Peng Chen, Zhenlei Li, Zhaolin Hong, Haoran Zheng, Rong Zeng
{"title":"Tumor type classification and candidate cancer-specific biomarkers discovery via semi-supervised learning.","authors":"Peng Chen, Zhenlei Li, Zhaolin Hong, Haoran Zheng, Rong Zeng","doi":"10.52601/bpr.2023.230005","DOIUrl":null,"url":null,"abstract":"<p><p>Identifying cancer-related differentially expressed genes provides significant information for diagnosing tumors, predicting prognoses, and effective treatments. Recently, deep learning methods have been used to perform gene differential expression analysis using microarray-based high-throughput gene profiling and have achieved good results. In this study, we proposed a new robust multiple-datasets-based semi-supervised learning model, MSSL, to perform tumor type classification and candidate cancer-specific biomarkers discovery across multiple tumor types and multiple datasets, which addressed the following long-lasting obstacles: (1) the data volume of the existing single dataset is not enough to fully exert the advantages of deep learning; (2) a large number of datasets from different research institutions cannot be effectively used due to inconsistent internal variances and low quality; (3) relatively uncommon cancers have limited effects on deep learning methods. In our article, we applied MSSL to The Cancer Genome Atlas (TCGA) and the Gene Expression Comprehensive Database (GEO) pan-cancer normalized-level3 RNA-seq data and got 97.6% final classification accuracy, which had a significant performance leap compared with previous approaches. Finally, we got the ranking of the importance of the corresponding genes for each cancer type based on classification results and validated that the top genes selected in this way were biologically meaningful for corresponding tumors and some of them had been used as biomarkers, which showed the efficacy of our method.</p>","PeriodicalId":93906,"journal":{"name":"Biophysics reports","volume":"9 2","pages":"57-66"},"PeriodicalIF":0.0000,"publicationDate":"2023-04-30","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10518520/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Biophysics reports","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.52601/bpr.2023.230005","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
Identifying cancer-related differentially expressed genes provides significant information for diagnosing tumors, predicting prognoses, and effective treatments. Recently, deep learning methods have been used to perform gene differential expression analysis using microarray-based high-throughput gene profiling and have achieved good results. In this study, we proposed a new robust multiple-datasets-based semi-supervised learning model, MSSL, to perform tumor type classification and candidate cancer-specific biomarkers discovery across multiple tumor types and multiple datasets, which addressed the following long-lasting obstacles: (1) the data volume of the existing single dataset is not enough to fully exert the advantages of deep learning; (2) a large number of datasets from different research institutions cannot be effectively used due to inconsistent internal variances and low quality; (3) relatively uncommon cancers have limited effects on deep learning methods. In our article, we applied MSSL to The Cancer Genome Atlas (TCGA) and the Gene Expression Comprehensive Database (GEO) pan-cancer normalized-level3 RNA-seq data and got 97.6% final classification accuracy, which had a significant performance leap compared with previous approaches. Finally, we got the ranking of the importance of the corresponding genes for each cancer type based on classification results and validated that the top genes selected in this way were biologically meaningful for corresponding tumors and some of them had been used as biomarkers, which showed the efficacy of our method.
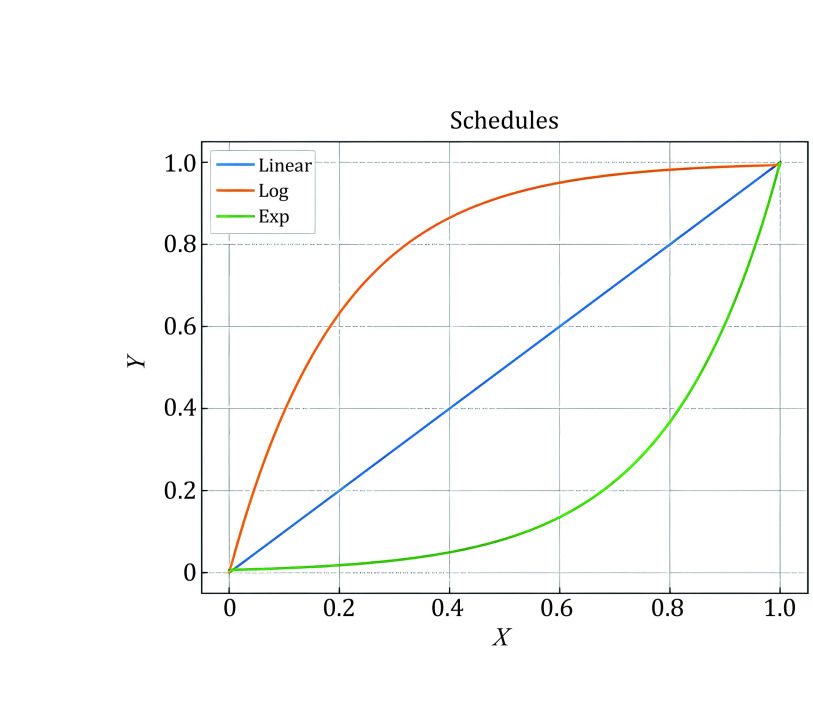
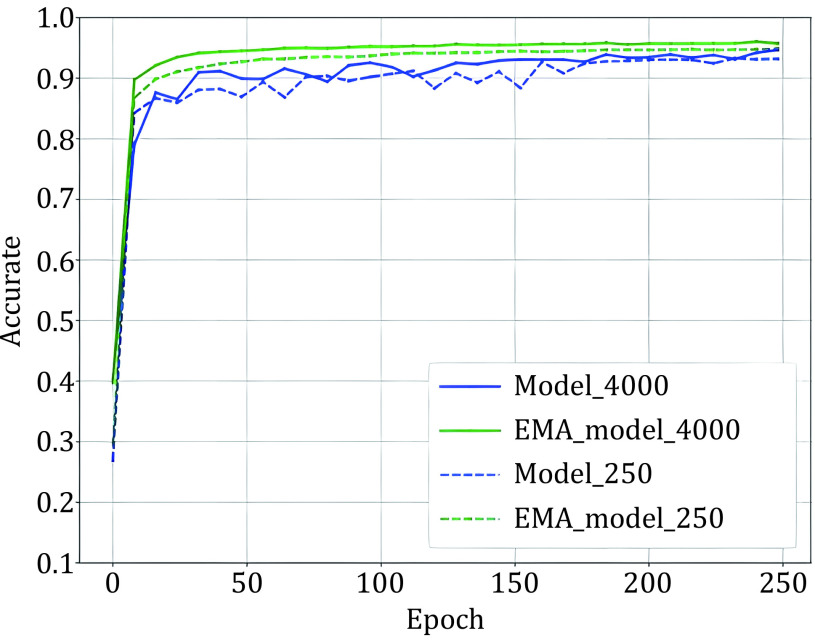
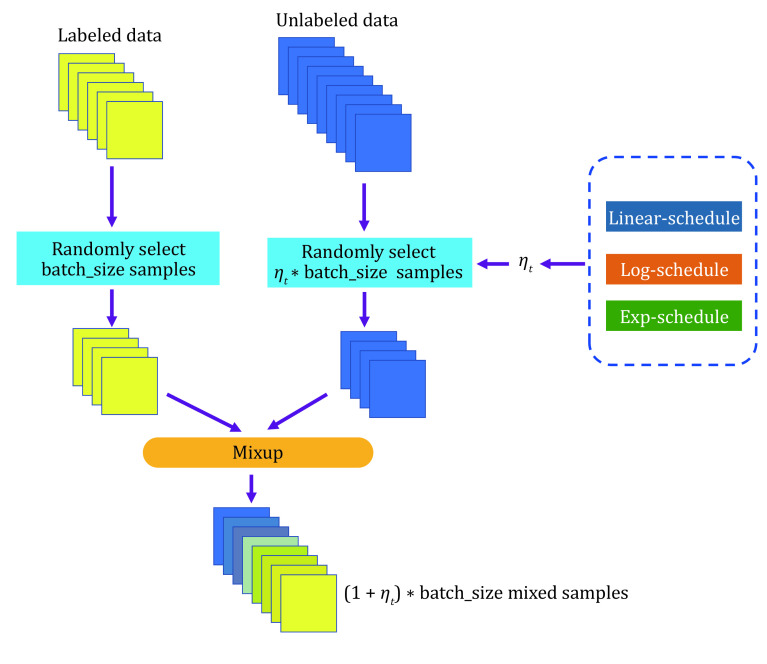

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


