{"title":"Denoising DNA Encoded Library Screens with Sparse Learning","authors":"Péter Kómár*, Marko Kalinić*","doi":"10.1021/acscombsci.0c00007","DOIUrl":null,"url":null,"abstract":"<p >DNA-encoded libraries (DELs) are large, pooled collections of compounds in which every library member is attached to a stretch of DNA encoding its complete synthetic history. DEL-based hit discovery involves affinity selection of the library against a protein of interest, whereby compounds retained by the target are subsequently identified by next-generation sequencing of the corresponding DNA tags. When analyzing the resulting data, one typically assumes that sequencing output (i.e., read counts) is proportional to the binding affinity of a given compound, thus enabling hit prioritization and elucidation of any underlying structure–activity relationships (SAR). This assumption, though, tends to be severely confounded by a number of factors, including variable reaction yields, presence of incomplete products masquerading as their intended counterparts, and sequencing noise. In practice, these confounders are often ignored, potentially contributing to low hit validation rates, and universally leading to loss of valuable information. To address this issue, we have developed a method for comprehensively denoising DEL selection outputs. Our method, dubbed “deldenoiser”, is based on sparse learning and leverages inputs that are commonly available within a DEL generation and screening workflow. Using simulated and publicly available DEL affinity selection data, we show that “deldenoiser” is not only able to recover and rank true binders much more robustly than read count-based approaches but also that it yields scores, which accurately capture the underlying SAR. The proposed method can, thus, be of significant utility in hit prioritization following DEL screens.</p>","PeriodicalId":3,"journal":{"name":"ACS Applied Electronic Materials","volume":null,"pages":null},"PeriodicalIF":4.3000,"publicationDate":"2020-06-12","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://sci-hub-pdf.com/10.1021/acscombsci.0c00007","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"ACS Applied Electronic Materials","FirstCategoryId":"92","ListUrlMain":"https://pubs.acs.org/doi/10.1021/acscombsci.0c00007","RegionNum":3,"RegionCategory":"材料科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"ENGINEERING, ELECTRICAL & ELECTRONIC","Score":null,"Total":0}
引用次数: 0
Abstract
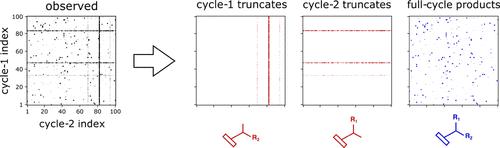
DNA-encoded libraries (DELs) are large, pooled collections of compounds in which every library member is attached to a stretch of DNA encoding its complete synthetic history. DEL-based hit discovery involves affinity selection of the library against a protein of interest, whereby compounds retained by the target are subsequently identified by next-generation sequencing of the corresponding DNA tags. When analyzing the resulting data, one typically assumes that sequencing output (i.e., read counts) is proportional to the binding affinity of a given compound, thus enabling hit prioritization and elucidation of any underlying structure–activity relationships (SAR). This assumption, though, tends to be severely confounded by a number of factors, including variable reaction yields, presence of incomplete products masquerading as their intended counterparts, and sequencing noise. In practice, these confounders are often ignored, potentially contributing to low hit validation rates, and universally leading to loss of valuable information. To address this issue, we have developed a method for comprehensively denoising DEL selection outputs. Our method, dubbed “deldenoiser”, is based on sparse learning and leverages inputs that are commonly available within a DEL generation and screening workflow. Using simulated and publicly available DEL affinity selection data, we show that “deldenoiser” is not only able to recover and rank true binders much more robustly than read count-based approaches but also that it yields scores, which accurately capture the underlying SAR. The proposed method can, thus, be of significant utility in hit prioritization following DEL screens.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


