{"title":"How to Use Model-Based Cluster Analysis Efficiently in Person-Oriented Research.","authors":"Bence Gergely, András Vargha","doi":"10.17505/jpor.2021.23449","DOIUrl":null,"url":null,"abstract":"<p><p>Model-based cluster analysis (MBCA) was created to automatize the often subjective model-selection procedure of traditional explorative clustering methods. It is a type of finite mixture modelling, assuming that the data come from a mixture of different subpopulations following given distributions, typically multivariate normal. In that case cluster analysis is the exploration of the underlying mixture structure. In MBCA finding the possible number of clusters and the best clustering model is a statistical model-selection problem, where the models with differing number and type of component distributions are compared. For fitting a certain model MBCA uses a likelihood based Bayesian Information Criterion (BIC) to evaluate its appropriateness and the model with the highest BIC value is accepted as the final solution. The aim of the present study is to investigate the adequacy of automatic model selection in MBCA using BIC, and suggested alternative methods, like the Integrated Completed Likelihood Criterion (ICL), or Baudry's method. An additional aim is to refine these procedures by using so called quality coefficients (QCs), borrowed from methodological advances within the field of exploratory cluster analysis, to help in the choice of an appropriate cluster structure (CLS), and also to compare the efficiency of MBCA in identifying a theoretical CLS with those of various other clustering methods. The analyses are restricted to studying the performance of various procedures of the type described above for two classification situations, typical in person-oriented studies: (1) an example data set characterized by a perfect theoretical CLS with seven types (seven completely homogeneous clusters) was used to generate three data sets with varying degrees of measurement error added to the original values, and (2) three additional data sets based on another perfect theoretical CLS with four types. It was found that the automatic decision rarely led to an optimal solution. However, dropping solutions with irregular BIC curves, and using different QCs as an aid in choosing between different solutions generated by MBCA and by fusing close clusters, optimal solutions were achieved for the two classification situations studied. With this refined procedure the revealed cluster solutions of MBCA often proved to be at least as good as those of different hierarchical and <i>k</i>-center clustering methods. MBCA was definitely superior in identifying four-type CLS models. In identifying seven-type CLS models MBCA performed at a similar level as the best of other clustering methods (such as <i>k</i>-means) only when the reliability level of the input variables was high or moderate, otherwise it was slightly less efficient.</p>","PeriodicalId":36744,"journal":{"name":"Journal for Person-Oriented Research","volume":"7 1","pages":"22-35"},"PeriodicalIF":0.0000,"publicationDate":"2021-08-26","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC8411881/pdf/","citationCount":"1","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal for Person-Oriented Research","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.17505/jpor.2021.23449","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2021/1/1 0:00:00","PubModel":"eCollection","JCR":"Q2","JCRName":"Psychology","Score":null,"Total":0}
引用次数: 1
Abstract
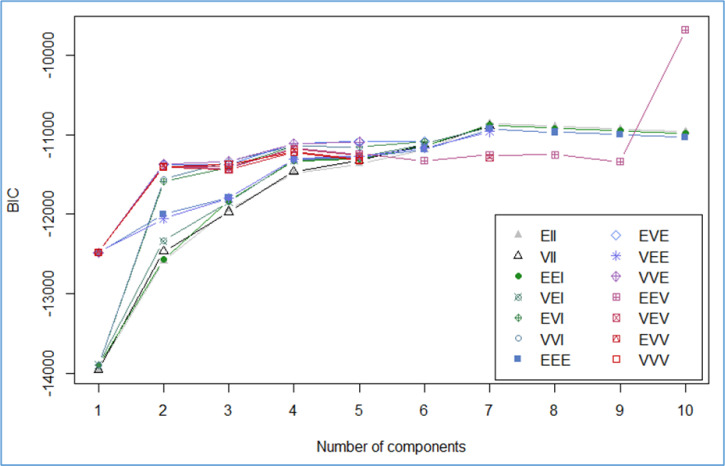
Model-based cluster analysis (MBCA) was created to automatize the often subjective model-selection procedure of traditional explorative clustering methods. It is a type of finite mixture modelling, assuming that the data come from a mixture of different subpopulations following given distributions, typically multivariate normal. In that case cluster analysis is the exploration of the underlying mixture structure. In MBCA finding the possible number of clusters and the best clustering model is a statistical model-selection problem, where the models with differing number and type of component distributions are compared. For fitting a certain model MBCA uses a likelihood based Bayesian Information Criterion (BIC) to evaluate its appropriateness and the model with the highest BIC value is accepted as the final solution. The aim of the present study is to investigate the adequacy of automatic model selection in MBCA using BIC, and suggested alternative methods, like the Integrated Completed Likelihood Criterion (ICL), or Baudry's method. An additional aim is to refine these procedures by using so called quality coefficients (QCs), borrowed from methodological advances within the field of exploratory cluster analysis, to help in the choice of an appropriate cluster structure (CLS), and also to compare the efficiency of MBCA in identifying a theoretical CLS with those of various other clustering methods. The analyses are restricted to studying the performance of various procedures of the type described above for two classification situations, typical in person-oriented studies: (1) an example data set characterized by a perfect theoretical CLS with seven types (seven completely homogeneous clusters) was used to generate three data sets with varying degrees of measurement error added to the original values, and (2) three additional data sets based on another perfect theoretical CLS with four types. It was found that the automatic decision rarely led to an optimal solution. However, dropping solutions with irregular BIC curves, and using different QCs as an aid in choosing between different solutions generated by MBCA and by fusing close clusters, optimal solutions were achieved for the two classification situations studied. With this refined procedure the revealed cluster solutions of MBCA often proved to be at least as good as those of different hierarchical and k-center clustering methods. MBCA was definitely superior in identifying four-type CLS models. In identifying seven-type CLS models MBCA performed at a similar level as the best of other clustering methods (such as k-means) only when the reliability level of the input variables was high or moderate, otherwise it was slightly less efficient.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


