Logging evaluation of favorable areas of a low porosity and permeability sandy conglomerate reservoir based on machine learning
Abstract
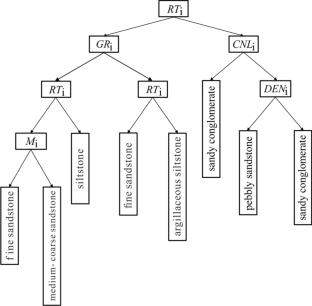
The sandy conglomerate reservoir in layer Es3 of the Liaohe Eastern Depression has good potential for oil reservoir exploration and has been identified as a key area for future exploration. The low porosity and permeability, complex lithology, and strong heterogeneity of the target layer make it difficult to predict favorable reservoirs. The objective of this study is to analyze and process conventional logging data to extract feature parameters that affect lithology by establishing a decision tree lithology classifier. Principal component analysis is used to reduce data dimensionality, and the elbow method is applied to the clustering algorithm to establish the optimal number of clusters for the automatic classification of reservoir types. Further, support vector machines are used for lithology classification based on features with higher classification capabilities. The results show that the support vector machine lithology recognition method based on feature selection achieved an accuracy of 91.8%. The processing of actual well data has verified the feasibility of the method. Based on the combination of core experiments and oil testing results, the characteristics of three types of reservoirs were presented, and potential reservoir zones were proposed for drilling wells. The comprehensive analysis and the practical application of the developed method reveal that the class I reservoir has high hydrocarbon production and could be the most favorable reservoir in the Es3 sandy conglomerate. The processing data of lithology identification and reservoir classification evaluation are consistent with core data and hydrocarbon production data, verifying the effectiveness and practicability of the method proposed in this paper. The results of this study will serve as a reference for low porosity and permeability sandy conglomerate reservoir evaluation based on machine learning in the target area.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


