John M Henderson, Taylor R Hayes, Candace E Peacock, Gwendolyn Rehrig
{"title":"Meaning and Attentional Guidance in Scenes: A Review of the Meaning Map Approach.","authors":"John M Henderson, Taylor R Hayes, Candace E Peacock, Gwendolyn Rehrig","doi":"10.3390/vision3020019","DOIUrl":null,"url":null,"abstract":"<p><p>Perception of a complex visual scene requires that important regions be prioritized and attentionally selected for processing. What is the basis for this selection? Although much research has focused on image salience as an important factor guiding attention, relatively little work has focused on semantic salience. To address this imbalance, we have recently developed a new method for measuring, representing, and evaluating the role of meaning in scenes. In this method, the spatial distribution of semantic features in a scene is represented as a meaning map. Meaning maps are generated from crowd-sourced responses given by naïve subjects who rate the meaningfulness of a large number of scene patches drawn from each scene. Meaning maps are coded in the same format as traditional image saliency maps, and therefore both types of maps can be directly evaluated against each other and against maps of the spatial distribution of attention derived from viewers' eye fixations. In this review we describe our work focusing on comparing the influences of meaning and image salience on attentional guidance in real-world scenes across a variety of viewing tasks that we have investigated, including memorization, aesthetic judgment, scene description, and saliency search and judgment. Overall, we have found that both meaning and salience predict the spatial distribution of attention in a scene, but that when the correlation between meaning and salience is statistically controlled, only meaning uniquely accounts for variance in attention.</p>","PeriodicalId":36586,"journal":{"name":"Vision (Switzerland)","volume":"3 2","pages":""},"PeriodicalIF":0.0000,"publicationDate":"2019-05-10","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://sci-hub-pdf.com/10.3390/vision3020019","citationCount":"40","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Vision (Switzerland)","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.3390/vision3020019","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"Medicine","Score":null,"Total":0}
引用次数: 40
Abstract
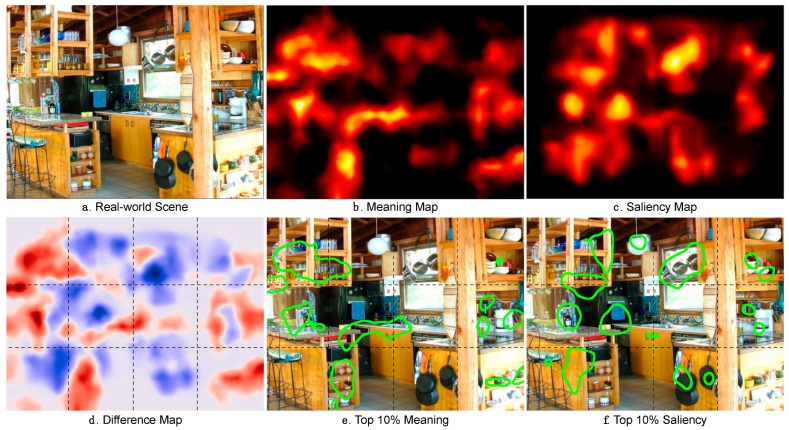
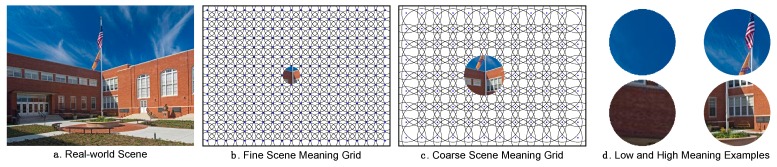
Perception of a complex visual scene requires that important regions be prioritized and attentionally selected for processing. What is the basis for this selection? Although much research has focused on image salience as an important factor guiding attention, relatively little work has focused on semantic salience. To address this imbalance, we have recently developed a new method for measuring, representing, and evaluating the role of meaning in scenes. In this method, the spatial distribution of semantic features in a scene is represented as a meaning map. Meaning maps are generated from crowd-sourced responses given by naïve subjects who rate the meaningfulness of a large number of scene patches drawn from each scene. Meaning maps are coded in the same format as traditional image saliency maps, and therefore both types of maps can be directly evaluated against each other and against maps of the spatial distribution of attention derived from viewers' eye fixations. In this review we describe our work focusing on comparing the influences of meaning and image salience on attentional guidance in real-world scenes across a variety of viewing tasks that we have investigated, including memorization, aesthetic judgment, scene description, and saliency search and judgment. Overall, we have found that both meaning and salience predict the spatial distribution of attention in a scene, but that when the correlation between meaning and salience is statistically controlled, only meaning uniquely accounts for variance in attention.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


