology, we apply Persistent Homology (PH) to guide the selection of that sub-complex by considering detected topological features. We use each unlabeled point’s link and star operators to provide different-sized and multi-dimensional neighborhoods to propagate labels from labeled to unlabeled points. The labeling function depends on the filtration’s entire history of the filtered simplicial complex and it is encoded within the persistence diagrams at various dimensions. We select eight datasets with different dimensions, degrees of class overlap, and imbalanced samples per class to validate our method. The TDABC outperforms all baseline methods classifying multi-class imbalanced data with high imbalanced ratios and data with overlapped classes. Also, on average, the proposed method was better than K Nearest Neighbors (KNN) and weighted KNN and behaved competitively with Support Vector Machine and Random Forest baseline classifiers in balanced datasets.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


