{"title":"Learning latent representations to co-adapt to humans","authors":"Sagar Parekh, Dylan P. Losey","doi":"10.1007/s10514-023-10109-5","DOIUrl":null,"url":null,"abstract":"<div><p>When robots interact with humans in homes, roads, or factories the human’s behavior often changes in response to the robot. Non-stationary humans are challenging for robot learners: actions the robot has learned to coordinate with the original human may fail after the human adapts to the robot. In this paper we introduce an algorithmic formalism that enables robots (i.e., ego agents) to <i>co-adapt</i> alongside dynamic humans (i.e., other agents) using only the robot’s low-level states, actions, and rewards. A core challenge is that humans not only react to the robot’s behavior, but the way in which humans react inevitably changes both over time and between users. To deal with this challenge, our insight is that—instead of building an exact model of the human–robots can learn and reason over <i>high-level representations</i> of the human’s policy and policy dynamics. Applying this insight we develop RILI: Robustly Influencing Latent Intent. RILI first embeds low-level robot observations into predictions of the human’s latent strategy and strategy dynamics. Next, RILI harnesses these predictions to select actions that influence the adaptive human towards advantageous, high reward behaviors over repeated interactions. We demonstrate that—given RILI’s measured performance with users sampled from an underlying distribution—we can probabilistically bound RILI’s expected performance across new humans sampled from the same distribution. Our simulated experiments compare RILI to state-of-the-art representation and reinforcement learning baselines, and show that RILI better learns to coordinate with imperfect, noisy, and time-varying agents. Finally, we conduct two user studies where RILI co-adapts alongside actual humans in a game of tag and a tower-building task. See videos of our user studies here: https://youtu.be/WYGO5amDXbQ</p></div>","PeriodicalId":55409,"journal":{"name":"Autonomous Robots","volume":"47 6","pages":"771 - 796"},"PeriodicalIF":3.7000,"publicationDate":"2023-06-17","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://link.springer.com/content/pdf/10.1007/s10514-023-10109-5.pdf","citationCount":"4","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Autonomous Robots","FirstCategoryId":"94","ListUrlMain":"https://link.springer.com/article/10.1007/s10514-023-10109-5","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 4
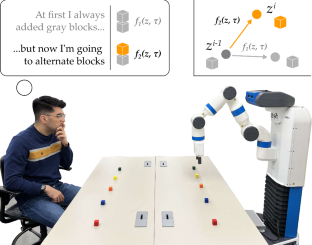
Abstract
When robots interact with humans in homes, roads, or factories the human’s behavior often changes in response to the robot. Non-stationary humans are challenging for robot learners: actions the robot has learned to coordinate with the original human may fail after the human adapts to the robot. In this paper we introduce an algorithmic formalism that enables robots (i.e., ego agents) to co-adapt alongside dynamic humans (i.e., other agents) using only the robot’s low-level states, actions, and rewards. A core challenge is that humans not only react to the robot’s behavior, but the way in which humans react inevitably changes both over time and between users. To deal with this challenge, our insight is that—instead of building an exact model of the human–robots can learn and reason over high-level representations of the human’s policy and policy dynamics. Applying this insight we develop RILI: Robustly Influencing Latent Intent. RILI first embeds low-level robot observations into predictions of the human’s latent strategy and strategy dynamics. Next, RILI harnesses these predictions to select actions that influence the adaptive human towards advantageous, high reward behaviors over repeated interactions. We demonstrate that—given RILI’s measured performance with users sampled from an underlying distribution—we can probabilistically bound RILI’s expected performance across new humans sampled from the same distribution. Our simulated experiments compare RILI to state-of-the-art representation and reinforcement learning baselines, and show that RILI better learns to coordinate with imperfect, noisy, and time-varying agents. Finally, we conduct two user studies where RILI co-adapts alongside actual humans in a game of tag and a tower-building task. See videos of our user studies here: https://youtu.be/WYGO5amDXbQ
期刊介绍:
Autonomous Robots reports on the theory and applications of robotic systems capable of some degree of self-sufficiency. It features papers that include performance data on actual robots in the real world. Coverage includes: control of autonomous robots · real-time vision · autonomous wheeled and tracked vehicles · legged vehicles · computational architectures for autonomous systems · distributed architectures for learning, control and adaptation · studies of autonomous robot systems · sensor fusion · theory of autonomous systems · terrain mapping and recognition · self-calibration and self-repair for robots · self-reproducing intelligent structures · genetic algorithms as models for robot development.
The focus is on the ability to move and be self-sufficient, not on whether the system is an imitation of biology. Of course, biological models for robotic systems are of major interest to the journal since living systems are prototypes for autonomous behavior.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


