{"title":"Enhancing Offensive Language Detection with Data Augmentation and Knowledge Distillation.","authors":"Jiawen Deng, Zhuang Chen, Hao Sun, Zhexin Zhang, Jincenzi Wu, Satoshi Nakagawa, Fuji Ren, Minlie Huang","doi":"10.34133/research.0189","DOIUrl":null,"url":null,"abstract":"<p><p>Offensive language detection has received important attention and plays a crucial role in promoting healthy communication on social platforms, as well as promoting the safe deployment of large language models. Training data is the basis for developing detectors; however, the available offense-related dataset in Chinese is severely limited in terms of data scale and coverage when compared to English resources. This significantly affects the accuracy of Chinese offensive language detectors in practical applications, especially when dealing with hard cases or out-of-domain samples. To alleviate the limitations posed by available datasets, we introduce AugCOLD (Augmented Chinese Offensive Language Dataset), a large-scale unsupervised dataset containing 1 million samples gathered by data crawling and model generation. Furthermore, we employ a multiteacher distillation framework to enhance detection performance with unsupervised data. That is, we build multiple teachers with publicly accessible datasets and use them to assign soft labels to AugCOLD. The soft labels serve as a bridge for knowledge to be distilled from both AugCOLD and multiteacher to the student network, i.e., the final offensive detector. We conduct experiments on multiple public test sets and our well-designed hard tests, demonstrating that our proposal can effectively improve the generalization and robustness of the offensive language detector.</p>","PeriodicalId":21120,"journal":{"name":"Research","volume":"6 ","pages":"0189"},"PeriodicalIF":11.0000,"publicationDate":"2023-09-18","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10506735/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Research","FirstCategoryId":"103","ListUrlMain":"https://doi.org/10.34133/research.0189","RegionNum":1,"RegionCategory":"综合性期刊","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2023/1/1 0:00:00","PubModel":"eCollection","JCR":"Q1","JCRName":"Multidisciplinary","Score":null,"Total":0}
引用次数: 0
Abstract
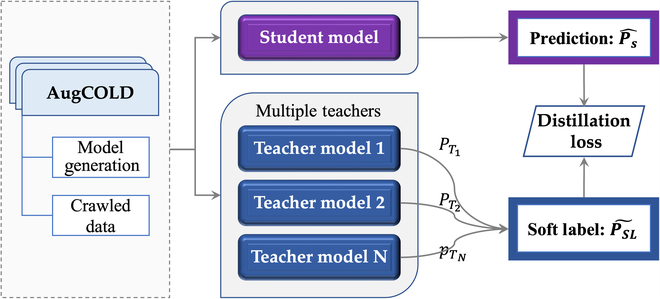
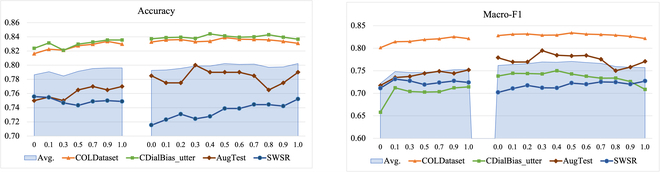
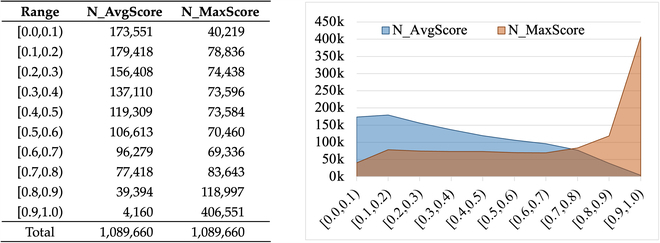
Offensive language detection has received important attention and plays a crucial role in promoting healthy communication on social platforms, as well as promoting the safe deployment of large language models. Training data is the basis for developing detectors; however, the available offense-related dataset in Chinese is severely limited in terms of data scale and coverage when compared to English resources. This significantly affects the accuracy of Chinese offensive language detectors in practical applications, especially when dealing with hard cases or out-of-domain samples. To alleviate the limitations posed by available datasets, we introduce AugCOLD (Augmented Chinese Offensive Language Dataset), a large-scale unsupervised dataset containing 1 million samples gathered by data crawling and model generation. Furthermore, we employ a multiteacher distillation framework to enhance detection performance with unsupervised data. That is, we build multiple teachers with publicly accessible datasets and use them to assign soft labels to AugCOLD. The soft labels serve as a bridge for knowledge to be distilled from both AugCOLD and multiteacher to the student network, i.e., the final offensive detector. We conduct experiments on multiple public test sets and our well-designed hard tests, demonstrating that our proposal can effectively improve the generalization and robustness of the offensive language detector.
攻击性语言检测受到了重要关注,在促进社交平台上的健康交流以及促进大型语言模型的安全部署方面发挥着至关重要的作用。训练数据是开发探测器的基础;然而,与英语资源相比,可用的中文攻击相关数据集在数据规模和覆盖范围方面受到严重限制。这显著影响了汉语攻击性语言检测器在实际应用中的准确性,尤其是在处理疑难案件或领域外样本时。为了缓解现有数据集的局限性,我们引入了AugCOLD(Augmented Chinese Offensive Language Dataset),这是一个大规模的无监督数据集,包含通过数据爬行和模型生成收集的100万个样本。此外,我们采用了多教师蒸馏框架来提高无监督数据的检测性能。也就是说,我们使用可公开访问的数据集构建多个教师,并使用它们为AugCOLD分配软标签。软标签是从AugCOLD和多教师到学生网络(即最终的攻击性检测器)提取知识的桥梁。我们在多个公共测试集和我们精心设计的硬测试上进行了实验,证明我们的建议可以有效地提高攻击性语言检测器的泛化能力和鲁棒性。
期刊介绍:
Research serves as a global platform for academic exchange, collaboration, and technological advancements. This journal welcomes high-quality research contributions from any domain, with open arms to authors from around the globe.
Comprising fundamental research in the life and physical sciences, Research also highlights significant findings and issues in engineering and applied science. The journal proudly features original research articles, reviews, perspectives, and editorials, fostering a diverse and dynamic scholarly environment.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


