Beth Davis-Sramek, Alex Scott, Robert Glenn Richey Jr
{"title":"A case and framework for expanding the use of model-free evidence","authors":"Beth Davis-Sramek, Alex Scott, Robert Glenn Richey Jr","doi":"10.1111/jbl.12330","DOIUrl":null,"url":null,"abstract":"<p>The business logistics and supply chain management (L&SCM) discipline has a history of doctoral education that emphasizes the use of empirical research to make contributions to theory and practice. This training is evident in manuscript submissions and published research. As such, the structure of a manuscript has “generally expected” components. Authors are expected to: (1) introduce a relevant research question that addresses a specific logistics or supply chain phenomenon; (2) theorize about relationships between constructs that are presented within a nomological network; (3) offer extensive information about how the constructs are operationalized at the empirical level (i.e. variables); and (4) detail the statistical model used to test the hypothesized relationships and evaluate whether these relationships are meaningful or not.1</p><p>The application of statistical modeling is a fundamental and necessary component of empirically focused manuscripts in demonstrating the rigor and credibility of the findings. However, we suggest that “model-free evidence”2 is underutilized in the discipline. We write this first editorial of 2023 to support, when appropriate, model-free evidence as an additional “generally expected” manuscript component. We have asked our colleague Alex Scott to join us as a coauthor because his publications serve as an exemplar in providing context and explanation for our call to incorporate this analysis into manuscripts.</p><p>An overreliance on complex statistical models and output (i.e. model-based analysis) has potential pitfalls. For example, statistical models require assumptions to be valid, and these assumptions can range from the relatively simple (e.g. the constant variance assumption) to the very complicated (e.g. overidentification in the Arellano–Bond estimator) to the untestable (e.g. parallel trends in difference-in-differences after treatment3). When single-point estimates or regression coefficients from model output are reported in a manuscript, it can be difficult for editors, reviewers, and fellow colleagues to understand the nature of the relationship between variables beyond those estimates, which are conditional on the modeling assumptions. Furthermore, the inclusion of different control variables can flip the signs and change the interpretation of statistical results. While critical for addressing many research questions, output from a statistical model can (and should) always be questioned by the reader, and it often does not fully illustrate the relationship between variables.</p><p>In the following pages, we offer our rationale for increasing the use of model-free evidence <i>in conjunction</i> with model-based analysis. We believe that adopting its use more fully can improve the credibility of our research with respect to our academic peers and external stakeholders, which is an important goal of the <i>Journal of Business Logistics</i> (<i>JBL</i>) (Richey & Davis-Sramek, <span>2022a</span>). Although we do not intend for this to be a “how-to” guide, we define model-free evidence and explain our rationale for incorporating it into manuscripts. We give additional context by describing the process that we used in a recent manuscript that incorporated model-free evidence (Scott & Davis-Sramek, <span>2022</span>). Furthermore, we provide a simple framework with an accompanying example to advance the basic principles for producing and communicating model-free evidence in a manuscript. We conclude by emphasizing how it can benefit researchers and more importantly, the consumers of our research. In the final section of the paper, we introduce the articles that make up the first issue of 2023.</p><p>We define model-free evidence as an empirical analysis used to identify correlations between variables or patterns in the dataset, which allows for a descriptive representation of the data. This evidence is typically presented as either a visualization or a tabulation to illustrate relationships between variables across multiple dimensions. Unlike point estimates from a statistical model that often do not demonstrate the variation in a dataset very well, summary tables and visualizations can clearly and succinctly show the underlying variation, identify potential outliers, and differentiate observed or latent categories in the data. This empirical analysis has also been described as descriptive data, summary data, and data visualizations, although we would like to see the field adopt the term model-free evidence to avoid confusion. Regardless of the label, the use of model-free evidence has long been considered valuable for research (Chatfield, <span>1985</span>; Tukey, <span>1977</span>) and continues to be emphasized and utilized today (e.g. Acimovic et al., <span>2022</span>; Alhauli et al., <span>2022</span>; Mahoney, <span>2022</span>; Scott & Nyaga, <span>2019</span>).</p><p>A classic example of the power of model-free evidence comes from the work of Florence Nightingale. During her work as a nurse during the Crimean War in the 1850s, Nightingale observed that the “disgraceful state” of the sanitary conditions in military hospitals caused thousands of unnecessary deaths of both soldiers and staff (Kopf, <span>1916</span>). She advocated for the systematic collection of better data (admissions, deaths, and causes of death) and presented it in innovative and influential ways (Magnello, <span>2012</span>). Her relatively simple representations saved countless lives because the disturbing patterns that emerged from the data were both clear and credible for those who had the authority to address the problems.</p><p>Of course, L&SCM academic research calls for the combination of model-free evidence and rigorous statistical analysis. Once the former illustrates that interesting and potentially meaningful correlations between variables exist, the latter is needed to assess the significance and magnitude of the relationships. Statistical models are also necessary to rule out alternative explanations, control for potential confounding factors, and test for significance under certain conditions. The combination can be particularly persuasive when theorizing and testing how a phenomenon changes over time or whether a specific event impacts relationships between variables. The illustration of model-free evidence from a longitudinal dataset can highlight the pattern of variation over time or after an event occurs, which combined with model-based analysis, offers powerful evidence to support these types of relationships.</p><p>In a recent study by Alex and Beth (Scott & Davis-Sramek, <span>2022</span>),4 we utilized model-free evidence in writing the manuscript to explain and strengthen the contribution of the research. We offer a first-hand perspective on its usefulness throughout the research design and manuscript writing process. In the narrative that follows, we provide the motivation for the research, results from the initial data analysis, and the additional insights into the model-free evidence. We conclude with an overview of how we used it in the manuscript to provide additional support and explanation of the hypotheses testing and results.</p><p>Our initial research question was rather straightforward and required nothing more than a descriptive analysis: What is the proportion of over-the-road female truck drivers in the United States? The prevailing statistic in the business press is 10% (Coker, <span>2019</span>), but the industry study that produced it was fatally flawed. After filing a freedom of information request from the Federal Motor Carrier Safety Administration, we got a longitudinal dataset with almost 20 million datapoints. The results from the initial analysis yielded the proportion of women as 3.2% in 2019, and this was an increase from 2.6% in 2010.</p><p>Although it was satisfying to answer our initial question, there was little academic value in simply correcting the record. Our next line of inquiry was to understand how and why the distribution of female drivers was spread across different job types (e.g. truckload, less-than-truckload, private, and local). The results of this analysis revealed an intriguing pattern, and we applied a theoretical lens to explain why a large proportion of women truck drivers work in the least desirable jobs (i.e. large, long-haul, and for-hire truckload carriers with high-turnover rates compared with less-than-truckload or private carriers with much lower turnover rates). Using a logit model, statistical analysis confirmed that the variation between high- and low-turnover jobs was significant, and we also confirmed that the variation decreased significantly over time (i.e. there was a significantly smaller proportion of women in high-turnover jobs in 2019 than in 2010).</p><p>What started as a descriptive empirical question turned into a theoretically derived study that added value to the academic body of the literature. While the entirety of the manuscript included extensive information that covered the “generally expected” components, we felt strongly that incorporating model-free evidence was critical to support and strengthen the credibility of the model-based analysis. Thus, in drafting the manuscript, we had to consider the best way to provide a visual illustration. We settled on using a tabular representation to summarize the proportion of women truck drivers from 2010 to 2019 (see Table 1 below). Next, we introduced a figure that included three variables—turnover rate, job type, and the percentage of female drivers to visually illustrate that women disproportionately hold the least preferred jobs than men (See Figure 1 below).</p><p>Plagued with a chronic shortage of drivers and minimal success to recruit women, academic research in the trucking industry can yield meaningful policy implications. As such, we concluded the manuscript with an extensive policy discussion. Because the inclusion of model-free evidence makes the manuscript more consumable for an external audience, our original intent remains unchanged: to leverage this study to correct the flawed statistic being circulated in the business press. We also hope to advance policy discussions about how to better recruit and retain women truck drivers in the industry.</p><p>While the design and inclusion of model-free evidence is up to the L&SCM researcher and depends on the data, there are basic principles that can be used in most, if not all, cases. We outline them using a recent <i>JBL</i> article authored by Alex (Scott, <span>2018</span>) as an exemplar. We chose this study due to his intimate knowledge of the process involved in creating it. Using data provided by a large shipper, Scott (<span>2018</span>) examined the bidding behavior of carriers in the shipper's auctions for short-term truckload service (i.e. spot). By collecting data from thousands of auctions over several years, he theorized and tested how and why carriers' market specialization (broker, asset-based, or both) influences their propensity to bid and the price at which they bid. Using this study, Figure 2 provides a framework for each step to consider when utilizing model-free evidence in a manuscript. It also demonstrates how each one was used to produce a visual representation of the model-free evidence in the Scott's (<span>2018</span>) article.</p><p>As illustrated in Figure 2, the first step involves being explicit about the level of theorizing in the paper. Is the unit of analysis the firm? Individual? Buyer–supplier dyad? The model-free evidence presented in the paper should be consistent with the level of theorizing and corresponding unit of analysis. In Scott (<span>2018</span>), the motivation was to explain the differences between firms, so the theorizing, and thus the unit of analysis, was at the firm level.</p><p>The second step entails focusing on the variables of interest. Typically, the dependent variable(s), independent variable(s), and time when considering longitudinal variation are central to the study. There can also be situations in which relationships between independent or dependent variables and control variables could be of interest. Scott (<span>2018</span>) focused on one independent variable, (i.e. type of carrier), as being an important predictor of how often a carrier bids in a spot auction (i.e. carrier propensity to bid), and the price of their bids (i.e. carrier bid premium).</p><p>The third step is to consider the source of variation in the data. Is the most important variation in the data cross-sectional, longitudinal, or both? Is the study of an event affecting some groups but not others? If theorizing about the relationships between variables reflects what occurs in practice, the data will reflect the source of the variation. For Scott (<span>2018</span>), model-free evidence reflected between-firm variation based on the three types of carriers.</p><p>The final step is to consider the best way to capture model-free evidence through a visual representation that is designed for both simplicity and clarity. Sometimes, the data presented in a table will suffice to explain a pattern in the data, but it is often more illustrative to use a graphical representation of the data to show the variation between variables. While it is beyond the scope of the editorial to do so here, authors should follow the principles espoused in the many sources on graphical display such as clarity, simplicity, and minimizing “chartjunk” (Tufte, <span>2002</span>).</p><p>The arrow in the final step in Figure 2 points to the model-free evidence illustrated in Scott (<span>2018</span>). While this (or any other) representation is a matter of taste, it is important to point out that the figure does not contain extraneous information, text, or lines. The bid frequency and bid premiums are displayed for individual carriers, with the carrier's specialization illustrated by different shapes and colors. This visual supports the theorizing that there are differences in behavior between types of carriers, and it further enhances the results of the model-based analysis.</p><p>In closing, we want to stress that we are not making the utilization of model-free evidence a requirement for publishing in <i>JBL</i>, but we would like to see it become more “generally accepted.” This is especially useful when our statistical methods become more specialized, and even the most seasoned academics may not fully understand the assumptions and output when reading an article or reviewing a manuscript. In fact, it is common for reviewers to question the credibility of a study's results when they claim that authors use “overly complicated statistical models” to analyze the data. It has long been understood that we can fool ourselves and others with statistics (Huff, <span>1954</span>).</p><p>Model-free evidence can help researchers improve the credibility of their research, which is a point of emphasis in business and economics disciplines (e.g. Angrist & Pischke, <span>2010</span>; Leamer, <span>1983</span>). By showing that the theoretically relevant relationships exist in the underlying data, and so long as the data accurately capture the phenomena of interest, support for the results of model-based analysis can be strengthened. There is less cause for concern for readers and reviewers to question the results, even when they may not fully understand the assumptions and mechanics of the statistical model.</p><p>As the saying goes, “a picture is worth a thousand words,” and this is especially true in data analysis. The story of Florence Nightingale points to the significance of systematically collecting data at a granular level, analyzing it to understand problems, and presenting it in a way that supports the need for action and change. The use of model-free evidence, especially in the form of tables and visuals, is easier for nonacademics to understand, and hence it can increase the impact of our work. So long as it is backed by statistical rigor, it could be the single most important and influential takeaway from an academic study. Demonstrating the impact of our research outside of our academic bubble is becoming increasingly important (Richey & Davis-Sramek, <span>2022b</span>), and we are committed to helping <i>JBL</i> authors demonstrate the value of their research to both their internal and their external stakeholders.</p><p>We are pleased to introduce the first issue of 2023 with six articles that all showcase exceptional theoretical and theoretical rigor, which is “the price of admission” for publication in JBL. Just as important, however, these six articles offer rich implications for practice. As our tenure as editors continues, we expect that all the articles within the issues of the Journal will reflect the field's ability to engage in scholarship that matters (Richey & Davis-Sramek, <span>2022b</span>).</p><p>Two of the articles in the issue offer an important contribution to expanding theory in the supply chain management (SCM) domain. Enz and Lambert (<span>2022</span>) bring attention to SCM in the service sector. The note is that most supply chain management research has focused on product flows, which limits the ability of service companies to benefit from the creation of SCM process implementation frameworks. The contribution of this research is an extension of previous theoretical development of SCM for services. Utilizing insights from practice, the authors develop a framework to manage service supply chains, consisting of six key processes, emphasizing that the customer relationship management and supplier relationship management processes form the most critical links.</p><p>Ralston et al. (<span>2022</span>) also offer rich theoretical insight by proposing factor market rivalry (FMR) as a SCM theory because of its emphasis on resource competition and resource scarcity. As supply chains become more complex and global, leveraging supply chain orientation is now a source of competitive advantage for firms. The intense competition for resource positions required to produce and deliver goods and services makes FMR an appropriate theoretical lens to understand and explain supply chain phenomena. The authors offer a constructive and robust agenda that outlines future research opportunities aligned with an FMR approach.</p><p>The Hughes et al.'s (<span>2022</span>) article on this issue offers a theoretically motivated understanding of what the authors call a “plastic response” to supply chain disruptions. There has been a significant emphasis in JBL on the topic of supply chain resilience, including a special topic forum (e.g. Davis-Sramek & Richey, <span>2021</span>; Novak et al., <span>2021</span>; Wiedmer et al., <span>2021</span>; Wieland & Durach, <span>2021</span>), but this study offers a new perspective on resilience. Contrasting traditional resilience research's emphasis on restoration in the wake of supply chain disruption, the premise of a plastic response is significantly redesigning the supply chain. Utilizing a qualitative approach and insights from change management theory, the authors develop propositions about how firms enable this response and when it is more likely to be exercised.</p><p>Three of the six articles in this issue reflect the growing domain of SCM research related to the omnichannel retail phenomenon (Ishfaq et al., <span>2022</span>; Kembro et al., <span>2022</span>). Two are more narrowly aligned with the consumer-centric nature of retail supply chains (e.g. Esper et al., <span>2020</span>; Peinkofer et al., <span>2022</span>) and one highlights the significance of last-mile delivery (Castillo et al., <span>2022</span>; Lu et al., <span>2020</span>). We have encouraged this avenue of research, so it is satisfying that half of this issue includes articles that expand this area.</p><p>Jin et al. (<span>2022</span>) take a customer-centric approach by examining the “buy online pickup in store” (BOPIS) model used by retailers. While BOPIS offers consumers a convenient option, it often creates difficulties that lead to inventory inaccuracy and service failures. To mitigate the effect of service failures, retailers have increased the use of substitution options for consumers. The authors note, however, that consumer response to retail substitution policies is not clear. This research fills this important gap using a series of scenario-based experiments to examine several nuances related to how consumers perceive retailers' use of cross-channel substitution as a service recovery policy.</p><p>Also focusing attention on consumer behavior to examine retail inventory strategy, Pan et al. (<span>2022</span>) ask a timely research question about consumer buying habits during economic downturns. They focus their attention specifically on the ability of retailers to predict consumer stockpiling behavior in recessionary economic conditions. Using both consumer panel and retail scanner datasets, the authors differentiate between stockpiling and nonstockpiling consumer segments. They find that when consumer confidence in the economic conditions is low, both consumer segments respond by reducing consumption rates. However, the stockpiling segment significantly lengthens the time between shopping trips, which increases the duration of inventory holdings. Their message to retailers is significant: Shifts in consumer behavior add complexity to inventory planning, and a decrease in consumer consumption does not always necessitate the need for less inventory.</p><p>Finally, Rose et al. (<span>2022</span>) focus their attention on consumers' increasing demand for last-mile delivery service. Retailers often outsource this activity, and many logistics service providers are small businesses that do not have access to complex technological routing solutions and use simple heuristics for delivery schedules and routes. Most heuristics, however, have been designed to optimize distance or travel times. Because consumer reaction to service failures can be detrimental to small logistics providers, the authors take an inductive based on behaviors observed in practice to develop a “regifting” heuristic that emphasizes customer service outcomes.</p><p>In sum, as we begin our third year as editors, we are grateful to the community of scholars who support the Journal and produce impactful research that we can showcase in the (digital) pages of JBL. Happy reading!</p>","PeriodicalId":48090,"journal":{"name":"Journal of Business Logistics","volume":"44 1","pages":"4-10"},"PeriodicalIF":11.2000,"publicationDate":"2023-01-12","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1111/jbl.12330","citationCount":"4","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Business Logistics","FirstCategoryId":"91","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1111/jbl.12330","RegionNum":2,"RegionCategory":"管理学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MANAGEMENT","Score":null,"Total":0}
引用次数: 4
Abstract
The business logistics and supply chain management (L&SCM) discipline has a history of doctoral education that emphasizes the use of empirical research to make contributions to theory and practice. This training is evident in manuscript submissions and published research. As such, the structure of a manuscript has “generally expected” components. Authors are expected to: (1) introduce a relevant research question that addresses a specific logistics or supply chain phenomenon; (2) theorize about relationships between constructs that are presented within a nomological network; (3) offer extensive information about how the constructs are operationalized at the empirical level (i.e. variables); and (4) detail the statistical model used to test the hypothesized relationships and evaluate whether these relationships are meaningful or not.1
The application of statistical modeling is a fundamental and necessary component of empirically focused manuscripts in demonstrating the rigor and credibility of the findings. However, we suggest that “model-free evidence”2 is underutilized in the discipline. We write this first editorial of 2023 to support, when appropriate, model-free evidence as an additional “generally expected” manuscript component. We have asked our colleague Alex Scott to join us as a coauthor because his publications serve as an exemplar in providing context and explanation for our call to incorporate this analysis into manuscripts.
An overreliance on complex statistical models and output (i.e. model-based analysis) has potential pitfalls. For example, statistical models require assumptions to be valid, and these assumptions can range from the relatively simple (e.g. the constant variance assumption) to the very complicated (e.g. overidentification in the Arellano–Bond estimator) to the untestable (e.g. parallel trends in difference-in-differences after treatment3). When single-point estimates or regression coefficients from model output are reported in a manuscript, it can be difficult for editors, reviewers, and fellow colleagues to understand the nature of the relationship between variables beyond those estimates, which are conditional on the modeling assumptions. Furthermore, the inclusion of different control variables can flip the signs and change the interpretation of statistical results. While critical for addressing many research questions, output from a statistical model can (and should) always be questioned by the reader, and it often does not fully illustrate the relationship between variables.
In the following pages, we offer our rationale for increasing the use of model-free evidence in conjunction with model-based analysis. We believe that adopting its use more fully can improve the credibility of our research with respect to our academic peers and external stakeholders, which is an important goal of the Journal of Business Logistics (JBL) (Richey & Davis-Sramek, 2022a). Although we do not intend for this to be a “how-to” guide, we define model-free evidence and explain our rationale for incorporating it into manuscripts. We give additional context by describing the process that we used in a recent manuscript that incorporated model-free evidence (Scott & Davis-Sramek, 2022). Furthermore, we provide a simple framework with an accompanying example to advance the basic principles for producing and communicating model-free evidence in a manuscript. We conclude by emphasizing how it can benefit researchers and more importantly, the consumers of our research. In the final section of the paper, we introduce the articles that make up the first issue of 2023.
We define model-free evidence as an empirical analysis used to identify correlations between variables or patterns in the dataset, which allows for a descriptive representation of the data. This evidence is typically presented as either a visualization or a tabulation to illustrate relationships between variables across multiple dimensions. Unlike point estimates from a statistical model that often do not demonstrate the variation in a dataset very well, summary tables and visualizations can clearly and succinctly show the underlying variation, identify potential outliers, and differentiate observed or latent categories in the data. This empirical analysis has also been described as descriptive data, summary data, and data visualizations, although we would like to see the field adopt the term model-free evidence to avoid confusion. Regardless of the label, the use of model-free evidence has long been considered valuable for research (Chatfield, 1985; Tukey, 1977) and continues to be emphasized and utilized today (e.g. Acimovic et al., 2022; Alhauli et al., 2022; Mahoney, 2022; Scott & Nyaga, 2019).
A classic example of the power of model-free evidence comes from the work of Florence Nightingale. During her work as a nurse during the Crimean War in the 1850s, Nightingale observed that the “disgraceful state” of the sanitary conditions in military hospitals caused thousands of unnecessary deaths of both soldiers and staff (Kopf, 1916). She advocated for the systematic collection of better data (admissions, deaths, and causes of death) and presented it in innovative and influential ways (Magnello, 2012). Her relatively simple representations saved countless lives because the disturbing patterns that emerged from the data were both clear and credible for those who had the authority to address the problems.
Of course, L&SCM academic research calls for the combination of model-free evidence and rigorous statistical analysis. Once the former illustrates that interesting and potentially meaningful correlations between variables exist, the latter is needed to assess the significance and magnitude of the relationships. Statistical models are also necessary to rule out alternative explanations, control for potential confounding factors, and test for significance under certain conditions. The combination can be particularly persuasive when theorizing and testing how a phenomenon changes over time or whether a specific event impacts relationships between variables. The illustration of model-free evidence from a longitudinal dataset can highlight the pattern of variation over time or after an event occurs, which combined with model-based analysis, offers powerful evidence to support these types of relationships.
In a recent study by Alex and Beth (Scott & Davis-Sramek, 2022),4 we utilized model-free evidence in writing the manuscript to explain and strengthen the contribution of the research. We offer a first-hand perspective on its usefulness throughout the research design and manuscript writing process. In the narrative that follows, we provide the motivation for the research, results from the initial data analysis, and the additional insights into the model-free evidence. We conclude with an overview of how we used it in the manuscript to provide additional support and explanation of the hypotheses testing and results.
Our initial research question was rather straightforward and required nothing more than a descriptive analysis: What is the proportion of over-the-road female truck drivers in the United States? The prevailing statistic in the business press is 10% (Coker, 2019), but the industry study that produced it was fatally flawed. After filing a freedom of information request from the Federal Motor Carrier Safety Administration, we got a longitudinal dataset with almost 20 million datapoints. The results from the initial analysis yielded the proportion of women as 3.2% in 2019, and this was an increase from 2.6% in 2010.
Although it was satisfying to answer our initial question, there was little academic value in simply correcting the record. Our next line of inquiry was to understand how and why the distribution of female drivers was spread across different job types (e.g. truckload, less-than-truckload, private, and local). The results of this analysis revealed an intriguing pattern, and we applied a theoretical lens to explain why a large proportion of women truck drivers work in the least desirable jobs (i.e. large, long-haul, and for-hire truckload carriers with high-turnover rates compared with less-than-truckload or private carriers with much lower turnover rates). Using a logit model, statistical analysis confirmed that the variation between high- and low-turnover jobs was significant, and we also confirmed that the variation decreased significantly over time (i.e. there was a significantly smaller proportion of women in high-turnover jobs in 2019 than in 2010).
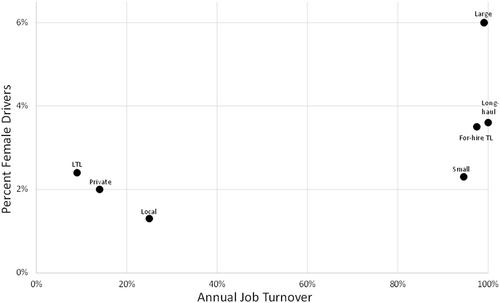
What started as a descriptive empirical question turned into a theoretically derived study that added value to the academic body of the literature. While the entirety of the manuscript included extensive information that covered the “generally expected” components, we felt strongly that incorporating model-free evidence was critical to support and strengthen the credibility of the model-based analysis. Thus, in drafting the manuscript, we had to consider the best way to provide a visual illustration. We settled on using a tabular representation to summarize the proportion of women truck drivers from 2010 to 2019 (see Table 1 below). Next, we introduced a figure that included three variables—turnover rate, job type, and the percentage of female drivers to visually illustrate that women disproportionately hold the least preferred jobs than men (See Figure 1 below).
Plagued with a chronic shortage of drivers and minimal success to recruit women, academic research in the trucking industry can yield meaningful policy implications. As such, we concluded the manuscript with an extensive policy discussion. Because the inclusion of model-free evidence makes the manuscript more consumable for an external audience, our original intent remains unchanged: to leverage this study to correct the flawed statistic being circulated in the business press. We also hope to advance policy discussions about how to better recruit and retain women truck drivers in the industry.
While the design and inclusion of model-free evidence is up to the L&SCM researcher and depends on the data, there are basic principles that can be used in most, if not all, cases. We outline them using a recent JBL article authored by Alex (Scott, 2018) as an exemplar. We chose this study due to his intimate knowledge of the process involved in creating it. Using data provided by a large shipper, Scott (2018) examined the bidding behavior of carriers in the shipper's auctions for short-term truckload service (i.e. spot). By collecting data from thousands of auctions over several years, he theorized and tested how and why carriers' market specialization (broker, asset-based, or both) influences their propensity to bid and the price at which they bid. Using this study, Figure 2 provides a framework for each step to consider when utilizing model-free evidence in a manuscript. It also demonstrates how each one was used to produce a visual representation of the model-free evidence in the Scott's (2018) article.
As illustrated in Figure 2, the first step involves being explicit about the level of theorizing in the paper. Is the unit of analysis the firm? Individual? Buyer–supplier dyad? The model-free evidence presented in the paper should be consistent with the level of theorizing and corresponding unit of analysis. In Scott (2018), the motivation was to explain the differences between firms, so the theorizing, and thus the unit of analysis, was at the firm level.
The second step entails focusing on the variables of interest. Typically, the dependent variable(s), independent variable(s), and time when considering longitudinal variation are central to the study. There can also be situations in which relationships between independent or dependent variables and control variables could be of interest. Scott (2018) focused on one independent variable, (i.e. type of carrier), as being an important predictor of how often a carrier bids in a spot auction (i.e. carrier propensity to bid), and the price of their bids (i.e. carrier bid premium).
The third step is to consider the source of variation in the data. Is the most important variation in the data cross-sectional, longitudinal, or both? Is the study of an event affecting some groups but not others? If theorizing about the relationships between variables reflects what occurs in practice, the data will reflect the source of the variation. For Scott (2018), model-free evidence reflected between-firm variation based on the three types of carriers.
The final step is to consider the best way to capture model-free evidence through a visual representation that is designed for both simplicity and clarity. Sometimes, the data presented in a table will suffice to explain a pattern in the data, but it is often more illustrative to use a graphical representation of the data to show the variation between variables. While it is beyond the scope of the editorial to do so here, authors should follow the principles espoused in the many sources on graphical display such as clarity, simplicity, and minimizing “chartjunk” (Tufte, 2002).
The arrow in the final step in Figure 2 points to the model-free evidence illustrated in Scott (2018). While this (or any other) representation is a matter of taste, it is important to point out that the figure does not contain extraneous information, text, or lines. The bid frequency and bid premiums are displayed for individual carriers, with the carrier's specialization illustrated by different shapes and colors. This visual supports the theorizing that there are differences in behavior between types of carriers, and it further enhances the results of the model-based analysis.
In closing, we want to stress that we are not making the utilization of model-free evidence a requirement for publishing in JBL, but we would like to see it become more “generally accepted.” This is especially useful when our statistical methods become more specialized, and even the most seasoned academics may not fully understand the assumptions and output when reading an article or reviewing a manuscript. In fact, it is common for reviewers to question the credibility of a study's results when they claim that authors use “overly complicated statistical models” to analyze the data. It has long been understood that we can fool ourselves and others with statistics (Huff, 1954).
Model-free evidence can help researchers improve the credibility of their research, which is a point of emphasis in business and economics disciplines (e.g. Angrist & Pischke, 2010; Leamer, 1983). By showing that the theoretically relevant relationships exist in the underlying data, and so long as the data accurately capture the phenomena of interest, support for the results of model-based analysis can be strengthened. There is less cause for concern for readers and reviewers to question the results, even when they may not fully understand the assumptions and mechanics of the statistical model.
As the saying goes, “a picture is worth a thousand words,” and this is especially true in data analysis. The story of Florence Nightingale points to the significance of systematically collecting data at a granular level, analyzing it to understand problems, and presenting it in a way that supports the need for action and change. The use of model-free evidence, especially in the form of tables and visuals, is easier for nonacademics to understand, and hence it can increase the impact of our work. So long as it is backed by statistical rigor, it could be the single most important and influential takeaway from an academic study. Demonstrating the impact of our research outside of our academic bubble is becoming increasingly important (Richey & Davis-Sramek, 2022b), and we are committed to helping JBL authors demonstrate the value of their research to both their internal and their external stakeholders.
We are pleased to introduce the first issue of 2023 with six articles that all showcase exceptional theoretical and theoretical rigor, which is “the price of admission” for publication in JBL. Just as important, however, these six articles offer rich implications for practice. As our tenure as editors continues, we expect that all the articles within the issues of the Journal will reflect the field's ability to engage in scholarship that matters (Richey & Davis-Sramek, 2022b).
Two of the articles in the issue offer an important contribution to expanding theory in the supply chain management (SCM) domain. Enz and Lambert (2022) bring attention to SCM in the service sector. The note is that most supply chain management research has focused on product flows, which limits the ability of service companies to benefit from the creation of SCM process implementation frameworks. The contribution of this research is an extension of previous theoretical development of SCM for services. Utilizing insights from practice, the authors develop a framework to manage service supply chains, consisting of six key processes, emphasizing that the customer relationship management and supplier relationship management processes form the most critical links.
Ralston et al. (2022) also offer rich theoretical insight by proposing factor market rivalry (FMR) as a SCM theory because of its emphasis on resource competition and resource scarcity. As supply chains become more complex and global, leveraging supply chain orientation is now a source of competitive advantage for firms. The intense competition for resource positions required to produce and deliver goods and services makes FMR an appropriate theoretical lens to understand and explain supply chain phenomena. The authors offer a constructive and robust agenda that outlines future research opportunities aligned with an FMR approach.
The Hughes et al.'s (2022) article on this issue offers a theoretically motivated understanding of what the authors call a “plastic response” to supply chain disruptions. There has been a significant emphasis in JBL on the topic of supply chain resilience, including a special topic forum (e.g. Davis-Sramek & Richey, 2021; Novak et al., 2021; Wiedmer et al., 2021; Wieland & Durach, 2021), but this study offers a new perspective on resilience. Contrasting traditional resilience research's emphasis on restoration in the wake of supply chain disruption, the premise of a plastic response is significantly redesigning the supply chain. Utilizing a qualitative approach and insights from change management theory, the authors develop propositions about how firms enable this response and when it is more likely to be exercised.
Three of the six articles in this issue reflect the growing domain of SCM research related to the omnichannel retail phenomenon (Ishfaq et al., 2022; Kembro et al., 2022). Two are more narrowly aligned with the consumer-centric nature of retail supply chains (e.g. Esper et al., 2020; Peinkofer et al., 2022) and one highlights the significance of last-mile delivery (Castillo et al., 2022; Lu et al., 2020). We have encouraged this avenue of research, so it is satisfying that half of this issue includes articles that expand this area.
Jin et al. (2022) take a customer-centric approach by examining the “buy online pickup in store” (BOPIS) model used by retailers. While BOPIS offers consumers a convenient option, it often creates difficulties that lead to inventory inaccuracy and service failures. To mitigate the effect of service failures, retailers have increased the use of substitution options for consumers. The authors note, however, that consumer response to retail substitution policies is not clear. This research fills this important gap using a series of scenario-based experiments to examine several nuances related to how consumers perceive retailers' use of cross-channel substitution as a service recovery policy.
Also focusing attention on consumer behavior to examine retail inventory strategy, Pan et al. (2022) ask a timely research question about consumer buying habits during economic downturns. They focus their attention specifically on the ability of retailers to predict consumer stockpiling behavior in recessionary economic conditions. Using both consumer panel and retail scanner datasets, the authors differentiate between stockpiling and nonstockpiling consumer segments. They find that when consumer confidence in the economic conditions is low, both consumer segments respond by reducing consumption rates. However, the stockpiling segment significantly lengthens the time between shopping trips, which increases the duration of inventory holdings. Their message to retailers is significant: Shifts in consumer behavior add complexity to inventory planning, and a decrease in consumer consumption does not always necessitate the need for less inventory.
Finally, Rose et al. (2022) focus their attention on consumers' increasing demand for last-mile delivery service. Retailers often outsource this activity, and many logistics service providers are small businesses that do not have access to complex technological routing solutions and use simple heuristics for delivery schedules and routes. Most heuristics, however, have been designed to optimize distance or travel times. Because consumer reaction to service failures can be detrimental to small logistics providers, the authors take an inductive based on behaviors observed in practice to develop a “regifting” heuristic that emphasizes customer service outcomes.
In sum, as we begin our third year as editors, we are grateful to the community of scholars who support the Journal and produce impactful research that we can showcase in the (digital) pages of JBL. Happy reading!
期刊介绍:
Supply chain management and logistics processes play a crucial role in the success of businesses, both in terms of operations, strategy, and finances. To gain a deep understanding of these processes, it is essential to explore academic literature such as The Journal of Business Logistics. This journal serves as a scholarly platform for sharing original ideas, research findings, and effective strategies in the field of logistics and supply chain management. By providing innovative insights and research-driven knowledge, it equips organizations with the necessary tools to navigate the ever-changing business environment.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


