Jason Miller, Andrew Balthrop, Beth Davis-Sramek, Robert Glenn Richey Jr
{"title":"Unobserved variables in archival research: Achieving both theoretical and statistical identification","authors":"Jason Miller, Andrew Balthrop, Beth Davis-Sramek, Robert Glenn Richey Jr","doi":"10.1111/jbl.12358","DOIUrl":null,"url":null,"abstract":"<p>A welcomed addition to the logistics and supply chain management (L&SCM) research landscape has been growth in the use of archival data, defined as data collected by an entity outside the research team (Miller et al., <span>2021</span>). Expansion in the use of archival data is stimulated by discussions concerning the generally accepted limitations of primary data research and related debate about when and how the use of primary data is appropriate (e.g., Montabon et al., <span>2018</span>; Schoenherr et al., <span>2015</span>). Concurrently, there has been recognition that research utilizing archival data opens new avenues of emphasis for L&SCM research in answering a wide array of questions. When archival data is generated from industry and operations (e.g., DeHoratius et al., <span>2022</span>), direct application may be enhanced. Additionally, archival data is highly accessible, which aids in both replication and extension (Pagell, <span>2021</span>).</p><p>As with every research design, archival data poses multiple limitations, and there are unique challenges as researchers employing the data are detached from the original collection process. Recent articles have tackled issues concerning how to establish strong validity claims for measures derived from archival sources (Miller et al., <span>2021</span>) and how to formulate statistical models that ensure theoretical hypotheses map to estimated parameters (Ketokivi et al., <span>2021</span>). We refer to this as <i>statistical identification</i>, which focuses on the confidence that an estimated statistical parameter (e.g., regression coefficient) is reasonably unbiased and not overly sensitive to changes in the structure of the statistical model. Possibly the greatest threat to statistical identification is the existence of one or more unmeasured variables that reside theoretically upstream or parallel to the independent variables. If included as predictors in a statistical model, these variables could be significantly related to the outcome variable. This is highly problematic if the estimates of the independent variables could shift substantially (Miller & Kulpa, <span>2022</span>). We see a significant amount of emphasis on this aspect of the research, and the general remedy involves utilizing a combination of control variables and performing robustness tests (sometimes in excessive numbers) to rule out alternative explanations.</p><p>One fundamental issue that has not been adequately addressed in L&SCM research is related to theorizing. Theorizing involves devising hypotheses that will be tested with this archival data. It is not enough to develop statistical models where there is a reasonable degree of confidence that focal parameters are statistically identified. It is just as important to provide evidence of <i>theoretical identification</i>, defined here as the existence of strong and convincing rationale(s) that the theorized mechanisms bring to the reported results. Because archival data do not capture the unobserved processes that are postulated to bring about hypothesized relationships, theorizing in archival research can sometimes be more challenging than when using primary methods (Godfrey & Hill, <span>1995</span>; Ketokivi & Mantere, <span>2021</span>). Lack of guidance on this issue is problematic as it can (a) encourage research that presents “novel” findings without solid theoretical reasoning, (b) discourage L&SCM researchers from answering important questions, and (c) cause confusion between authors and reviewers during the peer review process.</p><p>In this editorial, we hope to provide clarification to authors and reviewers about theorizing with archival data. We asked Dr. Jason Miller and Dr. Andy Balthrop to co-author this manuscript given their exceptional methodological expertise in this area. To address the need for theoretical identification, we stress the importance of developing <i>mechanism-based explanations</i> when hypothesizing relationships between variables. We contend that it is critical in the research process to explicitly explain the “underlying entities, processes, or structures which operate in particular contexts to generate outcomes of interest” that are theorized to bring about the hypothesized effects (Astbury & Leeuw, <span>2010</span>, p. 368). The focus of offering mechanism-based explanations should be on developing logical arguments that explain unobserved underlying processes. It is these unobservable mechanisms, grounded in a study's context, that provide the rationale for hypotheses development concerning the directional relationships between selected variables (Bunge, <span>1997</span>).</p><p>In the sections that follow, we further clarify the role that theoretical identification should play in the research process. We also offer a 2 × 2 matrix to distinguish theoretical identification from statistical identification and we underscore why all research should feature both. Finally, we highlight the outstanding articles that are published in this issue.</p>","PeriodicalId":48090,"journal":{"name":"Journal of Business Logistics","volume":"44 3","pages":"292-299"},"PeriodicalIF":7.4000,"publicationDate":"2023-07-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1111/jbl.12358","citationCount":"1","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Business Logistics","FirstCategoryId":"91","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1111/jbl.12358","RegionNum":2,"RegionCategory":"管理学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MANAGEMENT","Score":null,"Total":0}
引用次数: 1
Abstract
A welcomed addition to the logistics and supply chain management (L&SCM) research landscape has been growth in the use of archival data, defined as data collected by an entity outside the research team (Miller et al., 2021). Expansion in the use of archival data is stimulated by discussions concerning the generally accepted limitations of primary data research and related debate about when and how the use of primary data is appropriate (e.g., Montabon et al., 2018; Schoenherr et al., 2015). Concurrently, there has been recognition that research utilizing archival data opens new avenues of emphasis for L&SCM research in answering a wide array of questions. When archival data is generated from industry and operations (e.g., DeHoratius et al., 2022), direct application may be enhanced. Additionally, archival data is highly accessible, which aids in both replication and extension (Pagell, 2021).
As with every research design, archival data poses multiple limitations, and there are unique challenges as researchers employing the data are detached from the original collection process. Recent articles have tackled issues concerning how to establish strong validity claims for measures derived from archival sources (Miller et al., 2021) and how to formulate statistical models that ensure theoretical hypotheses map to estimated parameters (Ketokivi et al., 2021). We refer to this as statistical identification, which focuses on the confidence that an estimated statistical parameter (e.g., regression coefficient) is reasonably unbiased and not overly sensitive to changes in the structure of the statistical model. Possibly the greatest threat to statistical identification is the existence of one or more unmeasured variables that reside theoretically upstream or parallel to the independent variables. If included as predictors in a statistical model, these variables could be significantly related to the outcome variable. This is highly problematic if the estimates of the independent variables could shift substantially (Miller & Kulpa, 2022). We see a significant amount of emphasis on this aspect of the research, and the general remedy involves utilizing a combination of control variables and performing robustness tests (sometimes in excessive numbers) to rule out alternative explanations.
One fundamental issue that has not been adequately addressed in L&SCM research is related to theorizing. Theorizing involves devising hypotheses that will be tested with this archival data. It is not enough to develop statistical models where there is a reasonable degree of confidence that focal parameters are statistically identified. It is just as important to provide evidence of theoretical identification, defined here as the existence of strong and convincing rationale(s) that the theorized mechanisms bring to the reported results. Because archival data do not capture the unobserved processes that are postulated to bring about hypothesized relationships, theorizing in archival research can sometimes be more challenging than when using primary methods (Godfrey & Hill, 1995; Ketokivi & Mantere, 2021). Lack of guidance on this issue is problematic as it can (a) encourage research that presents “novel” findings without solid theoretical reasoning, (b) discourage L&SCM researchers from answering important questions, and (c) cause confusion between authors and reviewers during the peer review process.
In this editorial, we hope to provide clarification to authors and reviewers about theorizing with archival data. We asked Dr. Jason Miller and Dr. Andy Balthrop to co-author this manuscript given their exceptional methodological expertise in this area. To address the need for theoretical identification, we stress the importance of developing mechanism-based explanations when hypothesizing relationships between variables. We contend that it is critical in the research process to explicitly explain the “underlying entities, processes, or structures which operate in particular contexts to generate outcomes of interest” that are theorized to bring about the hypothesized effects (Astbury & Leeuw, 2010, p. 368). The focus of offering mechanism-based explanations should be on developing logical arguments that explain unobserved underlying processes. It is these unobservable mechanisms, grounded in a study's context, that provide the rationale for hypotheses development concerning the directional relationships between selected variables (Bunge, 1997).
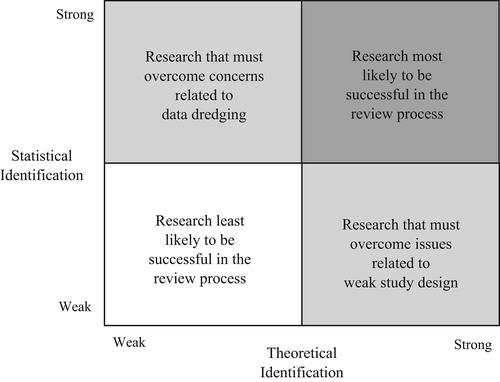
In the sections that follow, we further clarify the role that theoretical identification should play in the research process. We also offer a 2 × 2 matrix to distinguish theoretical identification from statistical identification and we underscore why all research should feature both. Finally, we highlight the outstanding articles that are published in this issue.
期刊介绍:
Supply chain management and logistics processes play a crucial role in the success of businesses, both in terms of operations, strategy, and finances. To gain a deep understanding of these processes, it is essential to explore academic literature such as The Journal of Business Logistics. This journal serves as a scholarly platform for sharing original ideas, research findings, and effective strategies in the field of logistics and supply chain management. By providing innovative insights and research-driven knowledge, it equips organizations with the necessary tools to navigate the ever-changing business environment.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


