Debiasing SHAP scores in random forests
IF 1.4
4区 数学
Q2 STATISTICS & PROBABILITY
引用次数: 0
Abstract
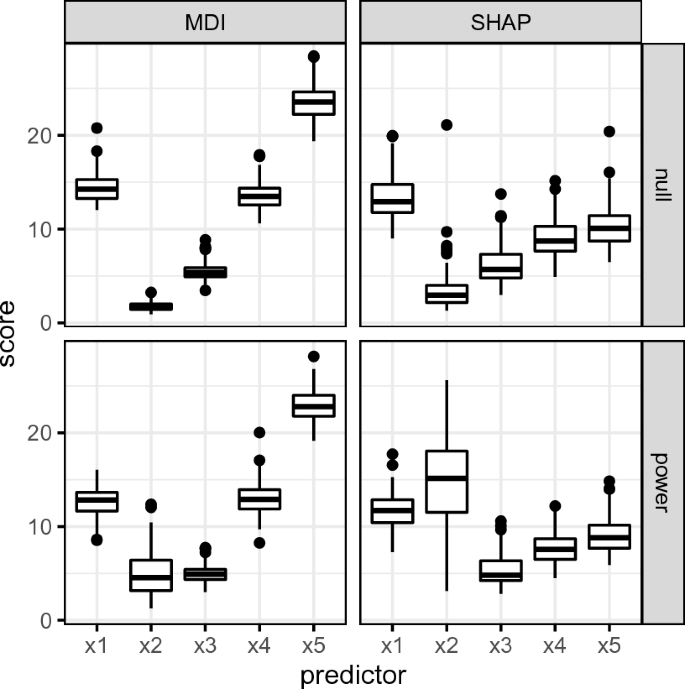
Black box machine learning models are currently being used for high-stakes decision making in various parts of society such as healthcare and criminal justice. While tree-based ensemble methods such as random forests typically outperform deep learning models on tabular data sets, their built-in variable importance algorithms are known to be strongly biased toward high-entropy features. It was recently shown that the increasingly popular SHAP (SHapley Additive exPlanations) values suffer from a similar bias. We propose debiased or "shrunk" SHAP scores based on sample splitting which additionally enable the detection of overfitting issues at the feature level.
在随机森林中去偏SHAP分数
黑盒机器学习模型目前正被用于医疗保健和刑事司法等社会各领域的高风险决策。虽然基于树的集合方法(如随机森林)在表格数据集上的表现通常优于深度学习模型,但众所周知,其内置的变量重要性算法严重偏向于高熵特征。最近的研究表明,日益流行的 SHAP(SHapley Additive exPlanations)值也存在类似的偏差。我们提出了基于样本拆分的去偏或 "缩减 "SHAP 分数,它还能在特征层面检测过拟合问题。
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文
来源期刊

Asta-Advances in Statistical Analysis
数学-统计学与概率论
CiteScore
2.20
自引率
14.30%
发文量
39
审稿时长
>12 weeks
期刊介绍:
AStA - Advances in Statistical Analysis, a journal of the German Statistical Society, is published quarterly and presents original contributions on statistical methods and applications and review articles.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


