Danelle M. Larson, Wako Bungula, Amber Lee, Alaina Stockdill, Casey McKean, Frederick "Forrest" Miller, Killian Davis, Richard A. Erickson, Enrika Hlavacek
{"title":"Reconstructing missing data by comparing interpolation techniques: Applications for long-term water quality data","authors":"Danelle M. Larson, Wako Bungula, Amber Lee, Alaina Stockdill, Casey McKean, Frederick \"Forrest\" Miller, Killian Davis, Richard A. Erickson, Enrika Hlavacek","doi":"10.1002/lom3.10556","DOIUrl":null,"url":null,"abstract":"<p>Missing data are typical yet must be addressed for proper inferences or expanding datasets to guide our limnological understanding and management of aquatic systems. Interpolation methods (i.e., estimating missing values using known values within the dataset) can alleviate data gaps and common problems. We compared seven popular interpolation methods for predicting substantial missingness in a long-term water quality dataset from the Upper Mississippi River, U.S.A. The dataset included 80,000 sampling sites collected over 30 yr that had substantial missingness for total nitrogen (TN), total phosphorus (TP), and water velocity. For all three interpolated water quality variables, random forests had very high prediction accuracy and outperformed the methods of ordinary kriging, polynomial regressions, regression trees, and inverse distance weighting. TP had a mean absolute error (MAE) of 0.03 mg (L-TP)<sup>−1</sup>, TN had a MAE of 0.39 mg (L-TN)<sup>−1</sup>, and water velocity had a MAE of 0.10 m s<sup>−1</sup>. The random forests' error rates were mapped and showed low spatiotemporal variability across the riverscape, indicating high model performance across many habitat types and large spatial scales. In the current era of “big data,” interpolation becomes an imperative step prior to ecological analyses yet remains unfamiliar and underutilized. Our research briefly describes the importance of addressing missingness and provides a roadmap to conduct model intercomparisons of other big datasets. We also share adaptable data analysis scripts, which allows others to readily conduct interpolation comparisons for many limnology applications and contexts.</p>","PeriodicalId":18145,"journal":{"name":"Limnology and Oceanography: Methods","volume":"21 7","pages":"435-449"},"PeriodicalIF":2.1000,"publicationDate":"2023-05-30","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1002/lom3.10556","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Limnology and Oceanography: Methods","FirstCategoryId":"89","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1002/lom3.10556","RegionNum":3,"RegionCategory":"地球科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"LIMNOLOGY","Score":null,"Total":0}
引用次数: 0
Abstract
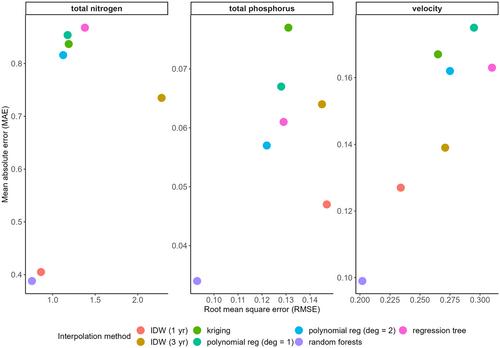
Missing data are typical yet must be addressed for proper inferences or expanding datasets to guide our limnological understanding and management of aquatic systems. Interpolation methods (i.e., estimating missing values using known values within the dataset) can alleviate data gaps and common problems. We compared seven popular interpolation methods for predicting substantial missingness in a long-term water quality dataset from the Upper Mississippi River, U.S.A. The dataset included 80,000 sampling sites collected over 30 yr that had substantial missingness for total nitrogen (TN), total phosphorus (TP), and water velocity. For all three interpolated water quality variables, random forests had very high prediction accuracy and outperformed the methods of ordinary kriging, polynomial regressions, regression trees, and inverse distance weighting. TP had a mean absolute error (MAE) of 0.03 mg (L-TP)−1, TN had a MAE of 0.39 mg (L-TN)−1, and water velocity had a MAE of 0.10 m s−1. The random forests' error rates were mapped and showed low spatiotemporal variability across the riverscape, indicating high model performance across many habitat types and large spatial scales. In the current era of “big data,” interpolation becomes an imperative step prior to ecological analyses yet remains unfamiliar and underutilized. Our research briefly describes the importance of addressing missingness and provides a roadmap to conduct model intercomparisons of other big datasets. We also share adaptable data analysis scripts, which allows others to readily conduct interpolation comparisons for many limnology applications and contexts.
期刊介绍:
Limnology and Oceanography: Methods (ISSN 1541-5856) is a companion to ASLO''s top-rated journal Limnology and Oceanography, and articles are held to the same high standards. In order to provide the most rapid publication consistent with high standards, Limnology and Oceanography: Methods appears in electronic format only, and the entire submission and review system is online. Articles are posted as soon as they are accepted and formatted for publication.
Limnology and Oceanography: Methods will consider manuscripts whose primary focus is methodological, and that deal with problems in the aquatic sciences. Manuscripts may present new measurement equipment, techniques for analyzing observations or samples, methods for understanding and interpreting information, analyses of metadata to examine the effectiveness of approaches, invited and contributed reviews and syntheses, and techniques for communicating and teaching in the aquatic sciences.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


