Doctor Versus Artificial Intelligence: Patient and Physician Evaluation of Large Language Model Responses to Rheumatology Patient Questions in a Cross-Sectional Study
Abstract
Objective
The objective of the current study was to assess the quality of large language model (LLM) chatbot versus physician-generated responses to patient-generated rheumatology questions.
Methods
We conducted a single-center cross-sectional survey of rheumatology patients (n = 17) in Edmonton, Alberta, Canada. Patients evaluated LLM chatbot versus physician-generated responses for comprehensiveness and readability, with four rheumatologists also evaluating accuracy by using a Likert scale from 1 to 10 (1 being poor, 10 being excellent).
Results
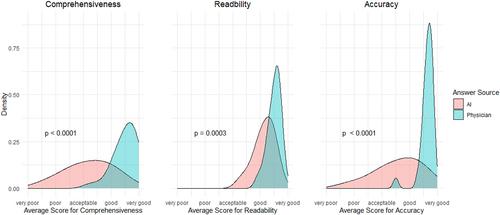
Patients rated no significant difference between artificial intelligence (AI) and physician-generated responses in comprehensiveness (mean 7.12 ± SD 0.99 vs 7.52 ± 1.16; P = 0.1962) or readability (7.90 ± 0.90 vs 7.80 ± 0.75; P = 0.5905). Rheumatologists rated AI responses significantly poorer than physician responses on comprehensiveness (AI 5.52 ± 2.13 vs physician 8.76 ± 1.07; P < 0.0001), readability (AI 7.85 ± 0.92 vs physician 8.75 ± 0.57; P = 0.0003), and accuracy (AI 6.48 ± 2.07 vs physician 9.08 ± 0.64; P < 0.0001). The proportion of preference to AI- versus physician-generated responses by patients and physicians was 0.45 ± 0.18 and 0.15 ± 0.08, respectively (P = 0.0106). After learning that one answer for each question was AI generated, patients were able to correctly identify AI-generated answers at a lower proportion compared to physicians (0.49 ± 0.26 vs 0.97 ± 0.04; P = 0.0183). The average word count of AI answers was 69.10 ± 25.35 words, as compared to 98.83 ± 34.58 words for physician-generated responses (P = 0.0008).
Conclusion
Rheumatology patients rated AI-generated responses to patient questions similarly to physician-generated responses in terms of comprehensiveness, readability, and overall preference. However, rheumatologists rated AI responses significantly poorer than physician-generated responses, suggesting that LLM chatbot responses are inferior to physician responses, a difference that patients may not be aware of.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


