Gaining insights in datasets in the shade of “garbage in, garbage out” rationale: Feature space distribution fitting
IF 11.7
2区 计算机科学
Q1 COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE
Wiley Interdisciplinary Reviews-Data Mining and Knowledge Discovery
Pub Date : 2022-03-30
DOI:10.1002/widm.1456
引用次数: 4
Abstract
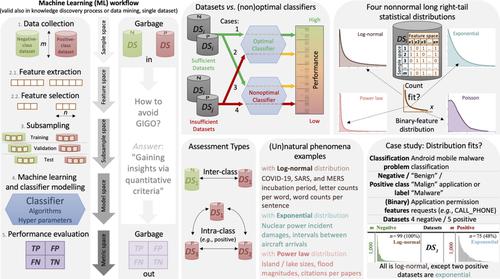
This article emphasizes comprehending the “Garbage In, Garbage Out” (GIGO) rationale and ensuring the dataset quality in Machine Learning (ML) applications to achieve high and generalizable performance. An initial step should be added in an ML workflow where researchers evaluate the insights gained by quantitative analysis of the datasets sample and feature spaces. This study contributes towards achieving such a goal by suggesting a technique to quantify datasets in terms of feature frequency distribution characteristics. Hence a unique insight is provided into how the features in the available dataset samples are frequent. The technique was demonstrated in 11 benign and malign (malware) Android application datasets belonging to six academic Android mobile malware classification studies. The permissions requested by applications such as CALL_PHONE compose a relatively high‐dimensional binary feature space. The results showed that the distributions fit well into two of the four long right‐tail statistical distributions: log‐normal, exponential, power law, and Poisson. Precisely, log‐normal was the most exhibited statistical distribution except the two malign datasets that were in exponential. This study also explores statistical distribution fit/unfit feature analysis that enhances the insights in feature space. Finally, the study compiles phenomena examples in the literature exhibiting these statistical distributions that should be considered for interpreting the fitted distributions. In conclusion, conducting well‐formed statistical methods provides a clear understanding of the datasets and intra‐class and inter‐class differences before proceeding with selecting features and building a classifier model. Feature distribution characteristics should be one to analyze beforehand.
在“垃圾输入,垃圾输出”原理的阴影下获得数据集的见解:特征空间分布拟合
本文强调理解“垃圾输入,垃圾输出”(GIGO)的基本原理,并确保机器学习(ML)应用程序中的数据集质量,以实现高且可推广的性能。应该在ML工作流程中添加初始步骤,研究人员评估通过数据集样本和特征空间的定量分析获得的见解。本研究通过提出一种根据特征频率分布特征量化数据集的技术,为实现这一目标做出了贡献。因此,对于可用数据集样本中的特征是如何频繁出现的,提供了独特的见解。该技术在属于6个学术Android移动恶意软件分类研究的11个良性和恶意(恶意软件)Android应用程序数据集中进行了演示。CALL_PHONE等应用程序请求的权限构成了一个相对高维的二进制特征空间。结果表明,这些分布很好地符合四种长右尾统计分布中的两种:对数正态分布、指数分布、幂律分布和泊松分布。准确地说,除了两个呈指数的恶性数据集外,对数正态分布是最明显的统计分布。本研究还探讨了统计分布适合/不适合特征分析,以增强对特征空间的洞察力。最后,研究汇编了文献中显示这些统计分布的现象示例,这些统计分布应被考虑用于解释拟合分布。总之,在继续选择特征和构建分类器模型之前,执行格式良好的统计方法可以清楚地了解数据集以及类内和类间的差异。特征分布特征是需要事先分析的。
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文
来源期刊

Wiley Interdisciplinary Reviews-Data Mining and Knowledge Discovery
COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE-COMPUTER SCIENCE, THEORY & METHODS
CiteScore
22.70
自引率
2.60%
发文量
39
审稿时长
>12 weeks
期刊介绍:
The goals of Wiley Interdisciplinary Reviews-Data Mining and Knowledge Discovery (WIREs DMKD) are multifaceted. Firstly, the journal aims to provide a comprehensive overview of the current state of data mining and knowledge discovery by featuring ongoing reviews authored by leading researchers. Secondly, it seeks to highlight the interdisciplinary nature of the field by presenting articles from diverse perspectives, covering various application areas such as technology, business, healthcare, education, government, society, and culture. Thirdly, WIREs DMKD endeavors to keep pace with the rapid advancements in data mining and knowledge discovery through regular content updates. Lastly, the journal strives to promote active engagement in the field by presenting its accomplishments and challenges in an accessible manner to a broad audience. The content of WIREs DMKD is intended to benefit upper-level undergraduate and postgraduate students, teaching and research professors in academic programs, as well as scientists and research managers in industry.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


