A Dataset of 108 Novel Noun-Noun Compound Words with Active and Passive Interpretation.
Journal of open psychology data
Pub Date : 2023-08-29
eCollection Date: 2023-01-01
DOI:10.5334/jopd.93
引用次数: 0
Abstract
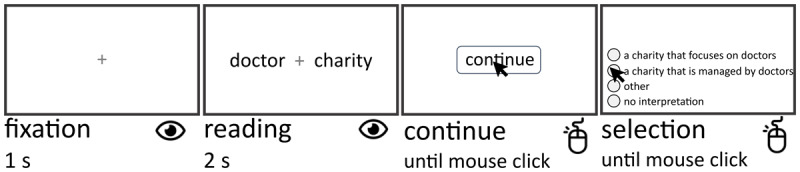
We created a dataset of 205 English novel noun-noun compounds (NNCs, e.g., "doctor charity") by combining nouns with higher and lower agentivity (i.e., the probability of being an agent in a sentence). We collected active and passive interpretations of NNCs from a group of 58 English native speakers. We then measured interpretation time differences between NNCs with active and passive interpretations (i.e., 108 NNCs), using data obtained from a group of 68 English native speakers. Data were collected online using crowdsourcing platforms (SONA and Prolific). The datasets are available at osf.io/gvc2w/ and can be used to address questions about semantic and syntactic composition.
108个新颖名词-名词复合词的主被动解释数据集
我们通过组合具有较高和较低代理性(即在句子中成为代理的概率)的名词,创建了一个由205个英语新名词-名词复合物(NNCs,例如“doctor charity”)组成的数据集。我们收集了58名以英语为母语的人对NNC的主动和被动解释。然后,我们使用从68名英语母语者中获得的数据,测量了具有主动和被动解释的NNC(即108个NNC)之间的解释时间差异。数据是使用众包平台(SONA和Prolific)在线收集的。这些数据集可在osf.io/gvc2w/上获得,可用于解决有关语义和句法组成的问题。
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


