Megan Schröder, Sam H A Muller, Eleni Vradi, Johanna Mielke, Yvonne M F Lim, Fabrice Couvelard, Menno Mostert, Stefan Koudstaal, Marinus J C Eijkemans, Christoph Gerlinger
{"title":"Sharing Medical Big Data While Preserving Patient Confidentiality in Innovative Medicines Initiative: A Summary and Case Report from BigData@Heart.","authors":"Megan Schröder, Sam H A Muller, Eleni Vradi, Johanna Mielke, Yvonne M F Lim, Fabrice Couvelard, Menno Mostert, Stefan Koudstaal, Marinus J C Eijkemans, Christoph Gerlinger","doi":"10.1089/big.2022.0178","DOIUrl":null,"url":null,"abstract":"<p><p>Sharing individual patient data (IPD) is a simple concept but complex to achieve due to data privacy and data security concerns, underdeveloped guidelines, and legal barriers. Sharing IPD is additionally difficult in big data-driven collaborations such as Bigdata@Heart in the Innovative Medicines Initiative, due to competing interests between diverse consortium members. One project within BigData@Heart, case study 1, needed to pool data from seven heterogeneous data sets: five randomized controlled trials from three different industry partners, and two disease registries. Sharing IPD was not considered feasible due to legal requirements and the sensitive medical nature of these data. In addition, harmonizing the data sets for a federated data analysis was difficult due to capacity constraints and the heterogeneity of the data sets. An alternative option was to share summary statistics through contingency tables. Here it is demonstrated that this method along with anonymization methods to ensure patient anonymity had minimal loss of information. Although sharing IPD should continue to be encouraged and strived for, our approach achieved a good balance between data transparency while protecting patient privacy. It also allowed a successful collaboration between industry and academia.</p>","PeriodicalId":51314,"journal":{"name":"Big Data","volume":" ","pages":"399-407"},"PeriodicalIF":2.6000,"publicationDate":"2023-12-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10733752/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Big Data","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1089/big.2022.0178","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2023/10/27 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS","Score":null,"Total":0}
引用次数: 0
Abstract
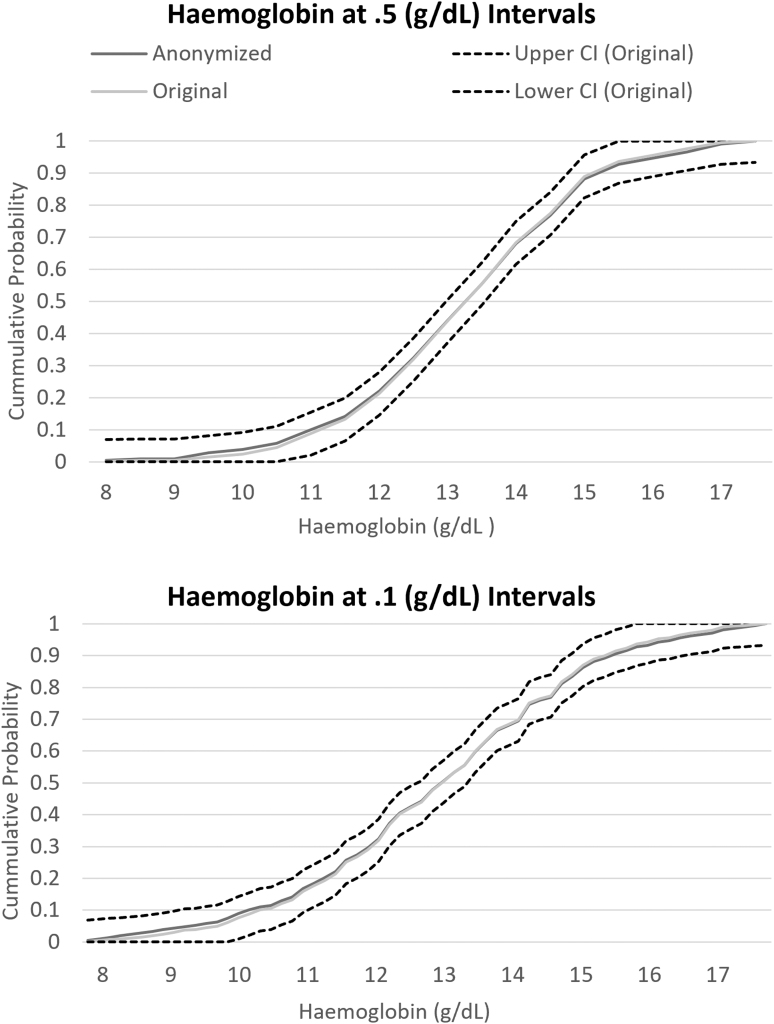
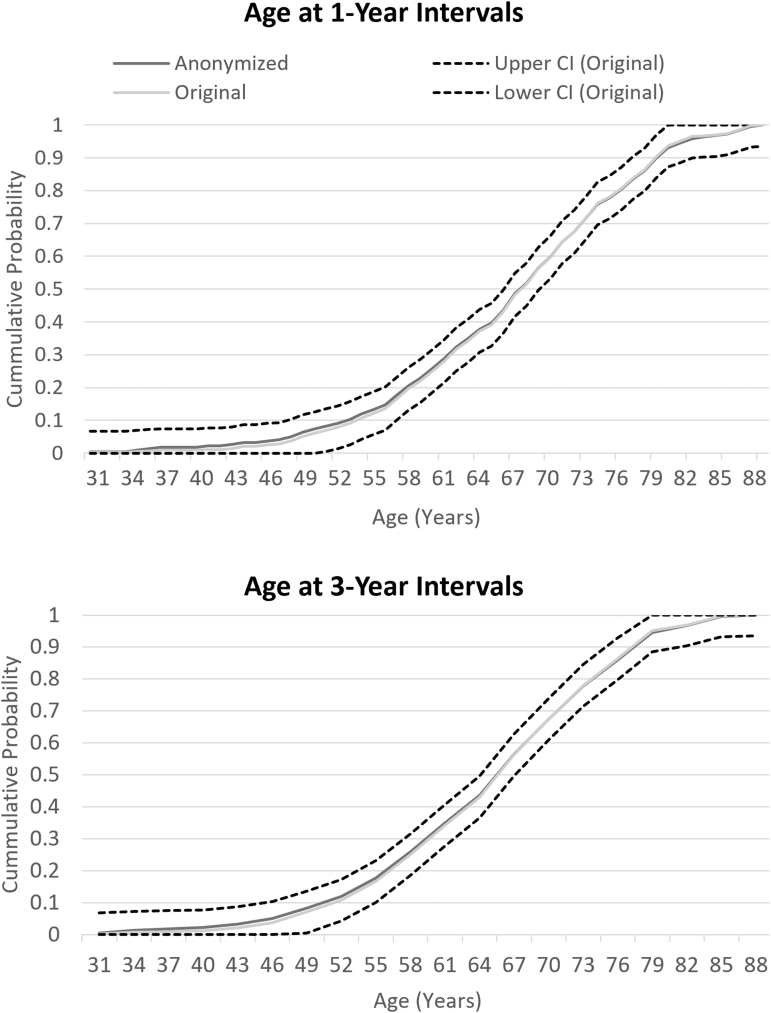
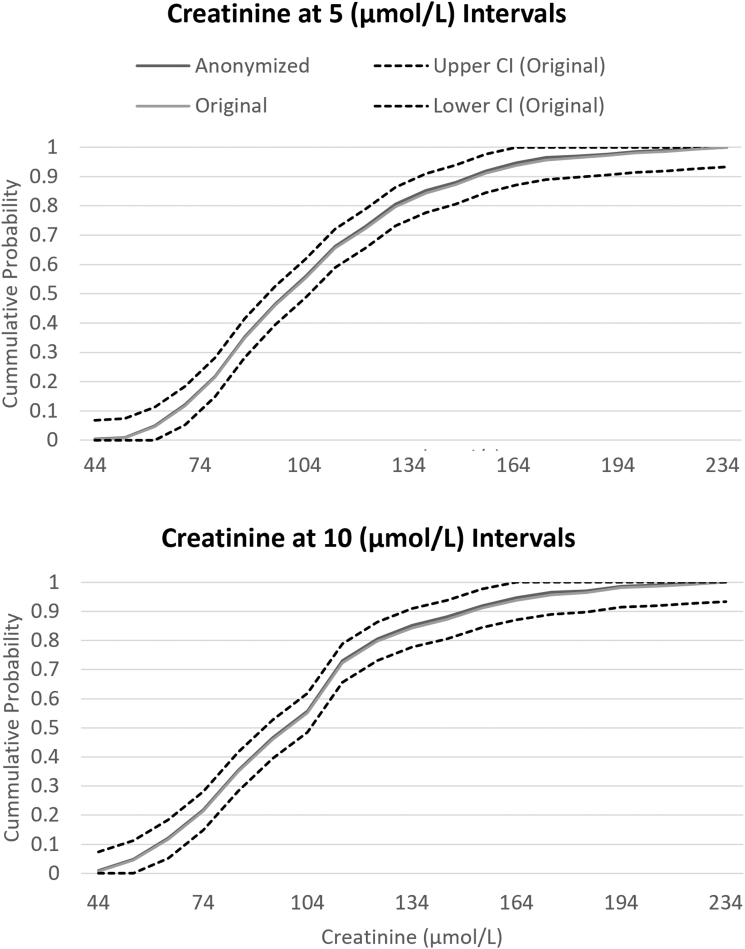
Sharing individual patient data (IPD) is a simple concept but complex to achieve due to data privacy and data security concerns, underdeveloped guidelines, and legal barriers. Sharing IPD is additionally difficult in big data-driven collaborations such as Bigdata@Heart in the Innovative Medicines Initiative, due to competing interests between diverse consortium members. One project within BigData@Heart, case study 1, needed to pool data from seven heterogeneous data sets: five randomized controlled trials from three different industry partners, and two disease registries. Sharing IPD was not considered feasible due to legal requirements and the sensitive medical nature of these data. In addition, harmonizing the data sets for a federated data analysis was difficult due to capacity constraints and the heterogeneity of the data sets. An alternative option was to share summary statistics through contingency tables. Here it is demonstrated that this method along with anonymization methods to ensure patient anonymity had minimal loss of information. Although sharing IPD should continue to be encouraged and strived for, our approach achieved a good balance between data transparency while protecting patient privacy. It also allowed a successful collaboration between industry and academia.
Big DataCOMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS-COMPUTER SCIENCE, THEORY & METHODS
CiteScore
9.10
自引率
2.20%
发文量
60
期刊介绍:
Big Data is the leading peer-reviewed journal covering the challenges and opportunities in collecting, analyzing, and disseminating vast amounts of data. The Journal addresses questions surrounding this powerful and growing field of data science and facilitates the efforts of researchers, business managers, analysts, developers, data scientists, physicists, statisticians, infrastructure developers, academics, and policymakers to improve operations, profitability, and communications within their businesses and institutions.
Spanning a broad array of disciplines focusing on novel big data technologies, policies, and innovations, the Journal brings together the community to address current challenges and enforce effective efforts to organize, store, disseminate, protect, manipulate, and, most importantly, find the most effective strategies to make this incredible amount of information work to benefit society, industry, academia, and government.
Big Data coverage includes:
Big data industry standards,
New technologies being developed specifically for big data,
Data acquisition, cleaning, distribution, and best practices,
Data protection, privacy, and policy,
Business interests from research to product,
The changing role of business intelligence,
Visualization and design principles of big data infrastructures,
Physical interfaces and robotics,
Social networking advantages for Facebook, Twitter, Amazon, Google, etc,
Opportunities around big data and how companies can harness it to their advantage.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


