Koushik Chandra Howlader, Md Shahriare Satu, Md Abdul Awal, Md Rabiul Islam, Sheikh Mohammed Shariful Islam, Julian M W Quinn, Mohammad Ali Moni
{"title":"Machine learning models for classification and identification of significant attributes to detect type 2 diabetes.","authors":"Koushik Chandra Howlader, Md Shahriare Satu, Md Abdul Awal, Md Rabiul Islam, Sheikh Mohammed Shariful Islam, Julian M W Quinn, Mohammad Ali Moni","doi":"10.1007/s13755-021-00168-2","DOIUrl":null,"url":null,"abstract":"<p><p>Type 2 Diabetes (T2D) is a chronic disease characterized by abnormally high blood glucose levels due to insulin resistance and reduced pancreatic insulin production. The challenge of this work is to identify T2D-associated features that can distinguish T2D sub-types for prognosis and treatment purposes. We thus employed machine learning (ML) techniques to categorize T2D patients using data from the Pima Indian Diabetes Dataset from the Kaggle ML repository. After data preprocessing, several feature selection techniques were used to extract feature subsets, and a range of classification techniques were used to analyze these. We then compared the derived classification results to identify the best classifiers by considering accuracy, kappa statistics, area under the receiver operating characteristic (AUROC), sensitivity, specificity, and logarithmic loss (logloss). To evaluate the performance of different classifiers, we investigated their outcomes using the summary statistics with a resampling distribution. Therefore, Generalized Boosted Regression modeling showed the highest accuracy (90.91%), followed by kappa statistics (78.77%) and specificity (85.19%). In addition, Sparse Distance Weighted Discrimination, Generalized Additive Model using LOESS and Boosted Generalized Additive Models also gave the maximum sensitivity (100%), highest AUROC (95.26%) and lowest logarithmic loss (30.98%) respectively. Notably, the Generalized Additive Model using LOESS was the top-ranked algorithm according to non-parametric Friedman testing. Of the features identified by these machine learning models, glucose levels, body mass index, diabetes pedigree function, and age were consistently identified as the best and most frequently accurate outcome predictors. These results indicate the utility of ML methods in constructing improved prediction models for T2D and successfully identified outcome predictors for this Pima Indian population.</p><p><strong>Supplementary information: </strong>The online version contains supplementary material available at 10.1007/s13755-021-00168-2.</p>","PeriodicalId":46312,"journal":{"name":"Health Information Science and Systems","volume":" ","pages":"2"},"PeriodicalIF":3.4000,"publicationDate":"2022-02-09","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC8828812/pdf/","citationCount":"26","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Health Information Science and Systems","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1007/s13755-021-00168-2","RegionNum":3,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2022/12/1 0:00:00","PubModel":"eCollection","JCR":"Q1","JCRName":"MEDICAL INFORMATICS","Score":null,"Total":0}
引用次数: 26
Abstract
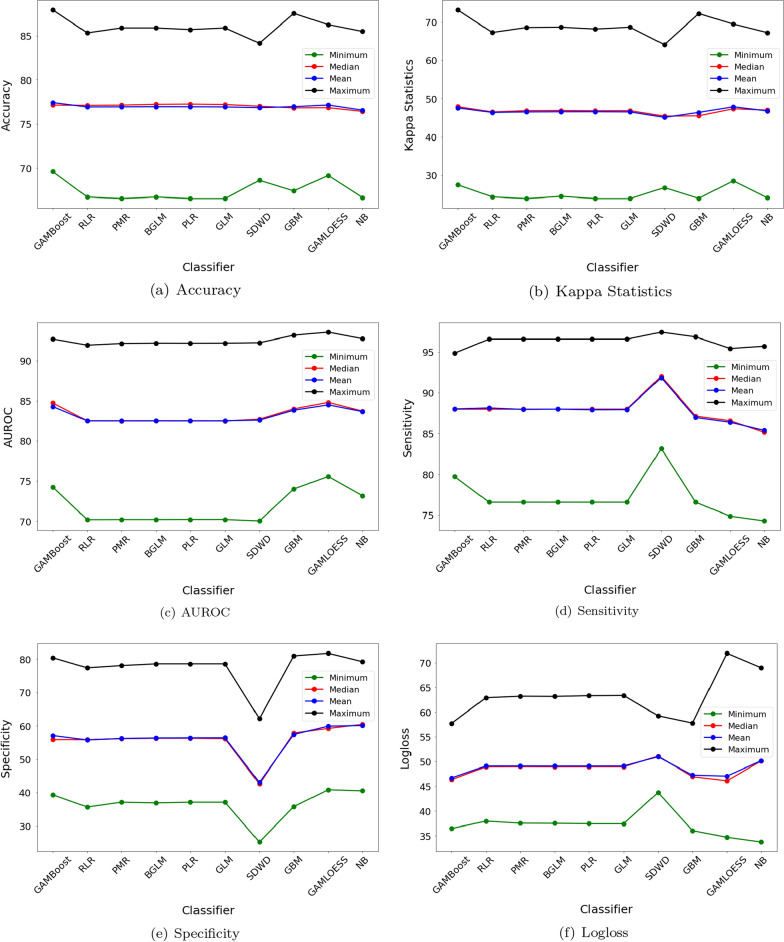
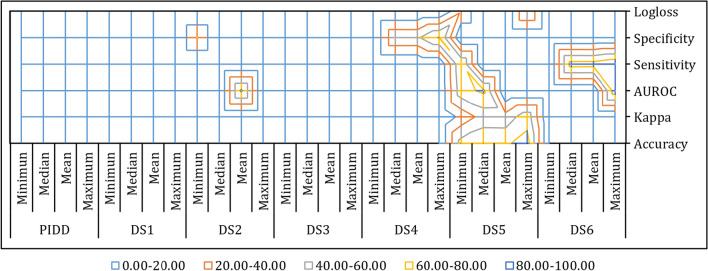
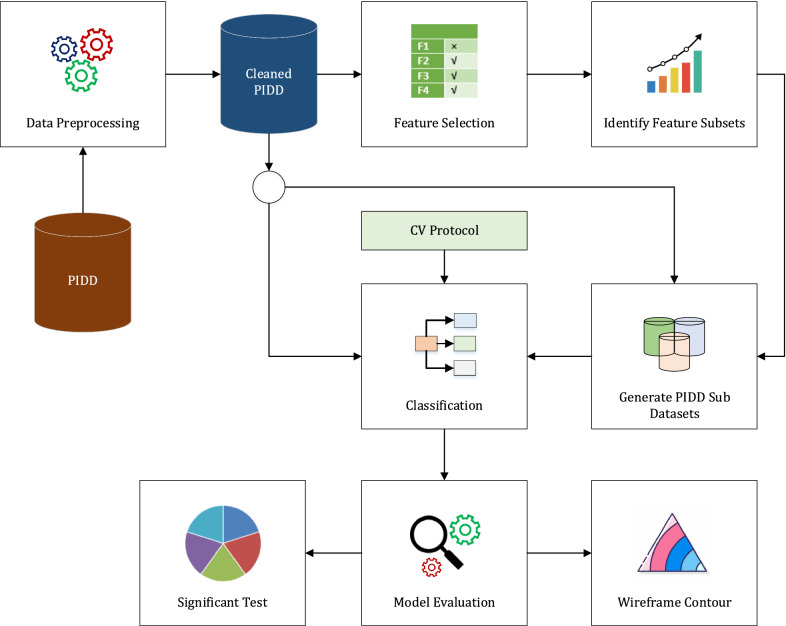
Type 2 Diabetes (T2D) is a chronic disease characterized by abnormally high blood glucose levels due to insulin resistance and reduced pancreatic insulin production. The challenge of this work is to identify T2D-associated features that can distinguish T2D sub-types for prognosis and treatment purposes. We thus employed machine learning (ML) techniques to categorize T2D patients using data from the Pima Indian Diabetes Dataset from the Kaggle ML repository. After data preprocessing, several feature selection techniques were used to extract feature subsets, and a range of classification techniques were used to analyze these. We then compared the derived classification results to identify the best classifiers by considering accuracy, kappa statistics, area under the receiver operating characteristic (AUROC), sensitivity, specificity, and logarithmic loss (logloss). To evaluate the performance of different classifiers, we investigated their outcomes using the summary statistics with a resampling distribution. Therefore, Generalized Boosted Regression modeling showed the highest accuracy (90.91%), followed by kappa statistics (78.77%) and specificity (85.19%). In addition, Sparse Distance Weighted Discrimination, Generalized Additive Model using LOESS and Boosted Generalized Additive Models also gave the maximum sensitivity (100%), highest AUROC (95.26%) and lowest logarithmic loss (30.98%) respectively. Notably, the Generalized Additive Model using LOESS was the top-ranked algorithm according to non-parametric Friedman testing. Of the features identified by these machine learning models, glucose levels, body mass index, diabetes pedigree function, and age were consistently identified as the best and most frequently accurate outcome predictors. These results indicate the utility of ML methods in constructing improved prediction models for T2D and successfully identified outcome predictors for this Pima Indian population.
Supplementary information: The online version contains supplementary material available at 10.1007/s13755-021-00168-2.
期刊介绍:
Health Information Science and Systems is a multidisciplinary journal that integrates artificial intelligence/computer science/information technology with health science and services, embracing information science research coupled with topics related to the modeling, design, development, integration and management of health information systems, smart health, artificial intelligence in medicine, and computer aided diagnosis, medical expert systems. The scope includes: i.) smart health, artificial Intelligence in medicine, computer aided diagnosis, medical image processing, medical expert systems ii.) medical big data, medical/health/biomedicine information resources such as patient medical records, devices and equipments, software and tools to capture, store, retrieve, process, analyze, optimize the use of information in the health domain, iii.) data management, data mining, and knowledge discovery, all of which play a key role in decision making, management of public health, examination of standards, privacy and security issues, iv.) development of new architectures and applications for health information systems.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


